new file: compare-chose-deploy.ipynb new file: datasets/winequality-white.csv modified: logging-first-model.ipynb
9.5 KiB
MLflow 的自动记录¶
在这个快速入门中,您将了解 MLflow 中的自动日志记录功能,以简化模型、指标和参数的日志记录。训练并查看记录的运行数据后,我们将加载记录的模型来执行推理,以尽可能最省时的方式显示 MLflow Tracking 的核心功能。
安装 MLflow
在代码中添加 MLflow 跟踪服务
在 MLflow web UI 中查看实验与运行结果
通过跟踪服务与别人分享你的实验数据
保存实验生成的模型
加载模型用于推理
作为一名数据科学家,模型往往需要经过多次的实验、迭代。 MLflow Tracking 可以记录模型训练中的重要信息、训练版本进行对比,以及与其他人分享结果。便于 ML 工程师或 MLOps 人员,比较、共享和部署生成的最佳模型。
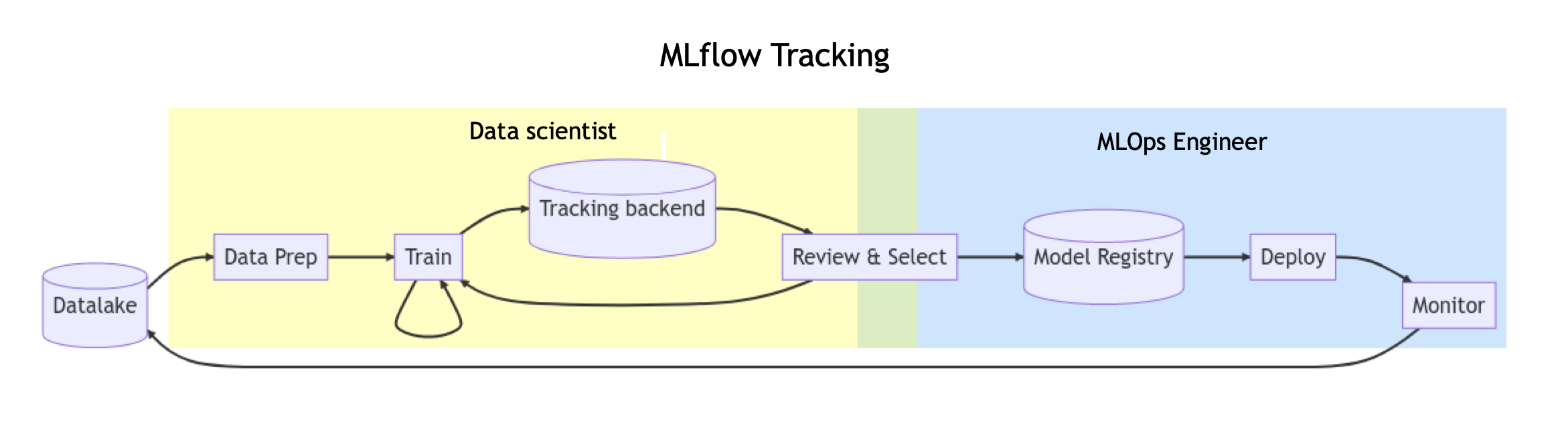
在代码中添加 MLflow 自动跟踪¶
对于许多流行的 ML 库,您只需调用一个函数:mlflow.autolog()。如果您使用的是受支持的库之一,mlflow 自动记录运行的参数、指标等信息。
支持的机器学习库:
Fastai
Gluon
Keras
LightGBM
PyTorch
Scikit-learn
Spark
Statsmodels
XGBoost
例如,以下自动记录 scikit-learn 运行:
import mlflow from sklearn.model_selection import train_test_split from sklearn.datasets import load_diabetes from sklearn.ensemble import RandomForestRegressor mlflow.autolog() db = load_diabetes() X_train, X_test, y_train, y_test = train_test_split(db.data, db.target) # Create and train models. rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3) rf.fit(X_train, y_train) # Use the model to make predictions on the test dataset. predictions = rf.predict(X_test)
2024/01/21 16:08:10 WARNING mlflow.utils.autologging_utils: You are using an unsupported version of sklearn. If you encounter errors during autologging, try upgrading / downgrading sklearn to a supported version, or try upgrading MLflow. 2024/01/21 16:08:10 INFO mlflow.tracking.fluent: Autologging successfully enabled for sklearn. 2024/01/21 16:08:10 INFO mlflow.utils.autologging_utils: Created MLflow autologging run with ID 'd79193a0d0bf40509f6de578ed3e6cfa', which will track hyperparameters, performance metrics, model artifacts, and lineage information for the current sklearn workflow
如果使用的是不受支持的机器学习库则需要自己手动记录相关数据
也可以在开始自动记录数据之前配置用于记录的 MLflow 服务,再不配置的情况下会默认将数据记录在当前文件夹,运行 mlfow ui 时会加载当前文件夹下记录的数据。
mlflow.set_tracking_uri("http://127.0.0.1:8080") mlflow.autolog() # Or other tracking functions
保存模型¶
MLflow 模型是一个以标准格式打包的机器学习模型目录。该目录包含:
YAML 格式的 MLModel 文件,指定模型的格式、依赖项、签名(如果有)和重要元数据;
模型格式实例化模型所需的各种文件。通常是一个序列化的 Python 对象;
模型运行所需的环境配置文件(例如 conda.yaml requirements.txt 文件);
输入示例(输入示例)
使用自动记录时,MLflow 将自动记录代码中创建的任何模型。您还可以通过调用 mlflow.{library_module_name}.log_model 手动记录模型。此外,如果想要将运行的 ID 直接输出到控制台需要获取 mlflow.ActiveRun 类型的对象。您可以通过将所有日志记录代码包装在 with mlflow.start_run() as run: 块中来获取运行时对象。
import mlflow from mlflow.models import infer_signature from sklearn.model_selection import train_test_split from sklearn.datasets import load_diabetes from sklearn.ensemble import RandomForestRegressor with mlflow.start_run() as run: # Load the diabetes dataset. db = load_diabetes() X_train, X_test, y_train, y_test = train_test_split(db.data, db.target) # Create and train models. rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3) rf.fit(X_train, y_train) # Use the model to make predictions on the test dataset. predictions = rf.predict(X_test) print(predictions) signature = infer_signature(X_test, predictions) mlflow.sklearn.log_model(rf, "model", signature=signature) print(f"Run ID: {run.info.run_id}")
对于 sklearn 格式的模型,log_model 将以下文件存储在跟踪服务器上对应的 artifacts 目录中:
model/
|-- MLmodel
|-- conda.yaml
|-- model.pkl
|-- python_env.yaml
|-- requirements.txt
在没有调用 set_tracking_uri 设置跟踪服务器的情况下, 相关模型以及数据会被记录在当前目录下的 mlruns 目录中。
从指定的训练记录中加载模型用于推理¶
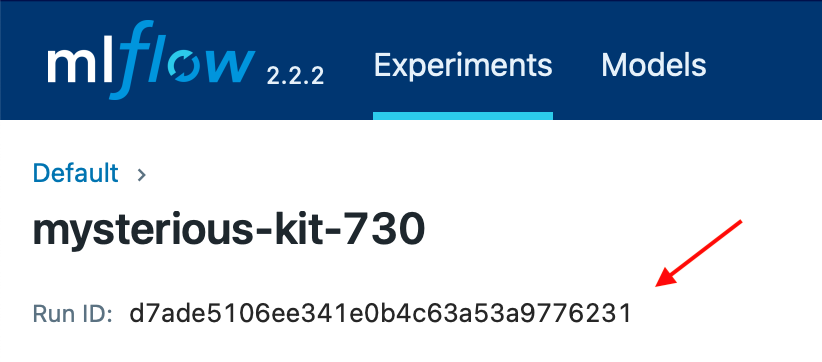
要加载并运行先前训练中存储的模型,您可以使用 mlflow.{library_module_name}.load_model 函数通过训练 ID 加载模型。您可以在 Web UI 中找到运行 ID:
在 Web UI 中其实直接提供了每个模型的加载使用示例:
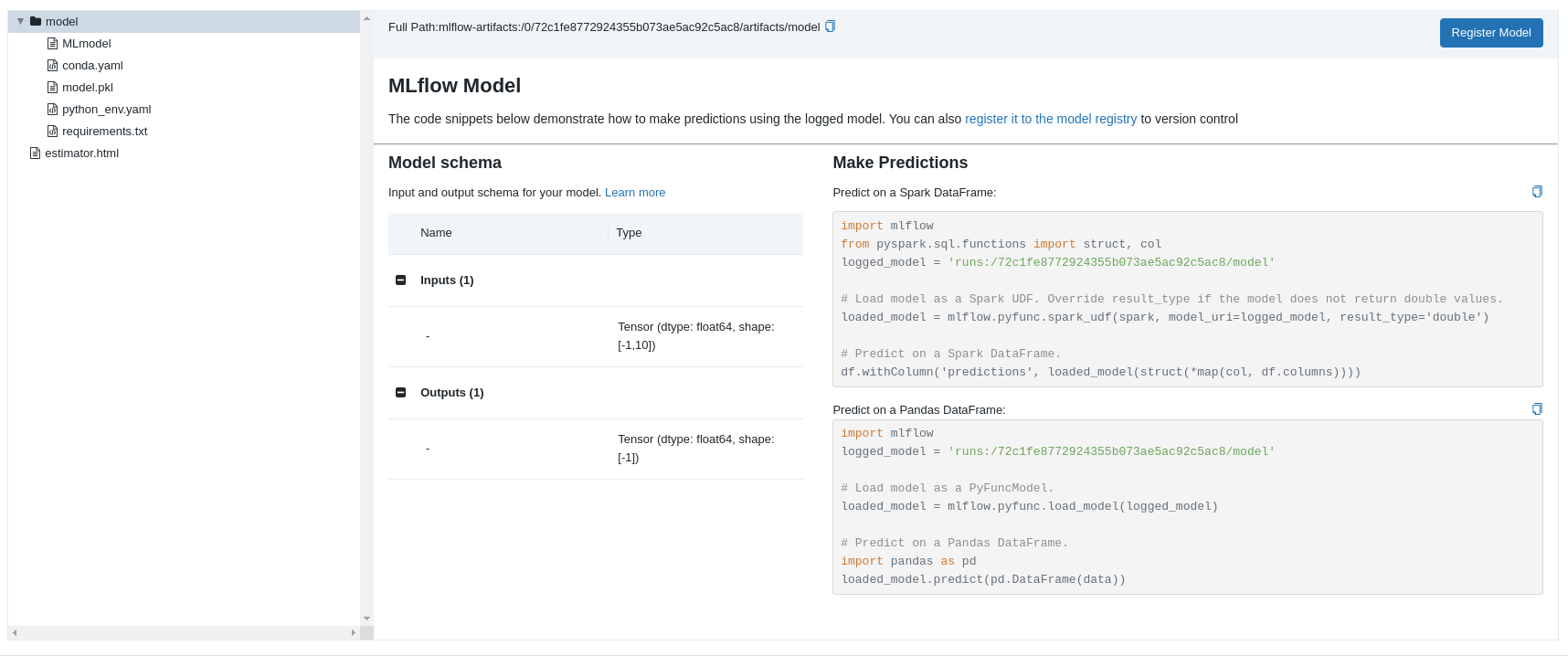
import mlflow from sklearn.model_selection import train_test_split from sklearn.datasets import load_diabetes db = load_diabetes() X_train, X_test, y_train, y_test = train_test_split(db.data, db.target) model = mlflow.sklearn.load_model("runs:/d7ade5106ee341e0b4c63a53a9776231") predictions = model.predict(X_test) print(predictions)
请注意,虽然 log_model 会自动保存模型运行所需的环境文件(例如 conda.yaml 和requirements.txt),但 load_model 不会自动重新创建该环境。因此在新环境中加载模型时,需要先使用包管理器(conda、virtualenv、pip 等)安装对应的环境。
如果您使用 mlflow modelsserve 来运行您的模型,MLflow 将自动重新创建环境。这些命令还接受 --env-manager 等选项以进行更精细的控制。此文档进行了详细描述。
对于 mlflow.pyfunc.spark_udf(),您可以使用 --env-manager 标志在 Spark 批量推理期间重新创建环境。