new file: autologging-in-mlflow.ipynb
new file: compare-chose-deploy.ipynb new file: datasets/winequality-white.csv modified: logging-first-model.ipynb
This commit is contained in:
parent
63c2320221
commit
dcdc62113e
281
autologging-in-mlflow.ipynb
Normal file
281
autologging-in-mlflow.ipynb
Normal file
@ -0,0 +1,281 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# MLflow 的自动记录\n",
|
||||
"\n",
|
||||
"在这个快速入门中,您将了解 MLflow 中的自动日志记录功能,以简化模型、指标和参数的日志记录。训练并查看记录的运行数据后,我们将加载记录的模型来执行推理,以尽可能最省时的方式显示 MLflow Tracking 的核心功能。\n",
|
||||
"\n",
|
||||
"- 安装 MLflow\n",
|
||||
"\n",
|
||||
"- 在代码中添加 MLflow 跟踪服务\n",
|
||||
"\n",
|
||||
"- 在 MLflow web UI 中查看实验与运行结果\n",
|
||||
"\n",
|
||||
"- 通过跟踪服务与别人分享你的实验数据\n",
|
||||
"\n",
|
||||
"- 保存实验生成的模型\n",
|
||||
"\n",
|
||||
"- 加载模型用于推理\n",
|
||||
"\n",
|
||||
"作为一名数据科学家,模型往往需要经过多次的实验、迭代。 MLflow Tracking 可以记录模型训练中的重要信息、训练版本进行对比,以及与其他人分享结果。便于 ML 工程师或 MLOps 人员,比较、共享和部署生成的最佳模型。\n",
|
||||
"\n",
|
||||
"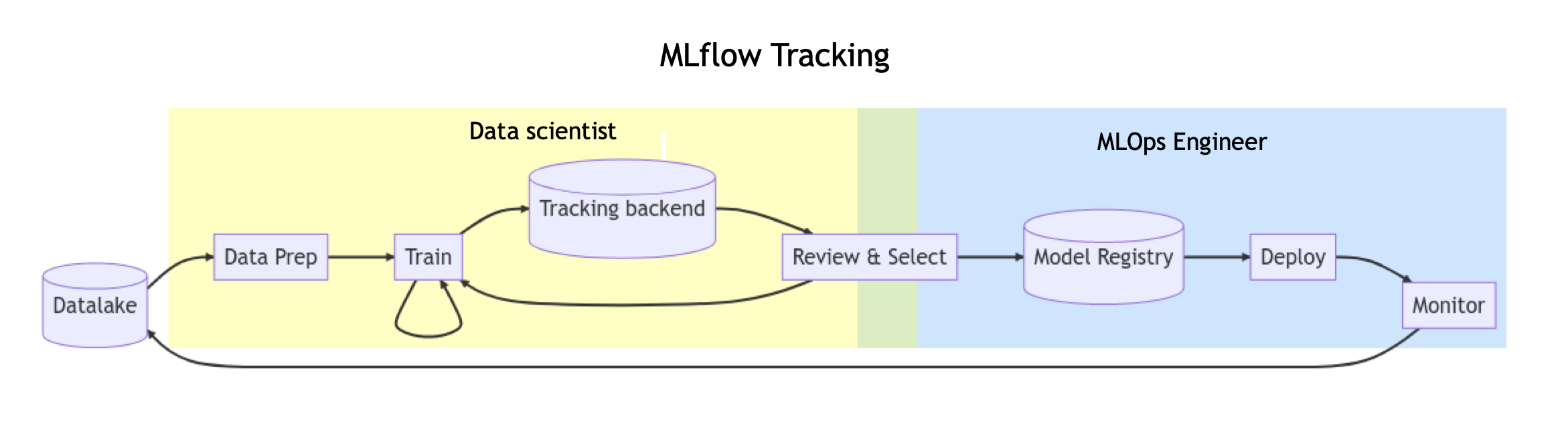\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 安装 MLflow\n",
|
||||
"\n",
|
||||
"可以使用 pip 直接进行安装:\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"pip install mlflow\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 在代码中添加 MLflow 自动跟踪\n",
|
||||
"\n",
|
||||
"对于许多流行的 ML 库,您只需调用一个函数:`mlflow.autolog()`。如果您使用的是受支持的库之一,mlflow 自动记录运行的参数、指标等信息。\n",
|
||||
"\n",
|
||||
"> 支持的机器学习库:\n",
|
||||
">\n",
|
||||
"> Fastai\n",
|
||||
"> \n",
|
||||
"> Gluon\n",
|
||||
"> \n",
|
||||
"> Keras\n",
|
||||
"> \n",
|
||||
"> LightGBM\n",
|
||||
"> \n",
|
||||
"> PyTorch\n",
|
||||
"> \n",
|
||||
"> Scikit-learn\n",
|
||||
"> \n",
|
||||
"> Spark\n",
|
||||
"> \n",
|
||||
"> Statsmodels\n",
|
||||
"> \n",
|
||||
"> XGBoost\n",
|
||||
"\n",
|
||||
"例如,以下自动记录 scikit-learn 运行:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"2024/01/21 16:08:10 WARNING mlflow.utils.autologging_utils: You are using an unsupported version of sklearn. If you encounter errors during autologging, try upgrading / downgrading sklearn to a supported version, or try upgrading MLflow.\n",
|
||||
"2024/01/21 16:08:10 INFO mlflow.tracking.fluent: Autologging successfully enabled for sklearn.\n",
|
||||
"2024/01/21 16:08:10 INFO mlflow.utils.autologging_utils: Created MLflow autologging run with ID 'd79193a0d0bf40509f6de578ed3e6cfa', which will track hyperparameters, performance metrics, model artifacts, and lineage information for the current sklearn workflow\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import mlflow\n",
|
||||
"\n",
|
||||
"from sklearn.model_selection import train_test_split\n",
|
||||
"from sklearn.datasets import load_diabetes\n",
|
||||
"from sklearn.ensemble import RandomForestRegressor\n",
|
||||
"\n",
|
||||
"mlflow.autolog()\n",
|
||||
"\n",
|
||||
"db = load_diabetes()\n",
|
||||
"X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)\n",
|
||||
"\n",
|
||||
"# Create and train models.\n",
|
||||
"rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)\n",
|
||||
"rf.fit(X_train, y_train)\n",
|
||||
"\n",
|
||||
"# Use the model to make predictions on the test dataset.\n",
|
||||
"predictions = rf.predict(X_test)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"> 如果使用的是不受支持的机器学习库则需要自己手动记录相关数据"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 查看 MLflow 的实验与运行结果\n",
|
||||
"\n",
|
||||
"运行完你的代码后便可以在 mlflow ui 中查看结果\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"mlflow ui\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"> 也可以在开始自动记录数据之前配置用于记录的 MLflow 服务,再不配置的情况下会默认将数据记录在当前文件夹,运行 mlfow ui 时会加载当前文件夹下记录的数据。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"mlflow.set_tracking_uri(\"http://127.0.0.1:8080\")\n",
|
||||
"mlflow.autolog() # Or other tracking functions"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 保存模型\n",
|
||||
"\n",
|
||||
"MLflow 模型是一个以标准格式打包的机器学习模型目录。该目录包含:\n",
|
||||
"\n",
|
||||
"- YAML 格式的 MLModel 文件,指定模型的格式、依赖项、签名(如果有)和重要元数据;\n",
|
||||
"\n",
|
||||
"- 模型格式实例化模型所需的各种文件。通常是一个序列化的 Python 对象;\n",
|
||||
"\n",
|
||||
"- 模型运行所需的环境配置文件(例如 conda.yaml requirements.txt 文件);\n",
|
||||
"\n",
|
||||
"- 输入示例(输入示例)\n",
|
||||
"\n",
|
||||
"使用自动记录时,MLflow 将自动记录代码中创建的任何模型。您还可以通过调用 mlflow.{library_module_name}.log_model 手动记录模型。此外,如果想要将运行的 ID 直接输出到控制台需要获取 mlflow.ActiveRun 类型的对象。您可以通过将所有日志记录代码包装在 with mlflow.start_run() as run: 块中来获取运行时对象。 "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import mlflow\n",
|
||||
"from mlflow.models import infer_signature\n",
|
||||
"\n",
|
||||
"from sklearn.model_selection import train_test_split\n",
|
||||
"from sklearn.datasets import load_diabetes\n",
|
||||
"from sklearn.ensemble import RandomForestRegressor\n",
|
||||
"\n",
|
||||
"with mlflow.start_run() as run:\n",
|
||||
" # Load the diabetes dataset.\n",
|
||||
" db = load_diabetes()\n",
|
||||
" X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)\n",
|
||||
"\n",
|
||||
" # Create and train models.\n",
|
||||
" rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)\n",
|
||||
" rf.fit(X_train, y_train)\n",
|
||||
"\n",
|
||||
" # Use the model to make predictions on the test dataset.\n",
|
||||
" predictions = rf.predict(X_test)\n",
|
||||
" print(predictions)\n",
|
||||
"\n",
|
||||
" signature = infer_signature(X_test, predictions)\n",
|
||||
" mlflow.sklearn.log_model(rf, \"model\", signature=signature)\n",
|
||||
"\n",
|
||||
" print(f\"Run ID: {run.info.run_id}\")\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"对于 sklearn 格式的模型,log_model 将以下文件存储在跟踪服务器上对应的 artifacts 目录中:\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"model/\n",
|
||||
"|-- MLmodel\n",
|
||||
"|-- conda.yaml\n",
|
||||
"|-- model.pkl\n",
|
||||
"|-- python_env.yaml\n",
|
||||
"|-- requirements.txt\n",
|
||||
"\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"在没有调用 `set_tracking_uri` 设置跟踪服务器的情况下, 相关模型以及数据会被记录在当前目录下的 mlruns 目录中。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 从指定的训练记录中加载模型用于推理\n",
|
||||
"\n",
|
||||
"要加载并运行先前训练中存储的模型,您可以使用 mlflow.{library_module_name}.load_model 函数通过训练 ID 加载模型。您可以在 Web UI 中找到运行 ID:\n",
|
||||
"\n",
|
||||
"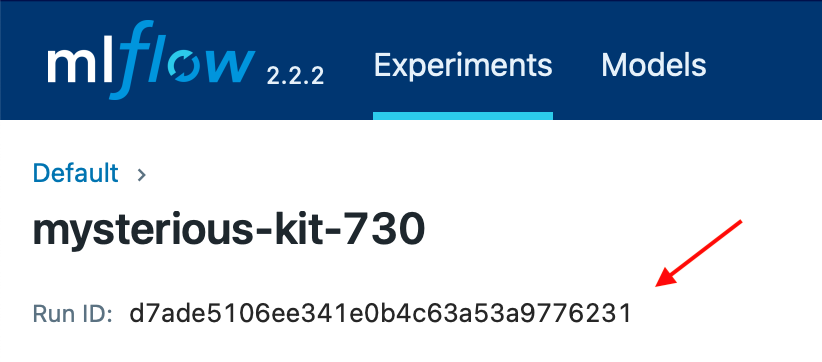\n",
|
||||
"\n",
|
||||
"在 Web UI 中其实直接提供了每个模型的加载使用示例:\n",
|
||||
"\n",
|
||||
"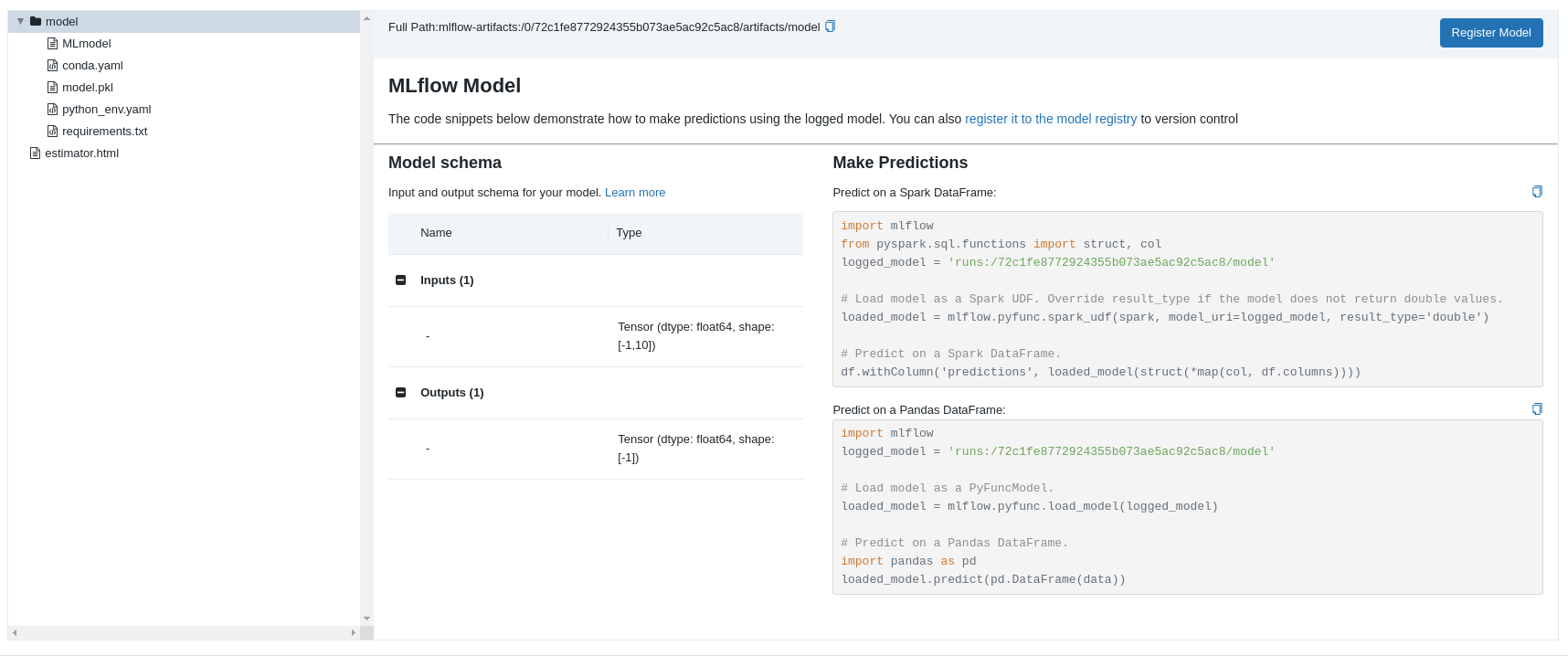"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import mlflow\n",
|
||||
"\n",
|
||||
"from sklearn.model_selection import train_test_split\n",
|
||||
"from sklearn.datasets import load_diabetes\n",
|
||||
"\n",
|
||||
"db = load_diabetes()\n",
|
||||
"X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)\n",
|
||||
"\n",
|
||||
"model = mlflow.sklearn.load_model(\"runs:/d7ade5106ee341e0b4c63a53a9776231\")\n",
|
||||
"predictions = model.predict(X_test)\n",
|
||||
"print(predictions)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"请注意,虽然 `log_model` 会自动保存模型运行所需的环境文件(例如 conda.yaml 和requirements.txt),但 load_model 不会自动重新创建该环境。因此在新环境中加载模型时,需要先使用包管理器(conda、virtualenv、pip 等)安装对应的环境。\n",
|
||||
"\n",
|
||||
"如果您使用 `mlflow modelsserve` 来运行您的模型,MLflow 将自动重新创建环境。这些命令还接受 --env-manager 等选项以进行更精细的控制。[此文档](https://mlflow.org/docs/latest/models.html#model-enviroment-management)进行了详细描述。\n",
|
||||
"\n",
|
||||
"对于 `mlflow.pyfunc.spark_udf()`,您可以使用 --env-manager 标志在 Spark 批量推理期间重新创建环境。"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "mlflow",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
553
compare-chose-deploy.ipynb
Normal file
553
compare-chose-deploy.ipynb
Normal file
@ -0,0 +1,553 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# 对比、选择、部署模型\n",
|
||||
"\n",
|
||||
"在本笔记中,您将:\n",
|
||||
"\n",
|
||||
"- 对训练脚本运行超参数扫描\n",
|
||||
"\n",
|
||||
"- 比较 MLflow UI 中的运行结果\n",
|
||||
"\n",
|
||||
"- 选择最佳运行并将其注册为模型\n",
|
||||
"\n",
|
||||
"- 将模型部署到 REST API\n",
|
||||
"\n",
|
||||
"- 构建适合部署到云平台的容器镜像\n",
|
||||
"\n",
|
||||
"作为 ML 工程师或 MLOps 专业人员,您可以使用 MLflow 来比较、共享和部署团队生成的最佳模型。在本笔记中,您将使用 MLflow Web UI 来比较超参数扫描的结果,选择最佳迭代并将其注册为模型。然后,您将模型部署到 REST API。最后,将模型打包为 Docker 容器映像进行部署。\n",
|
||||
"\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 准备工作\n",
|
||||
"\n",
|
||||
"安装并启动一个 MLflow 跟踪服务。\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"pip install mlflow\n",
|
||||
"mlflow server --host 127.0.0.1 --port 8080\n",
|
||||
"```"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 运行超参扫描\n",
|
||||
"\n",
|
||||
"此示例尝试在葡萄酒质量数据集上优化 Keras 深度学习模型的 RMSE 指标。它有两个试图优化的超参数:`学习率`和`动量`。我们将使用 Hyperopt 库对学习率和动量的不同值运行超参数扫描,并将结果记录在 MLflow 中。\n",
|
||||
"\n",
|
||||
"在运行超参数扫描之前,我们先设置我们的跟踪记录服务:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from tensorflow import keras\n",
|
||||
"import numpy as np\n",
|
||||
"import pandas as pd\n",
|
||||
"from hyperopt import STATUS_OK, Trials, fmin, hp, tpe\n",
|
||||
"from sklearn.metrics import mean_squared_error\n",
|
||||
"from sklearn.model_selection import train_test_split\n",
|
||||
"\n",
|
||||
"import mlflow\n",
|
||||
"from mlflow.models import infer_signature\n",
|
||||
"\n",
|
||||
"mlflow.set_tracking_uri(uri=\"http://127.0.0.1:8080\")\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"然后加载数据,并区分出训练集、验证集和测试集:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>fixed acidity</th>\n",
|
||||
" <th>volatile acidity</th>\n",
|
||||
" <th>citric acid</th>\n",
|
||||
" <th>residual sugar</th>\n",
|
||||
" <th>chlorides</th>\n",
|
||||
" <th>free sulfur dioxide</th>\n",
|
||||
" <th>total sulfur dioxide</th>\n",
|
||||
" <th>density</th>\n",
|
||||
" <th>pH</th>\n",
|
||||
" <th>sulphates</th>\n",
|
||||
" <th>alcohol</th>\n",
|
||||
" <th>quality</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>1685</th>\n",
|
||||
" <td>7.2</td>\n",
|
||||
" <td>0.25</td>\n",
|
||||
" <td>0.28</td>\n",
|
||||
" <td>14.40</td>\n",
|
||||
" <td>0.055</td>\n",
|
||||
" <td>55.0</td>\n",
|
||||
" <td>205.0</td>\n",
|
||||
" <td>0.99860</td>\n",
|
||||
" <td>3.12</td>\n",
|
||||
" <td>0.38</td>\n",
|
||||
" <td>9.0</td>\n",
|
||||
" <td>7</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>130</th>\n",
|
||||
" <td>5.7</td>\n",
|
||||
" <td>0.26</td>\n",
|
||||
" <td>0.25</td>\n",
|
||||
" <td>10.40</td>\n",
|
||||
" <td>0.020</td>\n",
|
||||
" <td>7.0</td>\n",
|
||||
" <td>57.0</td>\n",
|
||||
" <td>0.99400</td>\n",
|
||||
" <td>3.39</td>\n",
|
||||
" <td>0.37</td>\n",
|
||||
" <td>10.6</td>\n",
|
||||
" <td>5</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2919</th>\n",
|
||||
" <td>6.4</td>\n",
|
||||
" <td>0.16</td>\n",
|
||||
" <td>0.32</td>\n",
|
||||
" <td>8.75</td>\n",
|
||||
" <td>0.038</td>\n",
|
||||
" <td>38.0</td>\n",
|
||||
" <td>118.0</td>\n",
|
||||
" <td>0.99449</td>\n",
|
||||
" <td>3.19</td>\n",
|
||||
" <td>0.41</td>\n",
|
||||
" <td>10.7</td>\n",
|
||||
" <td>5</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3171</th>\n",
|
||||
" <td>7.3</td>\n",
|
||||
" <td>0.20</td>\n",
|
||||
" <td>0.39</td>\n",
|
||||
" <td>2.30</td>\n",
|
||||
" <td>0.048</td>\n",
|
||||
" <td>24.0</td>\n",
|
||||
" <td>87.0</td>\n",
|
||||
" <td>0.99044</td>\n",
|
||||
" <td>2.94</td>\n",
|
||||
" <td>0.35</td>\n",
|
||||
" <td>12.0</td>\n",
|
||||
" <td>6</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3444</th>\n",
|
||||
" <td>6.7</td>\n",
|
||||
" <td>0.30</td>\n",
|
||||
" <td>0.44</td>\n",
|
||||
" <td>18.75</td>\n",
|
||||
" <td>0.057</td>\n",
|
||||
" <td>65.0</td>\n",
|
||||
" <td>224.0</td>\n",
|
||||
" <td>0.99956</td>\n",
|
||||
" <td>3.11</td>\n",
|
||||
" <td>0.53</td>\n",
|
||||
" <td>9.1</td>\n",
|
||||
" <td>5</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4426</th>\n",
|
||||
" <td>6.2</td>\n",
|
||||
" <td>0.21</td>\n",
|
||||
" <td>0.52</td>\n",
|
||||
" <td>6.50</td>\n",
|
||||
" <td>0.047</td>\n",
|
||||
" <td>28.0</td>\n",
|
||||
" <td>123.0</td>\n",
|
||||
" <td>0.99418</td>\n",
|
||||
" <td>3.22</td>\n",
|
||||
" <td>0.49</td>\n",
|
||||
" <td>9.9</td>\n",
|
||||
" <td>6</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>466</th>\n",
|
||||
" <td>7.0</td>\n",
|
||||
" <td>0.14</td>\n",
|
||||
" <td>0.32</td>\n",
|
||||
" <td>9.00</td>\n",
|
||||
" <td>0.039</td>\n",
|
||||
" <td>54.0</td>\n",
|
||||
" <td>141.0</td>\n",
|
||||
" <td>0.99560</td>\n",
|
||||
" <td>3.22</td>\n",
|
||||
" <td>0.43</td>\n",
|
||||
" <td>9.4</td>\n",
|
||||
" <td>6</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3092</th>\n",
|
||||
" <td>7.6</td>\n",
|
||||
" <td>0.27</td>\n",
|
||||
" <td>0.52</td>\n",
|
||||
" <td>3.20</td>\n",
|
||||
" <td>0.043</td>\n",
|
||||
" <td>28.0</td>\n",
|
||||
" <td>152.0</td>\n",
|
||||
" <td>0.99129</td>\n",
|
||||
" <td>3.02</td>\n",
|
||||
" <td>0.53</td>\n",
|
||||
" <td>11.4</td>\n",
|
||||
" <td>6</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3772</th>\n",
|
||||
" <td>6.3</td>\n",
|
||||
" <td>0.24</td>\n",
|
||||
" <td>0.29</td>\n",
|
||||
" <td>13.70</td>\n",
|
||||
" <td>0.035</td>\n",
|
||||
" <td>53.0</td>\n",
|
||||
" <td>134.0</td>\n",
|
||||
" <td>0.99567</td>\n",
|
||||
" <td>3.17</td>\n",
|
||||
" <td>0.38</td>\n",
|
||||
" <td>10.6</td>\n",
|
||||
" <td>6</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>860</th>\n",
|
||||
" <td>8.1</td>\n",
|
||||
" <td>0.27</td>\n",
|
||||
" <td>0.35</td>\n",
|
||||
" <td>1.70</td>\n",
|
||||
" <td>0.030</td>\n",
|
||||
" <td>38.0</td>\n",
|
||||
" <td>103.0</td>\n",
|
||||
" <td>0.99255</td>\n",
|
||||
" <td>3.22</td>\n",
|
||||
" <td>0.63</td>\n",
|
||||
" <td>10.4</td>\n",
|
||||
" <td>8</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" fixed acidity volatile acidity citric acid residual sugar chlorides \\\n",
|
||||
"1685 7.2 0.25 0.28 14.40 0.055 \n",
|
||||
"130 5.7 0.26 0.25 10.40 0.020 \n",
|
||||
"2919 6.4 0.16 0.32 8.75 0.038 \n",
|
||||
"3171 7.3 0.20 0.39 2.30 0.048 \n",
|
||||
"3444 6.7 0.30 0.44 18.75 0.057 \n",
|
||||
"4426 6.2 0.21 0.52 6.50 0.047 \n",
|
||||
"466 7.0 0.14 0.32 9.00 0.039 \n",
|
||||
"3092 7.6 0.27 0.52 3.20 0.043 \n",
|
||||
"3772 6.3 0.24 0.29 13.70 0.035 \n",
|
||||
"860 8.1 0.27 0.35 1.70 0.030 \n",
|
||||
"\n",
|
||||
" free sulfur dioxide total sulfur dioxide density pH sulphates \\\n",
|
||||
"1685 55.0 205.0 0.99860 3.12 0.38 \n",
|
||||
"130 7.0 57.0 0.99400 3.39 0.37 \n",
|
||||
"2919 38.0 118.0 0.99449 3.19 0.41 \n",
|
||||
"3171 24.0 87.0 0.99044 2.94 0.35 \n",
|
||||
"3444 65.0 224.0 0.99956 3.11 0.53 \n",
|
||||
"4426 28.0 123.0 0.99418 3.22 0.49 \n",
|
||||
"466 54.0 141.0 0.99560 3.22 0.43 \n",
|
||||
"3092 28.0 152.0 0.99129 3.02 0.53 \n",
|
||||
"3772 53.0 134.0 0.99567 3.17 0.38 \n",
|
||||
"860 38.0 103.0 0.99255 3.22 0.63 \n",
|
||||
"\n",
|
||||
" alcohol quality \n",
|
||||
"1685 9.0 7 \n",
|
||||
"130 10.6 5 \n",
|
||||
"2919 10.7 5 \n",
|
||||
"3171 12.0 6 \n",
|
||||
"3444 9.1 5 \n",
|
||||
"4426 9.9 6 \n",
|
||||
"466 9.4 6 \n",
|
||||
"3092 11.4 6 \n",
|
||||
"3772 10.6 6 \n",
|
||||
"860 10.4 8 "
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Load dataset\n",
|
||||
"data = pd.read_csv(\n",
|
||||
" \"datasets/winequality-white.csv\",\n",
|
||||
" sep=\";\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Split the data into training, validation, and test sets\n",
|
||||
"train, test = train_test_split(data, test_size=0.25, random_state=42)\n",
|
||||
"train_x = train.drop([\"quality\"], axis=1).values\n",
|
||||
"train_y = train[[\"quality\"]].values.ravel()\n",
|
||||
"test_x = test.drop([\"quality\"], axis=1).values\n",
|
||||
"test_y = test[[\"quality\"]].values.ravel()\n",
|
||||
"train_x, valid_x, train_y, valid_y = train_test_split(\n",
|
||||
" train_x, train_y, test_size=0.2, random_state=42\n",
|
||||
")\n",
|
||||
"signature = infer_signature(train_x, train_y)\n",
|
||||
"\n",
|
||||
"train[-10:]\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"然后我们定义模型结构并训练模型。 `train_model` 函数使用 MLflow 来跟踪每个试验作为子运行的参数、结果和模型本身。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def train_model(params, epochs, train_x, train_y, valid_x, valid_y, test_x, test_y):\n",
|
||||
" # 定义模型结构\n",
|
||||
" model = keras.Sequential(\n",
|
||||
" [\n",
|
||||
" keras.Input([train_x.shape[1]]),\n",
|
||||
" keras.layers.Normalization(mean=np.mean(train_x), variance=np.var(train_x)),\n",
|
||||
" keras.layers.Dense(64, activation=\"relu\"),\n",
|
||||
" keras.layers.Dense(1),\n",
|
||||
" ]\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # 编译模型\n",
|
||||
" model.compile(\n",
|
||||
" optimizer=keras.optimizers.SGD(\n",
|
||||
" learning_rate=params[\"lr\"], momentum=params[\"momentum\"]\n",
|
||||
" ),\n",
|
||||
" loss=\"mean_squared_error\",\n",
|
||||
" metrics=[keras.metrics.RootMeanSquaredError()],\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # 训练模型并记录训练数据\n",
|
||||
" with mlflow.start_run(nested=True):\n",
|
||||
" model.fit(\n",
|
||||
" train_x,\n",
|
||||
" train_y,\n",
|
||||
" validation_data=(valid_x, valid_y),\n",
|
||||
" epochs=epochs,\n",
|
||||
" batch_size=64,\n",
|
||||
" )\n",
|
||||
" # Evaluate the model\n",
|
||||
" eval_result = model.evaluate(valid_x, valid_y, batch_size=64)\n",
|
||||
" eval_rmse = eval_result[1]\n",
|
||||
"\n",
|
||||
" # Log parameters and results\n",
|
||||
" mlflow.log_params(params)\n",
|
||||
" mlflow.log_metric(\"eval_rmse\", eval_rmse)\n",
|
||||
"\n",
|
||||
" # Log model\n",
|
||||
" mlflow.tensorflow.log_model(model, \"model\", signature=signature)\n",
|
||||
"\n",
|
||||
" return {\"loss\": eval_rmse, \"status\": STATUS_OK, \"model\": model}\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"目标函数接受超参数并返回该组超参数的 `train_model` 函数的结果。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def objective(params):\n",
|
||||
" # MLflow will track the parameters and results for each run\n",
|
||||
" result = train_model(\n",
|
||||
" params,\n",
|
||||
" epochs=3,\n",
|
||||
" train_x=train_x,\n",
|
||||
" train_y=train_y,\n",
|
||||
" valid_x=valid_x,\n",
|
||||
" valid_y=valid_y,\n",
|
||||
" test_x=test_x,\n",
|
||||
" test_y=test_y,\n",
|
||||
" )\n",
|
||||
" return result\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"接下来,我们将为 Hyperopt 定义搜索空间。在这种情况下,我们想要尝试不同的学习率和动量值。 Hyperopt 通过选择一组初始超参数来开始其优化过程,通常是随机选择或基于指定的域空间选择。该域空间定义了每个超参数可能值的范围和分布。在评估初始集后,Hyperopt 使用结果更新其概率模型,以特定的的方式指导后续超参数集的选择,旨在收敛到最优解。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"space = {\n",
|
||||
" \"lr\": hp.loguniform(\"lr\", np.log(1e-5), np.log(1e-1)),\n",
|
||||
" \"momentum\": hp.uniform(\"momentum\", 0.0, 1.0),\n",
|
||||
"}\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"最后,我们将使用 Hyperopt 运行超参数扫描,传入目标函数和搜索空间。 Hyperopt 将尝试不同的超参数组合并返回最佳组合的结果。每次尝试的数据都会在 `train_model` 中被记录,我们同时也会最佳参数、模型和评估指标。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"mlflow.set_experiment(\"/wine-quality\")\n",
|
||||
"with mlflow.start_run():\n",
|
||||
" # 使用 Hyperopt 进行最佳超参搜索\n",
|
||||
" trials = Trials()\n",
|
||||
" best = fmin(\n",
|
||||
" fn=objective,\n",
|
||||
" space=space,\n",
|
||||
" algo=tpe.suggest,\n",
|
||||
" max_evals=8,\n",
|
||||
" trials=trials,\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # 获取结果的详细值\n",
|
||||
" best_run = sorted(trials.results, key=lambda x: x[\"loss\"])[0]\n",
|
||||
"\n",
|
||||
" print(best_run)\n",
|
||||
"\n",
|
||||
" # 记录最佳超参、损失值以及模型\n",
|
||||
" mlflow.log_params(best)\n",
|
||||
" mlflow.log_metric(\"eval_rmse\", best_run[\"loss\"])\n",
|
||||
" mlflow.tensorflow.log_model(best_run[\"model\"], \"model\", signature=signature)\n",
|
||||
"\n",
|
||||
" # Print out the best parameters and corresponding loss\n",
|
||||
" print(f\"Best parameters: {best}\")\n",
|
||||
" print(f\"Best eval rmse: {best_run['loss']}\")\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 对比运行结果\n",
|
||||
"\n",
|
||||
"打开 MLflow Web UI,可以看到刚才的训练数据记录在 `/wine-quality` 中。在默认的表视图中,点击展示更多列,添加 test_rmse 、lr 和 momentum 列。再按照均方根误差从低到高排列,此测试数据集上的最小均方根误差通常约为 0.70。对应的 `lr` 和 `momentum` 极为此最小均方根误差的学习率和动量。\n",
|
||||
"\n",
|
||||
"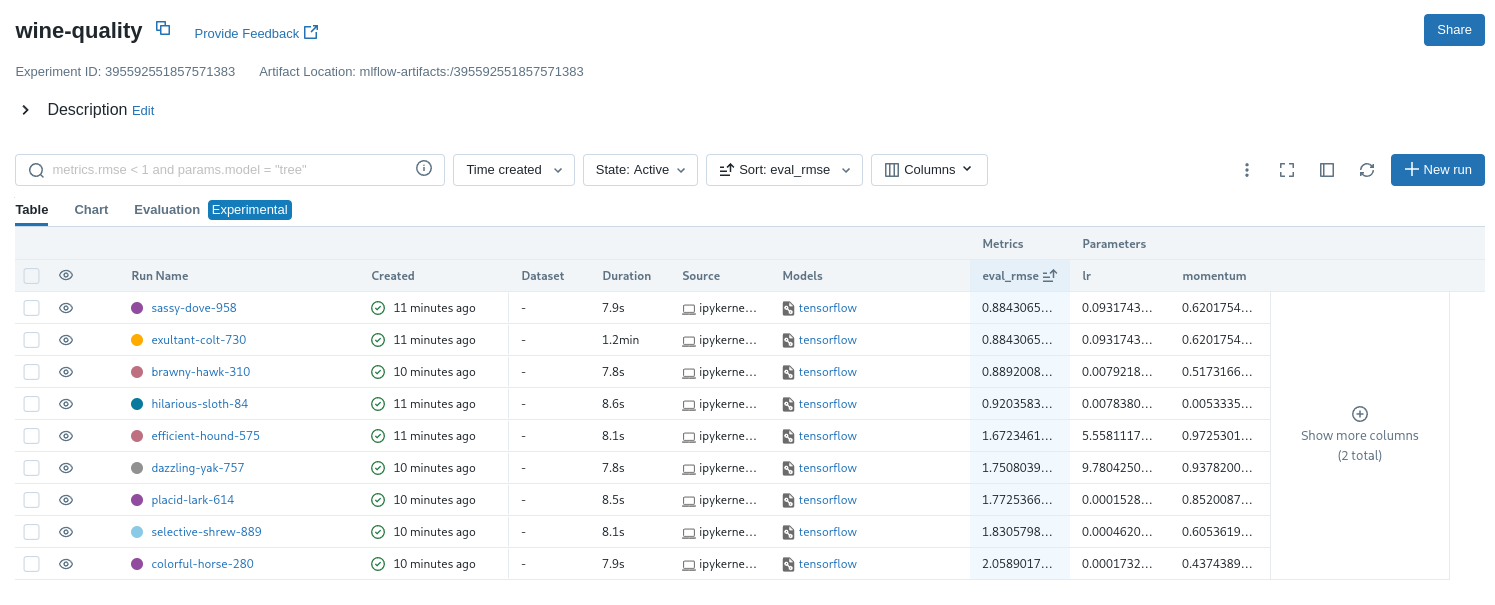\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"选择图表视图。选择平行坐标图并将其配置为显示 lr 和动量坐标以及 test_rmse 指标。该图中的每条线代表一次运行,并将每个超参数评估运行的参数与该运行的评估误差指标相关联。\n",
|
||||
"\n",
|
||||
"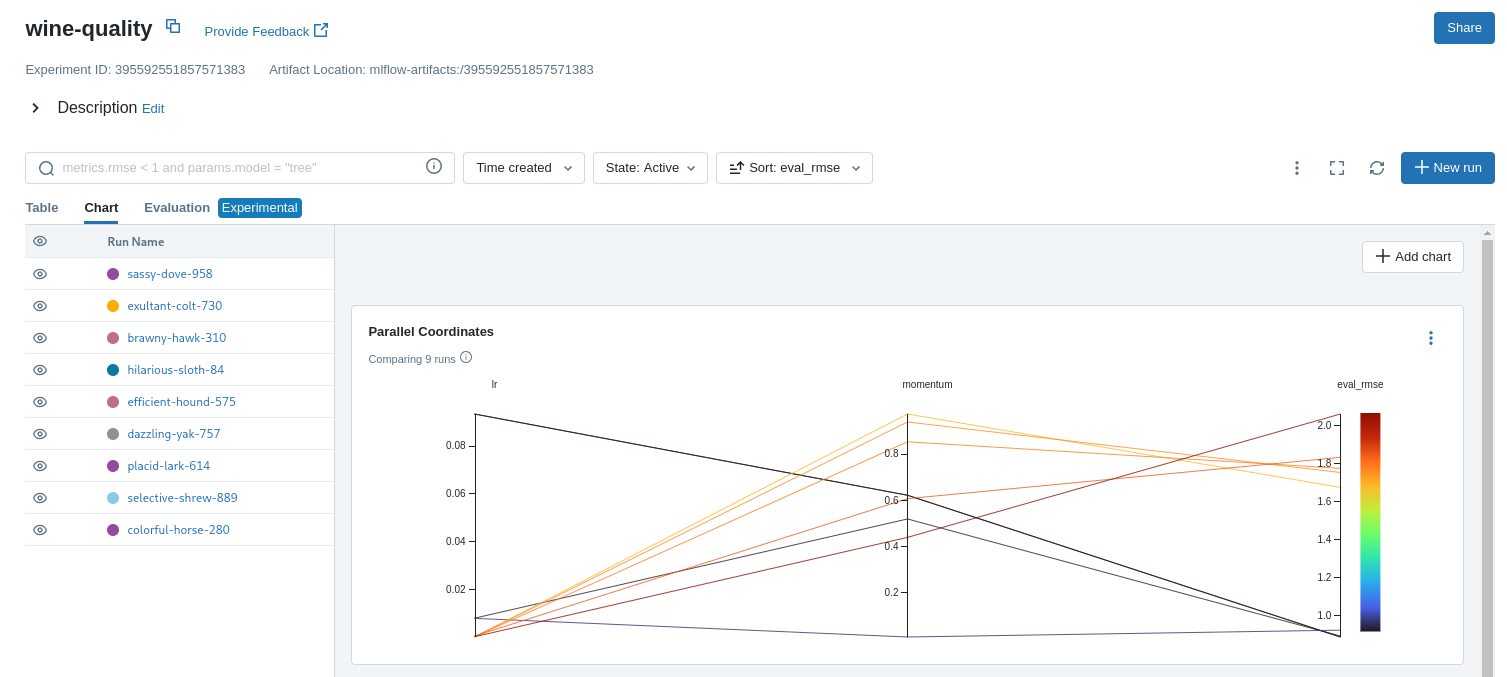\n",
|
||||
"\n",
|
||||
"该图上的红色图是表现不佳的运行。最低的是 lr 和动量均设置为 0.0 的基线运行。该基线运行的 RMSE 约为 0.89。其他红线表明,高势头也可能导致此问题和架构的不良结果。\n",
|
||||
"\n",
|
||||
"蓝色阴影的图表是表现更好的运行。将鼠标悬停在各个运行上即可查看其详细信息。"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 注册最佳模型\n",
|
||||
"\n",
|
||||
"选择最佳运行并将其注册为模型。在表视图中,选择最佳的那次运行结果。在“运行详细信息”页面中,打开`Artifacts`部分并选择 `Register Model` 按钮。在 `Register Model` 对话框中,输入模型的名称,例如 wine-quality,然后单击“注册”。\n",
|
||||
"\n",
|
||||
"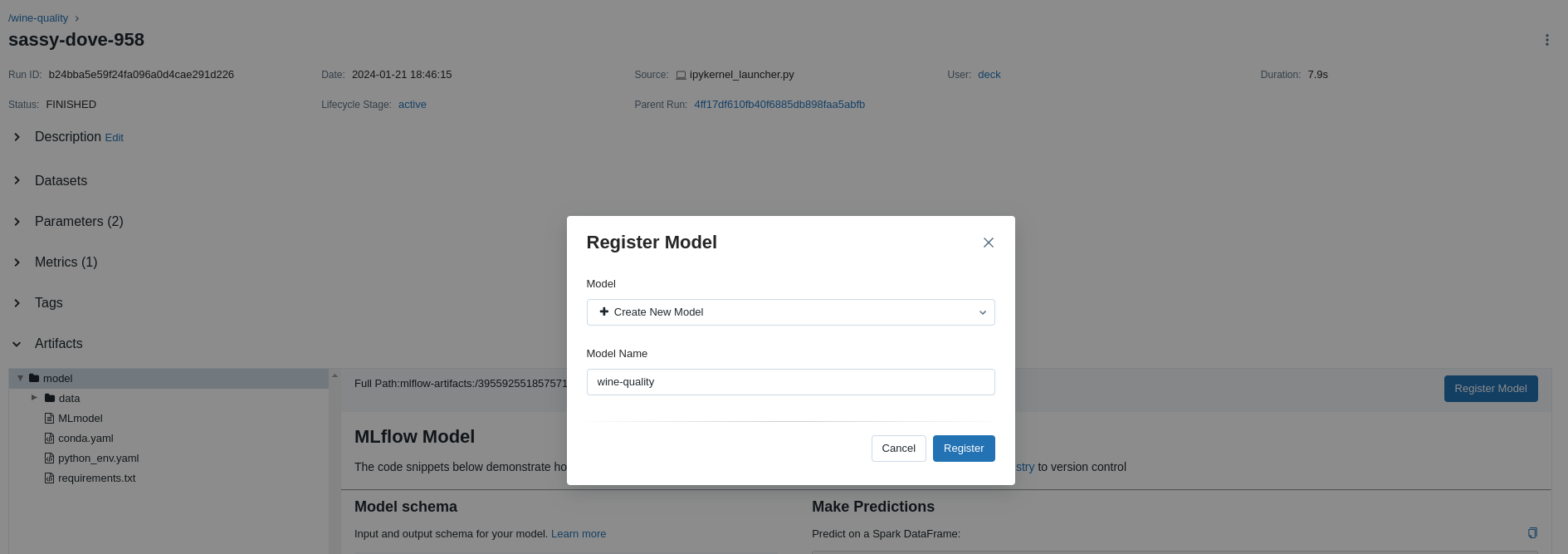\n",
|
||||
"\n",
|
||||
"现在,您的模型可供部署。您可以在 MLflow UI 的模型页面中看到它。打开您刚刚注册的模型的页面。\n",
|
||||
"\n",
|
||||
"您可以添加模型的描述、添加标签,并轻松导航回生成该模型的源运行。您还可以将模型过渡到不同的阶段。例如,您可以将模型转换为暂存,以表明它已准备好进行测试。您可以将其转换为生产,以表明它已准备好部署。\n",
|
||||
"\n",
|
||||
"通过选择 Stage 下拉列表将模型转换为 Staging:\n",
|
||||
"\n",
|
||||
"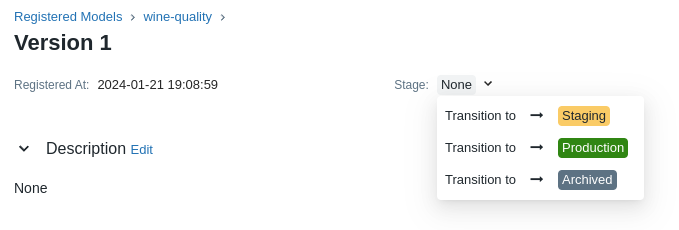"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 在本地测试模型部署\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "mlflow",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
4899
datasets/winequality-white.csv
Normal file
4899
datasets/winequality-white.csv
Normal file
File diff suppressed because it is too large
Load Diff
@ -1,5 +1,12 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 记录第一个模型"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
@ -17,13 +24,9 @@
|
||||
"id": "bd00304d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Initializing the MLflow Client\n",
|
||||
"### 创建一个 MLflow 客户端对象\n",
|
||||
"\n",
|
||||
"Depending on where you are running this notebook, your configuration may vary for how you initialize the MLflow Client in the following cell. \n",
|
||||
"\n",
|
||||
"For this example, we're using a locally running tracking server, but other options are available (The easiest is to use the free managed service within [Databricks Community Edition](https://community.cloud.databricks.com/)). \n",
|
||||
"\n",
|
||||
"Please see [the guide to running notebooks here](https://www.mlflow.org/docs/latest/getting-started/running-notebooks/index.html) for more information on setting the tracking server uri and configuring access to either managed or self-managed MLflow tracking servers."
|
||||
"使用 `mlflow server --host 127.0.0.1 --port 8080` 启动一个服务。\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -33,7 +36,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# NOTE: review the links mentioned above for guidance on connecting to a managed tracking server, such as the free Databricks Community Edition\n",
|
||||
"# NOTE: 请确保与你启动的服务地址一致\n",
|
||||
"\n",
|
||||
"client = MlflowClient(tracking_uri=\"http://127.0.0.1:8080\")"
|
||||
]
|
||||
@ -43,7 +46,7 @@
|
||||
"id": "6129354a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### Search Experiments with the MLflow Client API\n",
|
||||
"#### 使用 MLflow 客户端 API 搜索创建的实验\n",
|
||||
"\n",
|
||||
"Let's take a look at the Default Experiment that is created for us.\n",
|
||||
"\n",
|
||||
@ -61,7 +64,7 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[<Experiment: artifact_location='./mlruns/0', creation_time=None, experiment_id='0', last_update_time=None, lifecycle_stage='active', name='Default', tags={}>]\n"
|
||||
"[<Experiment: artifact_location='mlflow-artifacts:/345492218691480896', creation_time=1705671588054, experiment_id='345492218691480896', last_update_time=1705671588054, lifecycle_stage='active', name='MLflow Quickstart', tags={}>, <Experiment: artifact_location='mlflow-artifacts:/0', creation_time=1705670739503, experiment_id='0', last_update_time=1705670739503, lifecycle_stage='active', name='Default', tags={}>]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
@ -104,7 +107,7 @@
|
||||
"id": "81c37836",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Creating a new Experiment\n",
|
||||
"### 创建一个新实验\n",
|
||||
"\n",
|
||||
"In this section, we'll:\n",
|
||||
"\n",
|
||||
@ -145,7 +148,7 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"<Experiment: artifact_location='mlflow-artifacts:/977454266300166282', creation_time=1696346036899, experiment_id='977454266300166282', last_update_time=1696346036899, lifecycle_stage='active', name='Apple_Models', tags={'mlflow.note.content': 'This is the grocery forecasting project. This '\n",
|
||||
"<Experiment: artifact_location='mlflow-artifacts:/715035017833909618', creation_time=1705818634613, experiment_id='715035017833909618', last_update_time=1705818634613, lifecycle_stage='active', name='Apple_Models', tags={'mlflow.note.content': 'This is the grocery forecasting project. This '\n",
|
||||
" 'experiment contains the produce models for apples.',\n",
|
||||
" 'project_name': 'grocery-forecasting',\n",
|
||||
" 'project_quarter': 'Q3-2023',\n",
|
||||
@ -166,7 +169,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"execution_count": 8,
|
||||
"id": "181a5545",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@ -189,7 +192,7 @@
|
||||
"id": "91c66551",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Running our first model training\n",
|
||||
"### 运行第一个模型训练\n",
|
||||
"\n",
|
||||
"In this section, we'll:\n",
|
||||
"\n",
|
||||
@ -205,7 +208,7 @@
|
||||
"id": "5faffa16",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### Synthetic data generator for demand of apples\n",
|
||||
"#### 生成苹果需求的综合数据\n",
|
||||
"\n",
|
||||
"Keep in mind that this is purely for demonstration purposes. \n",
|
||||
"\n",
|
||||
@ -214,7 +217,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"execution_count": 9,
|
||||
"id": "2268a1cb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@ -265,18 +268,18 @@
|
||||
" }\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # Introduce inflation over time (years)\n",
|
||||
" # 随着时间的推移引入通货膨胀(年)\n",
|
||||
" df[\"inflation_multiplier\"] = 1 + (df[\"date\"].dt.year - df[\"date\"].dt.year.min()) * 0.03\n",
|
||||
"\n",
|
||||
" # Incorporate seasonality due to apple harvests\n",
|
||||
" # 考虑到苹果收获的季节性\n",
|
||||
" df[\"harvest_effect\"] = np.sin(2 * np.pi * (df[\"month\"] - 3) / 12) + np.sin(\n",
|
||||
" 2 * np.pi * (df[\"month\"] - 9) / 12\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # Modify the price_per_kg based on harvest effect\n",
|
||||
" # 根据收获效果修改price_per_kg\n",
|
||||
" df[\"price_per_kg\"] = df[\"price_per_kg\"] - df[\"harvest_effect\"] * 0.5\n",
|
||||
"\n",
|
||||
" # Adjust promo periods to coincide with periods lagging peak harvest by 1 month\n",
|
||||
" # 调整促销期,使其与滞后高峰收获期 1 个月一致\n",
|
||||
" peak_months = [4, 10] # months following the peak availability\n",
|
||||
" df[\"promo\"] = np.where(\n",
|
||||
" df[\"month\"].isin(peak_months),\n",
|
||||
@ -284,7 +287,7 @@
|
||||
" np.random.choice([0, 1], n_rows, p=[0.85, 0.15]),\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" # Generate target variable based on features\n",
|
||||
" # 根据特征生成目标变量\n",
|
||||
" base_price_effect = -df[\"price_per_kg\"] * 50\n",
|
||||
" seasonality_effect = df[\"harvest_effect\"] * 50\n",
|
||||
" promo_effect = df[\"promo\"] * 200\n",
|
||||
@ -298,7 +301,7 @@
|
||||
" + np.random.normal(0, 50, n_rows)\n",
|
||||
" ) * df[\n",
|
||||
" \"inflation_multiplier\"\n",
|
||||
" ] # adding random noise\n",
|
||||
" ] # 引入随机噪声\n",
|
||||
"\n",
|
||||
" # Add previous day's demand\n",
|
||||
" df[\"previous_days_demand\"] = df[\"demand\"].shift(1)\n",
|
||||
@ -312,10 +315,18 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"execution_count": 60,
|
||||
"id": "2924d135",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"/tmp/ipykernel_1170/724292291.py:84: FutureWarning: Series.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.\n",
|
||||
" df[\"previous_days_demand\"].fillna(method=\"bfill\", inplace=True) # fill the first row\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
@ -351,295 +362,295 @@
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>980</th>\n",
|
||||
" <td>2023-09-14 11:13:56.948267</td>\n",
|
||||
" <td>2024-01-02 15:05:05.013229</td>\n",
|
||||
" <td>34.130183</td>\n",
|
||||
" <td>1.454065</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.449177</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>971.802447</td>\n",
|
||||
" <td>1001.085782</td>\n",
|
||||
" <td>999.306290</td>\n",
|
||||
" <td>1029.418398</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>981</th>\n",
|
||||
" <td>2023-09-15 11:13:56.948267</td>\n",
|
||||
" <td>2024-01-03 15:05:05.013227</td>\n",
|
||||
" <td>32.353643</td>\n",
|
||||
" <td>9.462859</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.856503</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>818.951553</td>\n",
|
||||
" <td>971.802447</td>\n",
|
||||
" <td>842.129427</td>\n",
|
||||
" <td>999.306290</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>982</th>\n",
|
||||
" <td>2023-09-16 11:13:56.948266</td>\n",
|
||||
" <td>2024-01-04 15:05:05.013225</td>\n",
|
||||
" <td>18.816833</td>\n",
|
||||
" <td>0.391470</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.326429</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1281.352029</td>\n",
|
||||
" <td>818.951553</td>\n",
|
||||
" <td>990.616709</td>\n",
|
||||
" <td>842.129427</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>983</th>\n",
|
||||
" <td>2023-09-17 11:13:56.948265</td>\n",
|
||||
" <td>2024-01-05 15:05:05.013223</td>\n",
|
||||
" <td>34.533012</td>\n",
|
||||
" <td>2.120477</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.970131</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1357.385504</td>\n",
|
||||
" <td>1281.352029</td>\n",
|
||||
" <td>1068.802075</td>\n",
|
||||
" <td>990.616709</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>984</th>\n",
|
||||
" <td>2023-09-18 11:13:56.948265</td>\n",
|
||||
" <td>2024-01-06 15:05:05.013222</td>\n",
|
||||
" <td>23.057202</td>\n",
|
||||
" <td>2.365705</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.049931</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>991.427049</td>\n",
|
||||
" <td>1357.385504</td>\n",
|
||||
" <td>1346.486305</td>\n",
|
||||
" <td>1068.802075</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>985</th>\n",
|
||||
" <td>2023-09-19 11:13:56.948264</td>\n",
|
||||
" <td>2024-01-07 15:05:05.013220</td>\n",
|
||||
" <td>34.810165</td>\n",
|
||||
" <td>3.089005</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.035149</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>974.971149</td>\n",
|
||||
" <td>991.427049</td>\n",
|
||||
" <td>1329.564672</td>\n",
|
||||
" <td>1346.486305</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>986</th>\n",
|
||||
" <td>2023-09-20 11:13:56.948263</td>\n",
|
||||
" <td>2024-01-08 15:05:05.013218</td>\n",
|
||||
" <td>29.208905</td>\n",
|
||||
" <td>3.673292</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.518098</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1056.249547</td>\n",
|
||||
" <td>974.971149</td>\n",
|
||||
" <td>1086.143402</td>\n",
|
||||
" <td>1329.564672</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>987</th>\n",
|
||||
" <td>2023-09-21 11:13:56.948263</td>\n",
|
||||
" <td>2024-01-09 15:05:05.013216</td>\n",
|
||||
" <td>16.428676</td>\n",
|
||||
" <td>4.077782</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.268979</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1063.118915</td>\n",
|
||||
" <td>1056.249547</td>\n",
|
||||
" <td>1093.207186</td>\n",
|
||||
" <td>1086.143402</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>988</th>\n",
|
||||
" <td>2023-09-22 11:13:56.948262</td>\n",
|
||||
" <td>2024-01-10 15:05:05.013214</td>\n",
|
||||
" <td>32.067512</td>\n",
|
||||
" <td>2.734454</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.762317</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1040.492007</td>\n",
|
||||
" <td>1063.118915</td>\n",
|
||||
" <td>1069.939894</td>\n",
|
||||
" <td>1093.207186</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>989</th>\n",
|
||||
" <td>2023-09-23 11:13:56.948261</td>\n",
|
||||
" <td>2024-01-11 15:05:05.013213</td>\n",
|
||||
" <td>31.938203</td>\n",
|
||||
" <td>13.883486</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.153301</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1285.040470</td>\n",
|
||||
" <td>1040.492007</td>\n",
|
||||
" <td>994.409540</td>\n",
|
||||
" <td>1069.939894</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>990</th>\n",
|
||||
" <td>2023-09-24 11:13:56.948261</td>\n",
|
||||
" <td>2024-01-12 15:05:05.013211</td>\n",
|
||||
" <td>18.024055</td>\n",
|
||||
" <td>7.544061</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.610703</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1366.644564</td>\n",
|
||||
" <td>1285.040470</td>\n",
|
||||
" <td>1078.323183</td>\n",
|
||||
" <td>994.409540</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>991</th>\n",
|
||||
" <td>2023-09-25 11:13:56.948260</td>\n",
|
||||
" <td>2024-01-13 15:05:05.013209</td>\n",
|
||||
" <td>20.681067</td>\n",
|
||||
" <td>18.820490</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.533488</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>973.934924</td>\n",
|
||||
" <td>1366.644564</td>\n",
|
||||
" <td>1328.499120</td>\n",
|
||||
" <td>1078.323183</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>992</th>\n",
|
||||
" <td>2023-09-26 11:13:56.948259</td>\n",
|
||||
" <td>2024-01-14 15:05:05.013207</td>\n",
|
||||
" <td>16.010132</td>\n",
|
||||
" <td>7.705941</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.632498</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1188.291256</td>\n",
|
||||
" <td>973.934924</td>\n",
|
||||
" <td>1548.922141</td>\n",
|
||||
" <td>1328.499120</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>993</th>\n",
|
||||
" <td>2023-09-27 11:13:56.948259</td>\n",
|
||||
" <td>2024-01-15 15:05:05.013198</td>\n",
|
||||
" <td>18.766455</td>\n",
|
||||
" <td>6.274840</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.806554</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>930.089438</td>\n",
|
||||
" <td>1188.291256</td>\n",
|
||||
" <td>956.412724</td>\n",
|
||||
" <td>1548.922141</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>994</th>\n",
|
||||
" <td>2023-09-28 11:13:56.948258</td>\n",
|
||||
" <td>2024-01-16 15:05:05.013196</td>\n",
|
||||
" <td>27.948793</td>\n",
|
||||
" <td>23.705246</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.829464</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1060.576311</td>\n",
|
||||
" <td>930.089438</td>\n",
|
||||
" <td>1090.592622</td>\n",
|
||||
" <td>956.412724</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>995</th>\n",
|
||||
" <td>2023-09-29 11:13:56.948257</td>\n",
|
||||
" <td>2024-01-17 15:05:05.013194</td>\n",
|
||||
" <td>28.661072</td>\n",
|
||||
" <td>10.329865</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.290591</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>910.690776</td>\n",
|
||||
" <td>1060.576311</td>\n",
|
||||
" <td>936.465043</td>\n",
|
||||
" <td>1090.592622</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>996</th>\n",
|
||||
" <td>2023-09-30 11:13:56.948256</td>\n",
|
||||
" <td>2024-01-18 15:05:05.013192</td>\n",
|
||||
" <td>10.821693</td>\n",
|
||||
" <td>3.575645</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0.897473</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1306.363801</td>\n",
|
||||
" <td>910.690776</td>\n",
|
||||
" <td>1016.336362</td>\n",
|
||||
" <td>936.465043</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>997</th>\n",
|
||||
" <td>2023-10-01 11:13:56.948256</td>\n",
|
||||
" <td>2024-01-19 15:05:05.013190</td>\n",
|
||||
" <td>21.108560</td>\n",
|
||||
" <td>6.221089</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1.093864</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1564.422372</td>\n",
|
||||
" <td>1306.363801</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1063.698477</td>\n",
|
||||
" <td>1016.336362</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>998</th>\n",
|
||||
" <td>2023-10-02 11:13:56.948254</td>\n",
|
||||
" <td>2024-01-20 15:05:05.013187</td>\n",
|
||||
" <td>29.451301</td>\n",
|
||||
" <td>5.021463</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.493085</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1164.303256</td>\n",
|
||||
" <td>1564.422372</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1306.255235</td>\n",
|
||||
" <td>1063.698477</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>999</th>\n",
|
||||
" <td>2023-10-03 11:13:56.948248</td>\n",
|
||||
" <td>2024-01-21 15:05:05.013172</td>\n",
|
||||
" <td>19.261458</td>\n",
|
||||
" <td>0.438381</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>2.610422</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1067.963448</td>\n",
|
||||
" <td>1164.303256</td>\n",
|
||||
" <td>0</td>\n",
|
||||
" <td>1207.188828</td>\n",
|
||||
" <td>1306.255235</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" date average_temperature rainfall weekend \n",
|
||||
"980 2023-09-14 11:13:56.948267 34.130183 1.454065 0 \\\n",
|
||||
"981 2023-09-15 11:13:56.948267 32.353643 9.462859 0 \n",
|
||||
"982 2023-09-16 11:13:56.948266 18.816833 0.391470 1 \n",
|
||||
"983 2023-09-17 11:13:56.948265 34.533012 2.120477 1 \n",
|
||||
"984 2023-09-18 11:13:56.948265 23.057202 2.365705 0 \n",
|
||||
"985 2023-09-19 11:13:56.948264 34.810165 3.089005 0 \n",
|
||||
"986 2023-09-20 11:13:56.948263 29.208905 3.673292 0 \n",
|
||||
"987 2023-09-21 11:13:56.948263 16.428676 4.077782 0 \n",
|
||||
"988 2023-09-22 11:13:56.948262 32.067512 2.734454 0 \n",
|
||||
"989 2023-09-23 11:13:56.948261 31.938203 13.883486 1 \n",
|
||||
"990 2023-09-24 11:13:56.948261 18.024055 7.544061 1 \n",
|
||||
"991 2023-09-25 11:13:56.948260 20.681067 18.820490 0 \n",
|
||||
"992 2023-09-26 11:13:56.948259 16.010132 7.705941 0 \n",
|
||||
"993 2023-09-27 11:13:56.948259 18.766455 6.274840 0 \n",
|
||||
"994 2023-09-28 11:13:56.948258 27.948793 23.705246 0 \n",
|
||||
"995 2023-09-29 11:13:56.948257 28.661072 10.329865 0 \n",
|
||||
"996 2023-09-30 11:13:56.948256 10.821693 3.575645 1 \n",
|
||||
"997 2023-10-01 11:13:56.948256 21.108560 6.221089 1 \n",
|
||||
"998 2023-10-02 11:13:56.948254 29.451301 5.021463 0 \n",
|
||||
"999 2023-10-03 11:13:56.948248 19.261458 0.438381 0 \n",
|
||||
" date average_temperature rainfall weekend \\\n",
|
||||
"980 2024-01-02 15:05:05.013229 34.130183 1.454065 0 \n",
|
||||
"981 2024-01-03 15:05:05.013227 32.353643 9.462859 0 \n",
|
||||
"982 2024-01-04 15:05:05.013225 18.816833 0.391470 0 \n",
|
||||
"983 2024-01-05 15:05:05.013223 34.533012 2.120477 0 \n",
|
||||
"984 2024-01-06 15:05:05.013222 23.057202 2.365705 1 \n",
|
||||
"985 2024-01-07 15:05:05.013220 34.810165 3.089005 1 \n",
|
||||
"986 2024-01-08 15:05:05.013218 29.208905 3.673292 0 \n",
|
||||
"987 2024-01-09 15:05:05.013216 16.428676 4.077782 0 \n",
|
||||
"988 2024-01-10 15:05:05.013214 32.067512 2.734454 0 \n",
|
||||
"989 2024-01-11 15:05:05.013213 31.938203 13.883486 0 \n",
|
||||
"990 2024-01-12 15:05:05.013211 18.024055 7.544061 0 \n",
|
||||
"991 2024-01-13 15:05:05.013209 20.681067 18.820490 1 \n",
|
||||
"992 2024-01-14 15:05:05.013207 16.010132 7.705941 1 \n",
|
||||
"993 2024-01-15 15:05:05.013198 18.766455 6.274840 0 \n",
|
||||
"994 2024-01-16 15:05:05.013196 27.948793 23.705246 0 \n",
|
||||
"995 2024-01-17 15:05:05.013194 28.661072 10.329865 0 \n",
|
||||
"996 2024-01-18 15:05:05.013192 10.821693 3.575645 0 \n",
|
||||
"997 2024-01-19 15:05:05.013190 21.108560 6.221089 0 \n",
|
||||
"998 2024-01-20 15:05:05.013187 29.451301 5.021463 1 \n",
|
||||
"999 2024-01-21 15:05:05.013172 19.261458 0.438381 1 \n",
|
||||
"\n",
|
||||
" holiday price_per_kg promo demand previous_days_demand \n",
|
||||
"980 0 1.449177 0 971.802447 1001.085782 \n",
|
||||
"981 0 2.856503 0 818.951553 971.802447 \n",
|
||||
"982 0 1.326429 0 1281.352029 818.951553 \n",
|
||||
"983 0 0.970131 0 1357.385504 1281.352029 \n",
|
||||
"984 0 1.049931 0 991.427049 1357.385504 \n",
|
||||
"985 0 2.035149 0 974.971149 991.427049 \n",
|
||||
"986 0 2.518098 0 1056.249547 974.971149 \n",
|
||||
"987 0 1.268979 0 1063.118915 1056.249547 \n",
|
||||
"988 0 0.762317 0 1040.492007 1063.118915 \n",
|
||||
"989 0 1.153301 0 1285.040470 1040.492007 \n",
|
||||
"990 0 0.610703 0 1366.644564 1285.040470 \n",
|
||||
"991 0 1.533488 0 973.934924 1366.644564 \n",
|
||||
"992 0 1.632498 1 1188.291256 973.934924 \n",
|
||||
"993 0 2.806554 0 930.089438 1188.291256 \n",
|
||||
"994 0 0.829464 0 1060.576311 930.089438 \n",
|
||||
"995 0 2.290591 0 910.690776 1060.576311 \n",
|
||||
"996 0 0.897473 0 1306.363801 910.690776 \n",
|
||||
"997 0 1.093864 1 1564.422372 1306.363801 \n",
|
||||
"998 0 2.493085 1 1164.303256 1564.422372 \n",
|
||||
"999 0 2.610422 1 1067.963448 1164.303256 "
|
||||
"980 0 1.449177 0 999.306290 1029.418398 \n",
|
||||
"981 0 2.856503 0 842.129427 999.306290 \n",
|
||||
"982 0 1.326429 0 990.616709 842.129427 \n",
|
||||
"983 0 0.970131 0 1068.802075 990.616709 \n",
|
||||
"984 0 1.049931 0 1346.486305 1068.802075 \n",
|
||||
"985 0 2.035149 0 1329.564672 1346.486305 \n",
|
||||
"986 0 2.518098 0 1086.143402 1329.564672 \n",
|
||||
"987 0 1.268979 0 1093.207186 1086.143402 \n",
|
||||
"988 0 0.762317 0 1069.939894 1093.207186 \n",
|
||||
"989 0 1.153301 0 994.409540 1069.939894 \n",
|
||||
"990 0 0.610703 0 1078.323183 994.409540 \n",
|
||||
"991 0 1.533488 0 1328.499120 1078.323183 \n",
|
||||
"992 0 1.632498 1 1548.922141 1328.499120 \n",
|
||||
"993 0 2.806554 0 956.412724 1548.922141 \n",
|
||||
"994 0 0.829464 0 1090.592622 956.412724 \n",
|
||||
"995 0 2.290591 0 936.465043 1090.592622 \n",
|
||||
"996 0 0.897473 0 1016.336362 936.465043 \n",
|
||||
"997 0 1.093864 0 1063.698477 1016.336362 \n",
|
||||
"998 0 2.493085 0 1306.255235 1063.698477 \n",
|
||||
"999 0 2.610422 0 1207.188828 1306.255235 "
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"execution_count": 60,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@ -657,14 +668,14 @@
|
||||
"id": "e076a312",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Train and log the model\n",
|
||||
"### 训练并记录模型数据\n",
|
||||
"\n",
|
||||
"We're now ready to import our model class and train a ``RandomForestRegressor``"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"execution_count": 61,
|
||||
"id": "6e354900",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@ -691,7 +702,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"execution_count": 62,
|
||||
"id": "ae02e54b",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@ -699,10 +710,8 @@
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"/Users/benjamin.wilson/miniconda3/envs/mlflow-dev-env/lib/python3.8/site-packages/mlflow/models/signature.py:333: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details.\n",
|
||||
" input_schema = _infer_schema(input_ex)\n",
|
||||
"/Users/benjamin.wilson/miniconda3/envs/mlflow-dev-env/lib/python3.8/site-packages/_distutils_hack/__init__.py:30: UserWarning: Setuptools is replacing distutils.\n",
|
||||
" warnings.warn(\"Setuptools is replacing distutils.\")\n"
|
||||
"/home/deck/miniconda3/envs/mlflow/lib/python3.10/site-packages/mlflow/models/signature.py:358: UserWarning: Hint: Inferred schema contains integer column(s). Integer columns in Python cannot represent missing values. If your input data contains missing values at inference time, it will be encoded as floats and will cause a schema enforcement error. The best way to avoid this problem is to infer the model schema based on a realistic data sample (training dataset) that includes missing values. Alternatively, you can declare integer columns as doubles (float64) whenever these columns may have missing values. See `Handling Integers With Missing Values <https://www.mlflow.org/docs/latest/models.html#handling-integers-with-missing-values>`_ for more details.\n",
|
||||
" input_schema = _infer_schema(input_example)\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
@ -711,7 +720,7 @@
|
||||
"X = data.drop(columns=[\"date\", \"demand\"])\n",
|
||||
"y = data[\"demand\"]\n",
|
||||
"\n",
|
||||
"# Split the data into training and validation sets\n",
|
||||
"# 将数据分为训练集和测试集\n",
|
||||
"X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)\n",
|
||||
"\n",
|
||||
"params = {\n",
|
||||
@ -783,7 +792,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.13"
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
|
||||
Loading…
Reference in New Issue
Block a user