
This document describes the XML library provideed in the Gnome framework. XML is a standard to build tag based structured documents/data.
Here are some key points about libxml:
There is some on-line resources about using libxml :
Well bugs or missing features are always possible, and I will make a point of fixing them in a timely fashion. The best way it to use the Gnome bug tracking database. I look at reports there regulary and it's good to have a reminder when a bug is still open. Check the instructions on reporting bugs and be sure to specify thatthe bug is for the package gnome-xml.
There is also a mailing-list xml@rufus.w3.org for libxml, with an on-line archive. To subscribe to this majordomo based list, send a mail to majordomo@rufus.w3.org with "subscribe xml" in the content of the message.
Alternately you can just send the bug to the xml@rufus.w3.org list.
Latest versions can be found on rpmfind.net or on the Gnome FTP server either as a source archive or RPMs packages (NOTE that you need both the libxml and libxml-devel packages installed to compile applications using libxml).
Libxml is also available from 2 CVs bases:
The W3C CVS base, available read-only using the CVS pserver authentification (I tend to use this base for my own developements so it's updated more regulary, but content may not be as stable):
CVSROOT=:pserver:anonymous@dev.w3.org:/sources/public password: anonymous module: XML
The Gnome CVS base, Check the Gnome CVS Tools page, the CVS module is gnome-xml
XML is a standard for markup based structured documents, here is an example:
<?xml version="1.0"?> <EXAMPLE prop1="gnome is great" prop2="& linux too"> <head> <title>Welcome to Gnome</title> </head> <chapter> <title>The Linux adventure</title> <p>bla bla bla ...</p> <image href="linus.gif"/> <p>...</p> </chapter> </EXAMPLE>
The first line specify that it's an XML document and gives useful
informations about it's encoding. Then the document is a text format whose
structure is specified by tags between brackets. Each tag opened have
to be closed XML is pedantic about this, not that for example the
image tag has no content (just an attribute) and is closed by ending up the
tag with />.
XML can be applied sucessfully to a wide range or usage from long term structured document maintenance where it follows the steps of SGML to simple data encoding mechanism like configuration file format (glade), spreadsheets (gnumeric), or even shorter lived document like in WebDAV where it is used to encode remote call between a client and a server.
The parser returns a tree built during the document analysis. The value returned is an xmlDocPtr (i.e. a pointer to an xmlDoc structure). This structure contains informations like the file name, the document type, and a root pointer which is the root of the document (or more exactly the first child under the root which is the document). The tree is made of xmlNodes, chained in double linked lists of siblings and with childs<->parent relationship. An xmlNode can also carry properties (a chain of xmlAttr structures). An attribute may have a value which is a list of TEXT or ENTITY_REF nodes.
Here is an example (erroneous w.r.t. the XML spec since there should be only one ELEMENT under the root):
In the source package there is a small program (not installed by default) called tester which parses XML files given as argument and prints them back as parsed, this is useful to detect errors both in XML code and in the XML parser itself. It has an option --debug which prints the actual in-memory structure of the document, here is the result with the example given before:
DOCUMENT
version=1.0
standalone=true
ELEMENT EXAMPLE
ATTRIBUTE prop1
TEXT
content=gnome is great
ATTRIBUTE prop2
ENTITY_REF
TEXT
content= linux too
ELEMENT title
TEXT
content=Welcome to Gnome
ELEMENT chapter
ELEMENT title
TEXT
content=The Linux adventure
ELEMENT p
TEXT
content=bla bla bla ...
ELEMENT image
ATTRIBUTE href
TEXT
content=linus.gif
ELEMENT p
TEXT
content=...
This should be useful to learn the internal representation model.
Sometimes the DOM tree output is just to large to fit reasonably into memory. In that case and if you don't expect to save back the XML document loaded using libxml, it's better to use the SAX interface of libxml. SAX is a callback based interface to the parser. Before parsing, the application layer register a customized set of callbacks which will be called by the library as it progresses through the XML input.
To get a more detailed step-by-step guidance on using the SAX interface of libxml, James Henstridge made a nice documentation.
You can debug the SAX behaviour by using the testSAX program located in the gnome-xml module (it's usually not shipped in the binary packages of libxml, but you can also find it in the tar source distribution). Here is the sequence of callback that would be generated when parsing the example given before as reported by testSAX:
SAX.setDocumentLocator() SAX.startDocument() SAX.getEntity(amp) SAX.startElement(EXAMPLE, prop1='gnome is great', prop2='& linux too') SAX.characters( , 3) SAX.startElement(head) SAX.characters( , 4) SAX.startElement(title) SAX.characters(Welcome to Gnome, 16) SAX.endElement(title) SAX.characters( , 3) SAX.endElement(head) SAX.characters( , 3) SAX.startElement(chapter) SAX.characters( , 4) SAX.startElement(title) SAX.characters(The Linux adventure, 19) SAX.endElement(title) SAX.characters( , 4) SAX.startElement(p) SAX.characters(bla bla bla ..., 15) SAX.endElement(p) SAX.characters( , 4) SAX.startElement(image, href='linus.gif') SAX.endElement(image) SAX.characters( , 4) SAX.startElement(p) SAX.characters(..., 3) SAX.endElement(p) SAX.characters( , 3) SAX.endElement(chapter) SAX.characters( , 1) SAX.endElement(EXAMPLE) SAX.endDocument()
Most of the other functionnalities of libxml are based on the DOM tree building facility, so nearly everything up to the end of this document presuppose the use of the standard DOM tree build. Note that the DOM tree itself is built by a set of registered default callbacks, without internal specific interface.
This section is directly intended to help programmers getting bootstrapped using the XML library from the C language. It doesn't intent to be extensive, I hope the automatically generated docs will provide the completeness required, but as a separated set of documents. The interfaces of the XML library are by principle low level, there is nearly zero abstration. Those interested in a higher level API should look at DOM.
The parser interfaces for XML are separated from the HTML parser ones, let's have a look at how it can be called:
Usually, the first thing to do is to read an XML input, the parser accepts to parse both memory mapped documents or direct files. The functions are defined in "parser.h":
xmlDocPtr xmlParseMemory(char *buffer, int size);parse a zero terminated string containing the document
xmlDocPtr xmlParseFile(const char *filename);parse an XML document contained in a file (possibly compressed)
This returns a pointer to the document structure (or NULL in case of failure).
In order for the application to keep the control when the document is been fetched (common for GUI based programs) the libxml, as of version 1.8.3 provides a push interface too, here are the interfaces:
xmlParserCtxtPtr xmlCreatePushParserCtxt(xmlSAXHandlerPtr sax,
void *user_data,
const char *chunk,
int size,
const char *filename);
int xmlParseChunk (xmlParserCtxtPtr ctxt,
const char *chunk,
int size,
int terminate);
and here is a simple use example:
FILE *f;
f = fopen(filename, "r");
if (f != NULL) {
int res, size = 1024;
char chars[1024];
xmlParserCtxtPtr ctxt;
res = fread(chars, 1, 4, f);
if (res > 0) {
ctxt = xmlCreatePushParserCtxt(NULL, NULL,
chars, res, filename);
while ((res = fread(chars, 1, size, f)) > 0) {
xmlParseChunk(ctxt, chars, res, 0);
}
xmlParseChunk(ctxt, chars, 0, 1);
doc = ctxt->myDoc;
xmlFreeParserCtxt(ctxt);
}
}
Also note that the HTML parser embedded into libxml also have a push interface they are just prefixed by "html" instead of "xml"
A couple of comments can be made, first this mean that the parser is
memory-hungry, first to load the document in memory, second to build the tree.
Reading a document without building the tree is possible using the SAX
interfaces (see SAX.h and James
Henstridge documentation), not also that the push interface can be limited
to SAX, just use the two first arguments of
xmlCreatePushParserCtxt().
The other way to get an XML tree in memory is by building it. Basically there is a set of functions dedicated to building new elements, those are also described in "tree.h", here is for example the piece of code producing the example used before:
xmlDocPtr doc;
xmlNodePtr tree, subtree;
doc = xmlNewDoc("1.0");
doc->root = xmlNewDocNode(doc, NULL, "EXAMPLE", NULL);
xmlSetProp(doc->root, "prop1", "gnome is great");
xmlSetProp(doc->root, "prop2", "& linux too");
tree = xmlNewChild(doc->root, NULL, "head", NULL);
subtree = xmlNewChild(tree, NULL, "title", "Welcome to Gnome");
tree = xmlNewChild(doc->root, NULL, "chapter", NULL);
subtree = xmlNewChild(tree, NULL, "title", "The Linux adventure");
subtree = xmlNewChild(tree, NULL, "p", "bla bla bla ...");
subtree = xmlNewChild(tree, NULL, "image", NULL);
xmlSetProp(subtree, "href", "linus.gif");
Not really rocket science ...
Basically by including "tree.h" your code has access to the internal structure of all the element of the tree. The names should be somewhat simple like parent, childs, next, prev, properties, etc... For example still with the previous example:
doc->root->childs->childspoints to the title element,
doc->root->childs->next->child->child
points to the text node containing the chapter titlle "The Linux adventure" and
NOTE: XML allows PIs and comments to be
present before the document root, so doc->root may point to an element which
is not the document Root Element, a function
xmlDocGetRootElement() was added for this purpose.
functions are provided to read and write the document content, here is an excerpt from the tree API:
xmlAttrPtr xmlSetProp(xmlNodePtr node, const xmlChar *name, const
xmlChar *value);This set (or change) an attribute carried by an ELEMENT node the value can be NULL
const xmlChar *xmlGetProp(xmlNodePtr node, const xmlChar
*name);This function returns a pointer to the property content, note that no extra copy is made
Two functions must be used to read an write the text associated to elements:
xmlNodePtr xmlStringGetNodeList(xmlDocPtr doc, const xmlChar
*value);This function takes an "external" string and convert it to one text node or possibly to a list of entity and text nodes. All non-predefined entity references like &Gnome; will be stored internally as an entity node, hence the result of the function may not be a single node.
xmlChar *xmlNodeListGetString(xmlDocPtr doc, xmlNodePtr list, int
inLine);this is the dual function, which generate a new string containing the content of the text and entity nodes. Note the extra argument inLine, if set to 1 instead of returning the &Gnome; XML encoding in the string it will substitute it with it's value say "GNU Network Object Model Environment". Set it if you want to use the string for non XML usage like User Interface.
Basically 3 options are possible:
void xmlDocDumpMemory(xmlDocPtr cur, xmlChar**mem, int
*size);returns a buffer where the document has been saved
extern void xmlDocDump(FILE *f, xmlDocPtr doc);dumps a buffer to an open file descriptor
int xmlSaveFile(const char *filename, xmlDocPtr cur);save the document ot a file. In that case the compression interface is triggered if turned on
The library handle transparently compression when doing file based accesses, the level of compression on saves can be tuned either globally or individually for one file:
int xmlGetDocCompressMode (xmlDocPtr doc);Get the document compression ratio (0-9)
void xmlSetDocCompressMode (xmlDocPtr doc, int mode);Set the document compression ratio
int xmlGetCompressMode(void);Get the default compression ratio
void xmlSetCompressMode(int mode);set the default compression ratio
Entities principle is similar to simple C macros. They define an abbreviation for a given string that you can reuse many time through the content of your document. They are especially useful when frequent occurrences of a given string may occur within a document or to confine the change needed to a document to a restricted area in the internal subset of the document (at the beginning). Example:
1 <?xml version="1.0"?> 2 <!DOCTYPE EXAMPLE SYSTEM "example.dtd" [ 3 <!ENTITY xml "Extensible Markup Language"> 4 ]> 5 <EXAMPLE> 6 &xml; 7 </EXAMPLE>
Line 3 declares the xml entity. Line 6 uses the xml entity, by prefixing it's name with '&' and following it by ';' without any spaces added. There are 5 predefined entities in libxml allowing to escape charaters with predefined meaning in some parts of the xml document content: < for the letter '<', > for the letter '>', ' for the letter ''', " for the letter '"', and & for the letter '&'.
One of the problems related to entities is that you may want the parser to substitute entities content to see the replacement text in your application, or you may prefer keeping entities references as such in the content to be able to save the document back without loosing this usually precious information (if the user went through the pain of explicitley defining entities, he may have a a rather negative attitude if you blindly susbtitute them as saving time). The function xmlSubstituteEntitiesDefault() allows to check and change the behaviour, which is to not substitute entities by default.
Here is the DOM tree built by libxml for the previous document in the default case:
/gnome/src/gnome-xml -> ./tester --debug test/ent1
DOCUMENT
version=1.0
ELEMENT EXAMPLE
TEXT
content=
ENTITY_REF
INTERNAL_GENERAL_ENTITY xml
content=Extensible Markup Language
TEXT
content=
And here is the result when substituting entities:
/gnome/src/gnome-xml -> ./tester --debug --noent test/ent1
DOCUMENT
version=1.0
ELEMENT EXAMPLE
TEXT
content= Extensible Markup Language
So entities or no entities ? Basically it depends on your use case, I suggest to keep the non-substituting default behaviour and avoid using entities in your XML document or data if you are not willing to handle the entity references elements in the DOM tree.
Note that at save time libxml enforce the conversion of the predefined entities where necessary to prevent well-formedness problems, and will also transparently replace those with chars (i.e. will not generate entity reference elements in the DOM tree nor call the reference() SAX callback when finding them in the input).
The libxml library implement namespace @@ support by recognizing namespace contructs in the input, and does namespace lookup automatically when building the DOM tree. A namespace declaration is associated with an in-memory structure and all elements or attributes within that namespace point to it. Hence testing the namespace is a simple and fast equality operation at the user level.
I suggest it that people using libxml use a namespace, and declare it on the root element of their document as the default namespace. Then they dont need to happend the prefix in the content but we will have a basis for future semantic refinement and merging of data from different sources. This doesn't augment significantly the size of the XML output, but significantly increase it's value in the long-term.
Concerning the namespace value, this has to be an URL, but this doesn't
have to point to any existing resource on the Web. I suggest using an URL
within a domain you control, which makes sense and if possible holding some
kind of versionning informations. For example
"http://www.gnome.org/gnumeric/1.0" is a good namespace scheme.
Then when you load a file, make sure that a namespace carrying the
version-independant prefix is installed on the root element of your document,
and if the version information don't match something you know, warn the user
and be liberal in what you accept as the input. Also do *not* try to base
namespace checking on the prefix value <foo:text> may be exactly the same
as <bar:text> in another document, what really matter is the URI
associated with the element or the attribute, not the prefix string which is
just a shortcut for the full URI.
@@Interfaces@@
@@Examples@@
Usually people object using namespace in the case of validation, I object
this and will make sure that using namespaces won't break validity checking,
so even is you plan or are using validation I strongly suggest to add
namespaces to your document. A default namespace scheme
xmlns="http://...." should not break validity even on less
flexible parsers. Now using namespace to mix and differenciate content coming
from mutliple Dtd will certainly break current validation schemes, I will try
to provide ways to do this, but this may not be portable or standardized.
Well what is validation and what is a DTD ?
Validation is the process of checking a document against a set of construction rules, a DTD (Document Type Definition) is such a set of rules.
The validation process and building DTDs are the two most difficult parts of XML life cycle. Briefly a DTD defines all the possibles element to be found within your document, what is the formal shape of your document tree (by defining the allowed content of an element, either text, a regular expression for the allowed list of children, or mixed content i.e. both text and childs). The DTD also defines the allowed attributes for all elements and the types of the attributes. For more detailed informations, I suggest to read the related parts of the XML specification, the examples found under gnome-xml/test/valid/dtd and the large amount of books available on XML. The dia example in gnome-xml/test/valid should be both simple and complete enough to allow you to build your own.
A word of warning, building a good DTD which will fit your needs of your application in the long-term is far from trivial, however the extra level of quality it can insure is well worth the price for some sets of applications or if you already have already a DTD defined for your application field.
The validation is not completely finished but in a (very IMHO) usable state. Until a real validation interface is defined the way to do it is to define and set the xmlDoValidityCheckingDefaultValue external variable to 1, this will of course be changed at some point:
extern int xmlDoValidityCheckingDefaultValue;
...
xmlDoValidityCheckingDefaultValue = 1;
To handle external entities, use the function xmlSetExternalEntityLoader(xmlExternalEntityLoader f); to link in you HTTP/FTP/Entities database library to the standard libxml core.
@@interfaces@@
DOM stands for the Document Object Model this is an API for accessing XML or HTML structured documents. Native support for DOM in Gnome is on the way (module gnome-dom), and it will be based on gnome-xml. This will be a far cleaner interface to manipulate XML files within Gnome since it won't expose the internal structure. DOM defines a set of IDL (or Java) interfaces allowing to traverse and manipulate a document. The DOM library will allow accessing and modifying "live" documents presents on other programs like this:
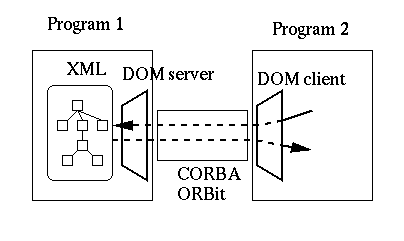
This should help greatly doing things like modifying a gnumeric spreadsheet embedded in a GWP document for example.
The current DOM implementation on top of libxml is the gdome Gnome module, this is a full DOM interface, thanks to Raph Levien.
The gnome-dom module in the Gnome CVS base is obsolete
Here is a real size example, where the actual content of the application data is not kept in the DOM tree but uses internal structures. It is based on a proposal to keep a database of jobs related to Gnome, with an XML based storage structure. Here is an XML encoded jobs base:
<?xml version="1.0"?>
<gjob:Helping xmlns:gjob="http://www.gnome.org/some-location">
<gjob:Jobs>
<gjob:Job>
<gjob:Project ID="3"/>
<gjob:Application>GBackup</gjob:Application>
<gjob:Category>Development</gjob:Category>
<gjob:Update>
<gjob:Status>Open</gjob:Status>
<gjob:Modified>Mon, 07 Jun 1999 20:27:45 -0400 MET DST</gjob:Modified>
<gjob:Salary>USD 0.00</gjob:Salary>
</gjob:Update>
<gjob:Developers>
<gjob:Developer>
</gjob:Developer>
</gjob:Developers>
<gjob:Contact>
<gjob:Person>Nathan Clemons</gjob:Person>
<gjob:Email>nathan@windsofstorm.net</gjob:Email>
<gjob:Company>
</gjob:Company>
<gjob:Organisation>
</gjob:Organisation>
<gjob:Webpage>
</gjob:Webpage>
<gjob:Snailmail>
</gjob:Snailmail>
<gjob:Phone>
</gjob:Phone>
</gjob:Contact>
<gjob:Requirements>
The program should be released as free software, under the GPL.
</gjob:Requirements>
<gjob:Skills>
</gjob:Skills>
<gjob:Details>
A GNOME based system that will allow a superuser to configure
compressed and uncompressed files and/or file systems to be backed
up with a supported media in the system. This should be able to
perform via find commands generating a list of files that are passed
to tar, dd, cpio, cp, gzip, etc., to be directed to the tape machine
or via operations performed on the filesystem itself. Email
notification and GUI status display very important.
</gjob:Details>
</gjob:Job>
</gjob:Jobs>
</gjob:Helping>
While loading the XML file into an internal DOM tree is a matter of calling only a couple of functions, browsing the tree to gather the informations and generate the internals structures is harder, and more error prone.
The suggested principle is to be tolerant with respect to the input structure. For example the ordering of the attributes is not significant, Cthe XML specification is clear about it. It's also usually a good idea to not be dependant of the orders of the childs of a given node, unless it really makes things harder. Here is some code to parse the informations for a person:
/*
* A person record
*/
typedef struct person {
char *name;
char *email;
char *company;
char *organisation;
char *smail;
char *webPage;
char *phone;
} person, *personPtr;
/*
* And the code needed to parse it
*/
personPtr parsePerson(xmlDocPtr doc, xmlNsPtr ns, xmlNodePtr cur) {
personPtr ret = NULL;
DEBUG("parsePerson\n");
/*
* allocate the struct
*/
ret = (personPtr) malloc(sizeof(person));
if (ret == NULL) {
fprintf(stderr,"out of memory\n");
return(NULL);
}
memset(ret, 0, sizeof(person));
/* We don't care what the top level element name is */
cur = cur->childs;
while (cur != NULL) {
if ((!strcmp(cur->name, "Person")) && (cur->ns == ns))
ret->name = xmlNodeListGetString(doc, cur->childs, 1);
if ((!strcmp(cur->name, "Email")) && (cur->ns == ns))
ret->email = xmlNodeListGetString(doc, cur->childs, 1);
cur = cur->next;
}
return(ret);
}
Here is a couple of things to notice:
Here is another piece of code used to parse another level of the structure:
/*
* a Description for a Job
*/
typedef struct job {
char *projectID;
char *application;
char *category;
personPtr contact;
int nbDevelopers;
personPtr developers[100]; /* using dynamic alloc is left as an exercise */
} job, *jobPtr;
/*
* And the code needed to parse it
*/
jobPtr parseJob(xmlDocPtr doc, xmlNsPtr ns, xmlNodePtr cur) {
jobPtr ret = NULL;
DEBUG("parseJob\n");
/*
* allocate the struct
*/
ret = (jobPtr) malloc(sizeof(job));
if (ret == NULL) {
fprintf(stderr,"out of memory\n");
return(NULL);
}
memset(ret, 0, sizeof(job));
/* We don't care what the top level element name is */
cur = cur->childs;
while (cur != NULL) {
if ((!strcmp(cur->name, "Project")) && (cur->ns == ns)) {
ret->projectID = xmlGetProp(cur, "ID");
if (ret->projectID == NULL) {
fprintf(stderr, "Project has no ID\n");
}
}
if ((!strcmp(cur->name, "Application")) && (cur->ns == ns))
ret->application = xmlNodeListGetString(doc, cur->childs, 1);
if ((!strcmp(cur->name, "Category")) && (cur->ns == ns))
ret->category = xmlNodeListGetString(doc, cur->childs, 1);
if ((!strcmp(cur->name, "Contact")) && (cur->ns == ns))
ret->contact = parsePerson(doc, ns, cur);
cur = cur->next;
}
return(ret);
}
One can notice that once used to it, writing this kind of code is quite simple, but boring. Ultimately, it could be possble to write stubbers taking either C data structure definitions, a set of XML examples or an XML DTD and produce the code needed to import and export the content between C data and XML storage. This is left as an exercise to the reader :-)
Feel free to use the code for the full C parsing example as a template, it is also available with Makefile in the Gnome CVS base under gnome-xml/example
$Id: xml.html,v 1.21 2000/01/14 14:45:21 veillard Exp $