docs: Initiate the Chinese translation (#4767)
* docs: init for the chs translation * docs: translate guides to Chinese. (#1) * 翻译文档 * update ChangeLog * docs: add spaces with the heyspace tool * 翻译文档 * docs: add spaces to the follow-up files --------- Co-authored-by: Luke Cheng <2258420+chenglu@users.noreply.github.com> * ignore cn dir in website --------- Co-authored-by: TERRY LEE <59245973+liteli1987gmail@users.noreply.github.com> Co-authored-by: aliabd <ali.si3luwa@gmail.com>
@ -3575,4 +3575,5 @@ We've introduced a lot of new components in `3.0`, including `Model3D`, `Dataset
|
||||
- [@NimaBoscarino](https://github.com/NimaBoscarino) made their first contribution in [PR 1000](https://github.com/gradio-app/gradio/pull/1000)
|
||||
- [@ronvoluted](https://github.com/ronvoluted) made their first contribution in [PR 1050](https://github.com/gradio-app/gradio/pull/1050)
|
||||
- [@radames](https://github.com/radames) made their first contribution in [PR 1074](https://github.com/gradio-app/gradio/pull/1074)
|
||||
- [@freddyaboulton](https://github.com/freddyaboulton) made their first contribution in [PR 1085](https://github.com/gradio-app/gradio/pull/1085)
|
||||
- [@freddyaboulton](https://github.com/freddyaboulton) made their first contribution in [PR 1085](https://github.com/gradio-app/gradio/pull/1085)
|
||||
- [@liteli1987gmail](https://github.com/liteli1987gmail) & [@chenglu](https://github.com/chenglu) made their first contribution in [PR 4767](https://github.com/gradio-app/gradio/pull/4767)
|
||||
118
guides/cn/01_getting-started/01_quickstart.md
Normal file
@ -0,0 +1,118 @@
|
||||
# 快速开始
|
||||
|
||||
**先决条件**:Gradio 需要 Python 3.8 或更高版本,就是这样!
|
||||
|
||||
## Gradio 是做什么的?
|
||||
|
||||
与他人分享您的机器学习模型、API 或数据科学流程的*最佳方式之一*是创建一个**交互式应用程序**,让您的用户或同事可以在他们的浏览器中尝试演示。
|
||||
|
||||
Gradio 允许您**使用 Python 构建演示并共享这些演示**。通常只需几行代码!那么我们开始吧。
|
||||
|
||||
## Hello, World
|
||||
|
||||
要通过一个简单的“Hello, World”示例运行 Gradio,请遵循以下三个步骤:
|
||||
|
||||
1. 使用 pip 安装 Gradio:
|
||||
|
||||
```bash
|
||||
pip install gradio
|
||||
```
|
||||
|
||||
2. 将下面的代码作为 Python 脚本运行或在 Jupyter Notebook 中运行(或者 [Google Colab](https://colab.research.google.com/drive/18ODkJvyxHutTN0P5APWyGFO_xwNcgHDZ?usp=sharing)):
|
||||
|
||||
$code_hello_world
|
||||
|
||||
我们将导入的名称缩短为 `gr`,以便以后在使用 Gradio 的代码中更容易理解。这是一种广泛采用的约定,您应该遵循,以便与您的代码一起工作的任何人都可以轻松理解。
|
||||
|
||||
3. 在 Jupyter Notebook 中,该演示将自动显示;如果从脚本运行,则会在浏览器中弹出,网址为 [http://localhost:7860](http://localhost:7860):
|
||||
|
||||
$demo_hello_world
|
||||
|
||||
在本地开发时,如果您想将代码作为 Python 脚本运行,您可以使用 Gradio CLI 以**重载模式**启动应用程序,这将提供无缝和快速的开发。了解有关[自动重载指南](https://gradio.app/developing-faster-with-reload-mode/)中重新加载的更多信息。
|
||||
|
||||
```bash
|
||||
gradio app.py
|
||||
```
|
||||
|
||||
注意:您也可以运行 `python app.py`,但它不会提供自动重新加载机制。
|
||||
|
||||
## `Interface` 类
|
||||
|
||||
您会注意到为了创建演示,我们创建了一个 `gr.Interface`。`Interface` 类可以将任何 Python 函数与用户界面配对。在上面的示例中,我们看到了一个简单的基于文本的函数,但该函数可以是任何内容,从音乐生成器到税款计算器再到预训练的机器学习模型的预测函数。
|
||||
|
||||
`Interface` 类的核心是使用三个必需参数进行初始化:
|
||||
|
||||
- `fn`:要在其周围包装 UI 的函数
|
||||
- `inputs`:用于输入的组件(例如 `"text"`、`"image"` 或 `"audio"`)
|
||||
- `outputs`:用于输出的组件(例如 `"text"`、`"image"` 或 `"label"`)
|
||||
|
||||
让我们更详细地了解用于提供输入和输出的组件。
|
||||
|
||||
## 组件属性 (Components Attributes)
|
||||
|
||||
我们在前面的示例中看到了一些简单的 `Textbox` 组件,但是如果您想更改 UI 组件的外观或行为怎么办?
|
||||
|
||||
假设您想自定义输入文本字段 - 例如,您希望它更大并具有文本占位符。如果我们使用实际的 `Textbox` 类而不是使用字符串快捷方式,您可以通过组件属性获得更多的自定义功能。
|
||||
|
||||
$code_hello_world_2
|
||||
$demo_hello_world_2
|
||||
|
||||
## 多个输入和输出组件
|
||||
|
||||
假设您有一个更复杂的函数,具有多个输入和输出。在下面的示例中,我们定义了一个接受字符串、布尔值和数字,并返回字符串和数字的函数。请看一下如何传递输入和输出组件的列表。
|
||||
|
||||
$code_hello_world_3
|
||||
$demo_hello_world_3
|
||||
|
||||
只需将组件包装在列表中。`inputs` 列表中的每个组件对应函数的一个参数,顺序相同。`outputs` 列表中的每个组件对应函数返回的一个值,同样是顺序。
|
||||
|
||||
## 图像示例
|
||||
|
||||
Gradio 支持许多类型的组件,例如 `Image`、`DataFrame`、`Video` 或 `Label`。让我们尝试一个图像到图像的函数,以了解这些组件的感觉!
|
||||
|
||||
$code_sepia_filter
|
||||
$demo_sepia_filter
|
||||
|
||||
使用 `Image` 组件作为输入时,您的函数将接收到一个形状为`(高度,宽度,3)` 的 NumPy 数组,其中最后一个维度表示 RGB 值。我们还将返回一个图像,形式为 NumPy 数组。
|
||||
|
||||
您还可以使用 `type=` 关键字参数设置组件使用的数据类型。例如,如果您希望函数接受图像文件路径而不是 NumPy 数组,输入 `Image` 组件可以写成:
|
||||
|
||||
```python
|
||||
gr.Image(type="filepath", shape=...)
|
||||
```
|
||||
|
||||
还要注意,我们的输入 `Image` 组件附带有一个编辑按钮🖉,允许裁剪和缩放图像。通过这种方式操作图像可以帮助揭示机器学习模型中的偏见或隐藏的缺陷!
|
||||
|
||||
您可以在[Gradio 文档](https://gradio.app/docs)中阅读有关许多组件以及如何使用它们的更多信息。
|
||||
|
||||
## Blocks:更灵活和可控
|
||||
|
||||
Gradio 提供了两个类来构建应用程序:
|
||||
|
||||
1. **Interface**,提供了用于创建演示的高级抽象,我们到目前为止一直在讨论。
|
||||
|
||||
2. **Blocks**,用于以更灵活的布局和数据流设计 Web 应用程序的低级 API。Blocks 允许您执行诸如特性多个数据流和演示,控制组件在页面上的出现位置,处理复杂的数据流(例如,输出可以作为其他函数的输入),并基于用户交互更新组件的属性 / 可见性等操作 - 仍然全部使用 Python。如果您需要这种可定制性,请尝试使用 `Blocks`!
|
||||
|
||||
## Hello, Blocks
|
||||
|
||||
让我们看一个简单的示例。请注意,此处的 API 与 `Interface` 不同。
|
||||
|
||||
$code_hello_blocks
|
||||
$demo_hello_blocks
|
||||
|
||||
需要注意的事项:
|
||||
|
||||
- `Blocks` 可以使用 `with` 子句创建,此子句中创建的任何组件都会自动添加到应用程序中。
|
||||
- 组件以按创建顺序垂直放置在应用程序中。(稍后我们将介绍自定义布局!)
|
||||
- 创建了一个 `Button`,然后在此按钮上添加了一个 `click` 事件监听器。对于这个 API,应该很熟悉!与 `Interface` 类似,`click` 方法接受一个 Python 函数、输入组件和输出组件。
|
||||
|
||||
## 更复杂的应用
|
||||
|
||||
下面是一个应用程序,以让您对 `Blocks` 可以实现的更多内容有所了解:
|
||||
|
||||
$code_blocks_flipper
|
||||
$demo_blocks_flipper
|
||||
|
||||
这里有更多的东西!在[building with blocks](https://gradio.app/building_with_blocks)部分中,我们将介绍如何创建像这样的复杂的 `Blocks` 应用程序。
|
||||
|
||||
恭喜,您已经熟悉了 Gradio 的基础知识! 🥳 转到我们的[下一个指南](https://gradio.app/key_features)了解更多关于 Gradio 的主要功能。
|
||||
273
guides/cn/01_getting-started/02_key-features.md
Normal file
@ -0,0 +1,273 @@
|
||||
# 主要特点
|
||||
|
||||
让我们来介绍一下 Gradio 最受欢迎的一些功能!这里是 Gradio 的主要特点:
|
||||
|
||||
1. [添加示例输入](#example-inputs)
|
||||
2. [传递自定义错误消息](#errors)
|
||||
3. [添加描述内容](#descriptive-content)
|
||||
4. [设置旗标](#flagging)
|
||||
5. [预处理和后处理](#preprocessing-and-postprocessing)
|
||||
6. [样式化演示](#styling)
|
||||
7. [排队用户](#queuing)
|
||||
8. [迭代输出](#iterative-outputs)
|
||||
9. [进度条](#progress-bars)
|
||||
10. [批处理函数](#batch-functions)
|
||||
11. [在协作笔记本上运行](#colab-notebooks)
|
||||
|
||||
## 示例输入
|
||||
|
||||
您可以提供用户可以轻松加载到 "Interface" 中的示例数据。这对于演示模型期望的输入类型以及演示数据集和模型一起探索的方式非常有帮助。要加载示例数据,您可以将嵌套列表提供给 Interface 构造函数的 `examples=` 关键字参数。外部列表中的每个子列表表示一个数据样本,子列表中的每个元素表示每个输入组件的输入。有关每个组件的示例数据格式在[Docs](https://gradio.app/docs#components)中有说明。
|
||||
|
||||
$code_calculator
|
||||
$demo_calculator
|
||||
|
||||
您可以将大型数据集加载到示例中,通过 Gradio 浏览和与数据集进行交互。示例将自动分页(可以通过 Interface 的 `examples_per_page` 参数进行配置)。
|
||||
|
||||
继续了解示例,请参阅[更多示例](https://gradio.app/more-on-examples)指南。
|
||||
|
||||
## 错误
|
||||
|
||||
您希望向用户传递自定义错误消息。为此,with `gr.Error("custom message")` 来显示错误消息。如果在上面的计算器示例中尝试除以零,将显示自定义错误消息的弹出模态窗口。了解有关错误的更多信息,请参阅[文档](https://gradio.app/docs#error)。
|
||||
|
||||
## 描述性内容
|
||||
|
||||
在前面的示例中,您可能已经注意到 Interface 构造函数中的 `title=` 和 `description=` 关键字参数,帮助用户了解您的应用程序。
|
||||
|
||||
Interface 构造函数中有三个参数用于指定此内容应放置在哪里:
|
||||
|
||||
* `title`:接受文本,并可以将其显示在界面的顶部,也将成为页面标题。
|
||||
* `description`:接受文本、Markdown 或 HTML,并将其放置在标题正下方。
|
||||
* `article`:也接受文本、Markdown 或 HTML,并将其放置在界面下方。
|
||||
|
||||

|
||||
|
||||
如果您使用的是 `Blocks` API,则可以 with `gr.Markdown(...)` 或 `gr.HTML(...)` 组件在任何位置插入文本、Markdown 或 HTML,其中描述性内容位于 `Component` 构造函数内部。
|
||||
|
||||
另一个有用的关键字参数是 `label=`,它存在于每个 `Component` 中。这修改了每个 `Component` 顶部的标签文本。还可以为诸如 `Textbox` 或 `Radio` 之类的表单元素添加 `info=` 关键字参数,以提供有关其用法的进一步信息。
|
||||
|
||||
```python
|
||||
gr.Number(label='年龄', info='以年为单位,必须大于0')
|
||||
```
|
||||
|
||||
## 旗标
|
||||
|
||||
默认情况下,"Interface" 将有一个 "Flag" 按钮。当用户测试您的 `Interface` 时,如果看到有趣的输出,例如错误或意外的模型行为,他们可以将输入标记为您进行查看。在由 `Interface` 构造函数的 `flagging_dir=` 参数提供的目录中,将记录标记的输入到一个 CSV 文件中。如果界面涉及文件数据,例如图像和音频组件,将创建文件夹来存储这些标记的数据。
|
||||
|
||||
例如,对于上面显示的计算器界面,我们将在下面的旗标目录中存储标记的数据:
|
||||
|
||||
```directory
|
||||
+-- calculator.py
|
||||
+-- flagged/
|
||||
| +-- logs.csv
|
||||
```
|
||||
|
||||
*flagged/logs.csv*
|
||||
|
||||
```csv
|
||||
num1,operation,num2,Output
|
||||
5,add,7,12
|
||||
6,subtract,1.5,4.5
|
||||
```
|
||||
|
||||
与早期显示的冷色界面相对应,我们将在下面的旗标目录中存储标记的数据:
|
||||
|
||||
```directory
|
||||
+-- sepia.py
|
||||
+-- flagged/
|
||||
| +-- logs.csv
|
||||
| +-- im/
|
||||
| | +-- 0.png
|
||||
| | +-- 1.png
|
||||
| +-- Output/
|
||||
| | +-- 0.png
|
||||
| | +-- 1.png
|
||||
```
|
||||
|
||||
*flagged/logs.csv*
|
||||
|
||||
```csv
|
||||
im,Output
|
||||
im/0.png,Output/0.png
|
||||
im/1.png,Output/1.png
|
||||
```
|
||||
|
||||
如果您希望用户提供旗标原因,可以将字符串列表传递给 Interface 的 `flagging_options` 参数。用户在进行旗标时必须选择其中一个字符串,这将作为附加列保存到 CSV 中。
|
||||
|
||||
## 预处理和后处理 (Preprocessing and Postprocessing)
|
||||
|
||||

|
||||
|
||||
如您所见,Gradio 包括可以处理各种不同数据类型的组件,例如图像、音频和视频。大多数组件都可以用作输入或输出。
|
||||
|
||||
当组件用作输入时,Gradio 自动处理*预处理*,将数据从用户浏览器发送的类型(例如网络摄像头快照的 base64 表示)转换为您的函数可以接受的形式(例如 `numpy` 数组)。
|
||||
|
||||
同样,当组件用作输出时,Gradio 自动处理*后处理*,将数据从函数返回的形式(例如图像路径列表)转换为可以在用户浏览器中显示的形式(例如以 base64 格式显示图像的 `Gallery`)。
|
||||
|
||||
您可以使用构建图像组件时的参数控制*预处理*。例如,如果您使用以下参数实例化 `Image` 组件,它将将图像转换为 `PIL` 类型,并将其重塑为`(100, 100)`,而不管提交时的原始大小如何:
|
||||
|
||||
```py
|
||||
img = gr.Image(shape=(100, 100), type="pil")
|
||||
```
|
||||
|
||||
相反,这里我们保留图像的原始大小,但在将其转换为 numpy 数组之前反转颜色:
|
||||
|
||||
```py
|
||||
img = gr.Image(invert_colors=True, type="numpy")
|
||||
```
|
||||
|
||||
后处理要容易得多!Gradio 自动识别返回数据的格式(例如 `Image` 是 `numpy` 数组还是 `str` 文件路径?),并将其后处理为可以由浏览器显示的格式。
|
||||
|
||||
请查看[文档](https://gradio.app/docs),了解每个组件的所有与预处理相关的参数。
|
||||
|
||||
## 样式 (Styling)
|
||||
|
||||
Gradio 主题是自定义应用程序外观和感觉的最简单方法。您可以选择多种主题或创建自己的主题。要这样做,请将 `theme=` 参数传递给 `Interface` 构造函数。例如:
|
||||
|
||||
```python
|
||||
demo = gr.Interface(..., theme=gr.themes.Monochrome())
|
||||
```
|
||||
|
||||
Gradio 带有一组预先构建的主题,您可以从 `gr.themes.*` 加载。您可以扩展这些主题或从头开始创建自己的主题 - 有关更多详细信息,请参阅[主题指南](https://gradio.app/theming-guide)。
|
||||
|
||||
要增加额外的样式能力,您可以 with `css=` 关键字将任何 CSS 传递给您的应用程序。
|
||||
Gradio 应用程序的基类是 `gradio-container`,因此以下是一个更改 Gradio 应用程序背景颜色的示例:
|
||||
|
||||
```python
|
||||
with `gr.Interface(css=".gradio-container {background-color: red}") as demo:
|
||||
...
|
||||
```
|
||||
|
||||
一些组件还可以通过 `style()` 方法进行额外的样式设置。例如:
|
||||
|
||||
```python
|
||||
img = gr.Image("lion.jpg").style(height='24', rounded=False)
|
||||
```
|
||||
|
||||
查看[文档](https://gradio.app/docs)可以了解每个组件的所有样式选项。
|
||||
|
||||
## 队列 (Queuing)
|
||||
|
||||
如果您的应用程序预计会有大量流量,请 with `queue()` 方法来控制处理速率。这将排队处理调用,因此一次只处理一定数量的请求。队列使用 Websockets,还可以防止网络超时,因此如果您的函数的推理时间很长(> 1 分钟),应使用队列。
|
||||
|
||||
with `Interface`:
|
||||
|
||||
```python
|
||||
demo = gr.Interface(...).queue()
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
with `Blocks`:
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
#...
|
||||
demo.queue()
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
您可以通过以下方式控制一次处理的请求数量:
|
||||
|
||||
```python
|
||||
demo.queue(concurrency_count=3)
|
||||
```
|
||||
|
||||
查看有关配置其他队列参数的[队列文档](/docs/#queue)。
|
||||
|
||||
在 Blocks 中指定仅对某些函数进行排队:
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo2:
|
||||
num1 = gr.Number()
|
||||
num2 = gr.Number()
|
||||
output = gr.Number()
|
||||
gr.Button("Add").click(
|
||||
lambda a, b: a + b, [num1, num2], output)
|
||||
gr.Button("Multiply").click(
|
||||
lambda a, b: a * b, [num1, num2], output, queue=True)
|
||||
demo2.launch()
|
||||
```
|
||||
|
||||
## 迭代输出 (Iterative Outputs)
|
||||
|
||||
在某些情况下,您可能需要传输一系列输出而不是一次显示单个输出。例如,您可能有一个图像生成模型,希望显示生成的每个步骤的图像,直到最终图像。或者您可能有一个聊天机器人,它逐字逐句地流式传输响应,而不是一次返回全部响应。
|
||||
|
||||
在这种情况下,您可以将**生成器**函数提供给 Gradio,而不是常规函数。在 Python 中创建生成器非常简单:函数不应该有一个单独的 `return` 值,而是应该 with `yield` 连续返回一系列值。通常,`yield` 语句放置在某种循环中。下面是一个简单示例,生成器只是简单计数到给定数字:
|
||||
|
||||
```python
|
||||
def my_generator(x):
|
||||
for i in range(x):
|
||||
yield i
|
||||
```
|
||||
|
||||
您以与常规函数相同的方式将生成器提供给 Gradio。例如,这是一个(虚拟的)图像生成模型,它在输出图像之前生成数个步骤的噪音:
|
||||
|
||||
$code_fake_diffusion
|
||||
$demo_fake_diffusion
|
||||
|
||||
请注意,我们在迭代器中添加了 `time.sleep(1)`,以创建步骤之间的人工暂停,以便您可以观察迭代器的步骤(在真实的图像生成模型中,这可能是不必要的)。
|
||||
|
||||
将生成器提供给 Gradio **需要**在底层 Interface 或 Blocks 中启用队列(请参阅上面的队列部分)。
|
||||
|
||||
## 进度条
|
||||
|
||||
Gradio 支持创建自定义进度条,以便您可以自定义和控制向用户显示的进度更新。要启用此功能,只需为方法添加一个默认值为 `gr.Progress` 实例的参数即可。然后,您可以直接调用此实例并传入 0 到 1 之间的浮点数来更新进度级别,或者 with `Progress` 实例的 `tqdm()` 方法来跟踪可迭代对象上的进度,如下所示。必须启用队列以进行进度更新。
|
||||
|
||||
$code_progress_simple
|
||||
$demo_progress_simple
|
||||
|
||||
如果您 with `tqdm` 库,并且希望从函数内部的任何 `tqdm.tqdm` 自动报告进度更新,请将默认参数设置为 `gr.Progress(track_tqdm=True)`!
|
||||
|
||||
## 批处理函数 (Batch Functions)
|
||||
|
||||
Gradio 支持传递*批处理*函数。批处理函数只是接受输入列表并返回预测列表的函数。
|
||||
|
||||
例如,这是一个批处理函数,它接受两个输入列表(一个单词列表和一个整数列表),并返回修剪过的单词列表作为输出:
|
||||
|
||||
```python
|
||||
import time
|
||||
|
||||
def trim_words(words, lens):
|
||||
trimmed_words = []
|
||||
time.sleep(5)
|
||||
for w, l in zip(words, lens):
|
||||
trimmed_words.append(w[:int(l)])
|
||||
return [trimmed_words]
|
||||
for w, l in zip(words, lens):
|
||||
```
|
||||
使用批处理函数的优点是,如果启用了队列,Gradio 服务器可以自动*批处理*传入的请求并并行处理它们,从而可能加快演示速度。以下是 Gradio 代码的示例(请注意 `batch=True` 和 `max_batch_size=16` - 这两个参数都可以传递给事件触发器或 `Interface` 类)
|
||||
|
||||
with `Interface`:
|
||||
|
||||
```python
|
||||
demo = gr.Interface(trim_words, ["textbox", "number"], ["output"],
|
||||
batch=True, max_batch_size=16)
|
||||
demo.queue()
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
with `Blocks`:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
word = gr.Textbox(label="word")
|
||||
leng = gr.Number(label="leng")
|
||||
output = gr.Textbox(label="Output")
|
||||
with gr.Row():
|
||||
run = gr.Button()
|
||||
|
||||
event = run.click(trim_words, [word, leng], output, batch=True, max_batch_size=16)
|
||||
|
||||
demo.queue()
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
在上面的示例中,可以并行处理 16 个请求(总推理时间为 5 秒),而不是分别处理每个请求(总推理时间为 80 秒)。许多 Hugging Face 的 `transformers` 和 `diffusers` 模型在 Gradio 的批处理模式下自然工作:这是[使用批处理生成图像的示例演示](https://github.com/gradio-app/gradio/blob/main/demo/diffusers_with_batching/run.py)
|
||||
|
||||
注意:使用 Gradio 的批处理函数 **requires** 在底层 Interface 或 Blocks 中启用队列(请参阅上面的队列部分)。
|
||||
|
||||
## Gradio 笔记本 (Colab Notebooks)
|
||||
|
||||
Gradio 可以在任何运行 Python 的地方运行,包括本地 Jupyter 笔记本和协作笔记本,如[Google Colab](https://colab.research.google.com/)。对于本地 Jupyter 笔记本和 Google Colab 笔记本,Gradio 在本地服务器上运行,您可以在浏览器中与之交互。(注意:对于 Google Colab,这是通过[服务工作器隧道](https://github.com/tensorflow/tensorboard/blob/master/docs/design/colab_integration.md)实现的,您的浏览器需要启用 cookies。)对于其他远程笔记本,Gradio 也将在服务器上运行,但您需要使用[SSH 隧道](https://coderwall.com/p/ohk6cg/remote-access-to-ipython-notebooks-via-ssh)在本地浏览器中查看应用程序。通常,更简单的选择是使用 Gradio 内置的公共链接,[在下一篇指南中讨论](/sharing-your-app/#sharing-demos)。
|
||||
209
guides/cn/01_getting-started/03_sharing-your-app.md
Normal file
@ -0,0 +1,209 @@
|
||||
# 分享您的应用
|
||||
|
||||
如何分享您的 Gradio 应用:
|
||||
|
||||
1. [使用 share 参数分享演示](#sharing-demos)
|
||||
2. [在 HF Spaces 上托管](#hosting-on-hf-spaces)
|
||||
3. [嵌入托管的空间](#embedding-hosted-spaces)
|
||||
4. [使用 Web 组件嵌入](#embedding-with-web-components)
|
||||
5. [使用 API 页面](#api-page)
|
||||
6. [在页面上添加身份验证](#authentication)
|
||||
7. [访问网络请求](#accessing-the-network-request-directly)
|
||||
8. [在 FastAPI 中挂载](#mounting-within-another-fastapi-app)
|
||||
9. [安全性](#security-and-file-access)
|
||||
|
||||
## 分享演示
|
||||
|
||||
通过在 `launch()` 方法中设置 `share=True`,可以轻松公开分享 Gradio 演示。就像这样:
|
||||
|
||||
```python
|
||||
demo.launch(share=True)
|
||||
```
|
||||
|
||||
这将生成一个公开的可分享链接,您可以将其发送给任何人!当您发送此链接时,对方用户可以在其浏览器中尝试模型。因为处理过程发生在您的设备上(只要您的设备保持开启!),您不必担心任何打包依赖项的问题。一个分享链接通常看起来像这样:**XXXXX.gradio.app**。尽管链接是通过 Gradio URL 提供的,但我们只是您本地服务器的代理,并不会存储通过您的应用发送的任何数据。
|
||||
|
||||
但请记住,这些链接可以被公开访问,这意味着任何人都可以使用您的模型进行预测!因此,请确保不要通过您编写的函数公开任何敏感信息,也不要允许在您的设备上进行任何关键更改。如果您设置 `share=False`(默认值,在 colab 笔记本中除外),则只创建一个本地链接,可以通过[端口转发](https://www.ssh.com/ssh/tunneling/example)与特定用户共享。
|
||||
|
||||
<img style="width: 40%" src="/assets/guides/sharing.svg">
|
||||
|
||||
分享链接在 72 小时后过期。
|
||||
|
||||
## 在 HF Spaces 上托管
|
||||
|
||||
如果您想在互联网上获得您的 Gradio 演示的永久链接,请使用 Hugging Face Spaces。 [Hugging Face Spaces](http://huggingface.co/spaces/) 提供了免费托管您的机器学习模型的基础设施!
|
||||
|
||||
在您创建了一个免费的 Hugging Face 账户后,有三种方法可以将您的 Gradio 应用部署到 Hugging Face Spaces:
|
||||
1. 从终端:在应用目录中运行 `gradio deploy`。CLI 将收集一些基本元数据,然后启动您的应用。要更新您的空间,可以重新运行此命令或启用 Github Actions 选项,在 `git push` 时自动更新 Spaces。
|
||||
2. 从浏览器:将包含 Gradio 模型和所有相关文件的文件夹拖放到 [此处](https://huggingface.co/new-space)。
|
||||
3. 将 Spaces 与您的 Git 存储库连接,Spaces 将从那里拉取 Gradio 应用。有关更多信息,请参阅 [此指南如何在 Hugging Face Spaces 上托管](https://huggingface.co/blog/gradio-spaces)。
|
||||
|
||||
<video autoplay muted loop>
|
||||
<source src="/assets/guides/hf_demo.mp4" type="video/mp4" />
|
||||
</video>
|
||||
|
||||
## 嵌入托管的空间
|
||||
|
||||
一旦您将应用托管在 Hugging Face Spaces(或您自己的服务器上),您可能希望将演示嵌入到不同的网站上,例如您的博客或个人作品集。嵌入交互式演示使人们可以在他们的浏览器中尝试您构建的机器学习模型,而无需下载或安装任何内容!最好的部分是,您甚至可以将交互式演示嵌入到静态网站中,例如 GitHub 页面。
|
||||
|
||||
有两种方法可以嵌入您的 Gradio 演示。您可以在 Hugging Face Space 页面的“嵌入此空间”下拉选项中直接找到这两个选项的快速链接:
|
||||
|
||||

|
||||
|
||||
### 使用 Web 组件嵌入
|
||||
|
||||
与 IFrames 相比,Web 组件通常为用户提供更好的体验。Web 组件进行延迟加载,这意味着它们不会减慢您网站的加载时间,并且它们会根据 Gradio 应用的大小自动调整其高度。
|
||||
|
||||
要使用 Web 组件嵌入:
|
||||
|
||||
1. 通过在您的网站中添加以下脚本来导入 gradio JS 库(在 URL 中替换{GRADIO_VERSION}为您使用的 Gradio 库的版本)。
|
||||
|
||||
```html
|
||||
<script type="module"
|
||||
src="https://gradio.s3-us-west-2.amazonaws.com/{GRADIO_VERSION}/gradio.js">
|
||||
</script>
|
||||
```
|
||||
|
||||
2. 在您想放置应用的位置添加
|
||||
```html
|
||||
<gradio-app src="https://$your_space_host.hf.space"></gradio-app>
|
||||
```
|
||||
元素。将 `src=` 属性设置为您的 Space 的嵌入 URL,您可以在“嵌入此空间”按钮中找到。例如:
|
||||
|
||||
```html
|
||||
<gradio-app src="https://abidlabs-pytorch-image-classifier.hf.space"></gradio-app>
|
||||
```
|
||||
|
||||
<script>
|
||||
fetch("https://pypi.org/pypi/gradio/json"
|
||||
).then(r => r.json()
|
||||
).then(obj => {
|
||||
let v = obj.info.version;
|
||||
content = document.querySelector('.prose');
|
||||
content.innerHTML = content.innerHTML.replaceAll("{GRADIO_VERSION}", v);
|
||||
});
|
||||
</script>
|
||||
|
||||
您可以在 <a href="https://www.gradio.app">Gradio 首页 </a> 上查看 Web 组件的示例。
|
||||
|
||||
您还可以使用传递给 `<gradio-app>` 标签的属性来自定义 Web 组件的外观和行为:
|
||||
|
||||
* `src`:如前所述,`src` 属性链接到您想要嵌入的托管 Gradio 演示的 URL
|
||||
* `space`:一个可选的缩写,如果您的 Gradio 演示托管在 Hugging Face Space 上。接受 `username/space_name` 而不是完整的 URL。示例:`gradio/Echocardiogram-Segmentation`。如果提供了此属性,则不需要提供 `src`。
|
||||
* `control_page_title`:一个布尔值,指定是否将 html 标题设置为 Gradio 应用的标题(默认为 `"false"`)
|
||||
* `initial_height`:加载 Gradio 应用时 Web 组件的初始高度(默认为 `"300px"`)。请注意,最终高度是根据 Gradio 应用的大小设置的。
|
||||
* `container`:是否显示边框框架和有关 Space 托管位置的信息(默认为 `"true"`)
|
||||
* `info`:是否仅显示有关 Space 托管位置的信息在嵌入的应用程序下方(默认为 `"true"`)
|
||||
* `autoscroll`:在预测完成后是否自动滚动到输出(默认为 `"false"`)
|
||||
* `eager`:在页面加载时是否立即加载 Gradio 应用(默认为 `"false"`)
|
||||
* `theme_mode`:是否使用 `dark`,`light` 或默认的 `system` 主题模式(默认为 `"system"`)
|
||||
|
||||
以下是使用这些属性创建一个懒加载且初始高度为 0px 的 Gradio 应用的示例。
|
||||
|
||||
```html
|
||||
<gradio-app space="gradio/Echocardiogram-Segmentation" eager="true"
|
||||
initial_height="0px"></gradio-app>
|
||||
```
|
||||
|
||||
_ 注意:Gradio 的 CSS 永远不会影响嵌入页面,但嵌入页面可以影响嵌入的 Gradio 应用的样式。请确保父页面中的任何 CSS 不是如此通用,以至于它也可能适用于嵌入的 Gradio 应用并导致样式破裂。例如,元素选择器如 `header { ... }` 和 `footer { ... }` 最可能引起问题。_
|
||||
|
||||
### 使用 IFrames 嵌入
|
||||
|
||||
如果您无法向网站添加 javascript(例如),则可以改为使用 IFrames 进行嵌入,请添加以下元素:
|
||||
|
||||
```html
|
||||
<iframe src="https://$your_space_host.hf.space"></iframe>
|
||||
```
|
||||
|
||||
同样,您可以在“嵌入此空间”按钮中找到您的 Space 的嵌入 URL 的 `src=` 属性。
|
||||
|
||||
注意:如果您使用 IFrames,您可能希望添加一个固定的 `height` 属性,并设置 `style="border:0;"` 以去除边框。此外,如果您的应用程序需要诸如访问摄像头或麦克风之类的权限,您还需要使用 `allow` 属性提供它们。
|
||||
|
||||
## API 页面
|
||||
|
||||
$demo_hello_world
|
||||
|
||||
如果您点击并打开上面的空间,您会在应用的页脚看到一个“通过 API 使用”链接。
|
||||
|
||||

|
||||
|
||||
这是一个文档页面,记录了用户可以使用的 REST API 来查询“Interface”函数。`Blocks` 应用程序也可以生成 API 页面,但必须为每个事件监听器显式命名 API,例如:
|
||||
|
||||
```python
|
||||
btn.click(add, [num1, num2], output, api_name="addition")
|
||||
```
|
||||
|
||||
这将记录自动生成的 API 页面的端点 `/api/addition/`。
|
||||
|
||||
*注意*:对于启用了[队列功能](https://gradio.app/key-features#queuing)的 Gradio 应用程序,如果用户向您的 API 端点发出 POST 请求,他们可以绕过队列。要禁用此行为,请在 `queue()` 方法中设置 `api_open=False`。
|
||||
|
||||
## 鉴权
|
||||
|
||||
您可能希望在您的应用程序前面放置一个鉴权页面,以限制谁可以打开您的应用程序。使用 `launch()` 方法中的 `auth=` 关键字参数,您可以提供一个包含用户名和密码的元组,或者一个可接受的用户名 / 密码元组列表;以下是一个为单个名为“admin”的用户提供基于密码的身份验证的示例:
|
||||
|
||||
```python
|
||||
demo.launch(auth=("admin", "pass1234"))
|
||||
```
|
||||
|
||||
对于更复杂的身份验证处理,您甚至可以传递一个以用户名和密码作为参数的函数,并返回 True 以允许身份验证,否则返回 False。这可用于访问第三方身份验证服务等其他功能。
|
||||
|
||||
以下是一个接受任何用户名和密码相同的登录的函数示例:
|
||||
|
||||
```python
|
||||
def same_auth(username, password):
|
||||
return username == password
|
||||
demo.launch(auth=same_auth)
|
||||
```
|
||||
|
||||
为了使身份验证正常工作,必须在浏览器中启用第三方 Cookie。
|
||||
默认情况下,Safari、Chrome 隐私模式不会启用此功能。
|
||||
|
||||
## 直接访问网络请求
|
||||
|
||||
当用户向您的应用程序进行预测时,您可能需要底层的网络请求,以获取请求标头(例如用于高级身份验证)、记录客户端的 IP 地址或其他原因。Gradio 支持与 FastAPI 类似的方式:只需添加一个类型提示为 `gr.Request` 的函数参数,Gradio 将将网络请求作为该参数传递进来。以下是一个示例:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
def echo(name, request: gr.Request):
|
||||
if request:
|
||||
print("Request headers dictionary:", request.headers)
|
||||
print("IP address:", request.client.host)
|
||||
return name
|
||||
|
||||
io = gr.Interface(echo, "textbox", "textbox").launch()
|
||||
```
|
||||
|
||||
注意:如果直接调用函数而不是通过 UI(例如在缓存示例时),则 `request` 将为 `None`。您应该明确处理此情况,以确保您的应用程序不会抛出任何错误。这就是为什么我们有显式检查 `if request`。
|
||||
|
||||
## 嵌入到另一个 FastAPI 应用程序中
|
||||
|
||||
在某些情况下,您可能已经有一个现有的 FastAPI 应用程序,并且您想要为 Gradio 演示添加一个路径。
|
||||
您可以使用 `gradio.mount_gradio_app()` 来轻松实现此目的。
|
||||
|
||||
以下是一个完整的示例:
|
||||
|
||||
$code_custom_path
|
||||
|
||||
请注意,此方法还允许您在自定义路径上运行 Gradio 应用程序(例如上面的 `http://localhost:8000/gradio`)。
|
||||
|
||||
## 安全性和文件访问
|
||||
|
||||
与他人共享 Gradio 应用程序(通过 Spaces、您自己的服务器或临时共享链接进行托管)将主机机器上的某些文件**暴露**给您的 Gradio 应用程序的用户。
|
||||
|
||||
特别是,Gradio 应用程序允许用户访问以下三类文件:
|
||||
|
||||
* **与 Gradio 脚本所在目录(或子目录)中的文件相同。** 例如,如果您的 Gradio 脚本的路径是 `/home/usr/scripts/project/app.py`,并且您从 `/home/usr/scripts/project/` 启动它,则共享 Gradio 应用程序的用户将能够访问 `/home/usr/scripts/project/` 中的任何文件。这样做是为了您可以在 Gradio 应用程序中轻松引用这些文件(例如应用程序的“示例”)。
|
||||
|
||||
* **Gradio 创建的临时文件。** 这些是由 Gradio 作为运行您的预测函数的一部分创建的文件。例如,如果您的预测函数返回一个视频文件,则 Gradio 将该视频保存到临时文件中,然后将临时文件的路径发送到前端。您可以通过设置环境变量 `GRADIO_TEMP_DIR` 为绝对路径(例如 `/home/usr/scripts/project/temp/`)来自定义 Gradio 创建的临时文件的位置。
|
||||
|
||||
* **通过 `launch()` 中的 `allowed_paths` 参数允许的文件。** 此参数允许您传递一个包含其他目录或确切文件路径的列表,以允许用户访问它们。(默认情况下,此参数为空列表)。
|
||||
|
||||
Gradio**不允许**访问以下内容:
|
||||
|
||||
* **点文件**(其名称以 '.' 开头的任何文件)或其名称以 '.' 开头的任何目录中的任何文件。
|
||||
|
||||
* **通过 `launch()` 中的 `blocked_paths` 参数允许的文件。** 您可以将其他目录或确切文件路径的列表传递给 `launch()` 中的 `blocked_paths` 参数。此参数优先于 Gradio 默认或 `allowed_paths` 允许的文件。
|
||||
|
||||
* **主机机器上的任何其他路径**。用户不应能够访问主机上的其他任意路径。
|
||||
|
||||
请确保您正在运行最新版本的 `gradio`,以使这些安全设置生效。
|
||||
28
guides/cn/02_building-interfaces/01_interface-state.md
Normal file
@ -0,0 +1,28 @@
|
||||
# 接口状态 (Interface State)
|
||||
|
||||
本指南介绍了 Gradio 中如何处理状态。了解全局状态和会话状态的区别,以及如何同时使用它们。
|
||||
|
||||
## 全局状态 (Global State)
|
||||
|
||||
您的函数可能使用超出单个函数调用的持久性数据。如果数据是所有函数调用和所有用户都可访问的内容,您可以在函数调用外部创建一个变量,并在函数内部访问它。例如,您可能会在函数外部加载一个大模型,并在函数内部使用它,以便每个函数调用都不需要重新加载模型。
|
||||
|
||||
$code_score_tracker
|
||||
|
||||
在上面的代码中,'scores' 数组在所有用户之间共享。如果多个用户访问此演示,他们的得分将全部添加到同一列表中,并且返回的前 3 个得分将从此共享引用中收集。
|
||||
|
||||
## 全局状态 (Global State)
|
||||
|
||||
Gradio 支持的另一种数据持久性是会话状态,其中数据在页面会话中的多个提交之间持久存在。但是,不同用户之间的数据*不*共享。要将数据存储在会话状态中,需要执行以下三个步骤:
|
||||
|
||||
1. 将额外的参数传递给您的函数,表示接口的状态。
|
||||
2. 在函数的末尾,作为额外的返回值返回状态的更新值。
|
||||
3. 在创建界面时添加 `'state'` 输入和 `'state'` 输出组件。
|
||||
|
||||
聊天机器人就是需要会话状态的一个例子 - 您希望访问用户之前的提交,但不能将聊天记录存储在全局变量中,因为这样聊天记录会在不同用户之间混乱。
|
||||
|
||||
$code_chatbot_dialogpt
|
||||
$demo_chatbot_dialogpt
|
||||
|
||||
请注意,在每个页面中,状态在提交之间保持不变,但是如果在另一个标签中加载此演示(或刷新页面),演示将不共享聊天记录。
|
||||
|
||||
`state` 的默认值为 None。如果您将默认值传递给函数的状态参数,则该默认值将用作状态的默认值。`Interface` 类仅支持单个输入和输出状态变量,但可以是具有多个元素的列表。对于更复杂的用例,您可以使用 Blocks,[它支持多个 `State` 变量](/state_in_blocks/)。
|
||||
22
guides/cn/02_building-interfaces/02_reactive-interfaces.md
Normal file
@ -0,0 +1,22 @@
|
||||
# 反应式界面 (Reactive Interfaces)
|
||||
|
||||
本指南介绍了如何使 Gradio 界面自动刷新或连续流式传输数据。
|
||||
|
||||
## 实时界面 (Live Interfaces)
|
||||
|
||||
您可以通过在界面中设置 `live=True` 来使界面自动刷新。现在,只要用户输入发生变化,界面就会重新计算。
|
||||
|
||||
$code_calculator_live
|
||||
$demo_calculator_live
|
||||
|
||||
注意,因为界面在更改时会自动重新提交,所以没有提交按钮。
|
||||
|
||||
## 流式组件 (Streaming Components)
|
||||
|
||||
某些组件具有“流式”模式,比如麦克风模式下的 `Audio` 组件或网络摄像头模式下的 `Image` 组件。流式传输意味着数据会持续发送到后端,并且 `Interface` 函数会持续重新运行。
|
||||
|
||||
当在 `gr.Interface(live=True)` 中同时使用 `gr.Audio(source='microphone')` 和 `gr.Audio(source='microphone', streaming=True)` 时,两者的区别在于第一个 `Component` 会在用户停止录制时自动提交数据并运行 `Interface` 函数,而第二个 `Component` 会在录制过程中持续发送数据并运行 `Interface` 函数。
|
||||
|
||||
以下是从网络摄像头实时流式传输图像的示例代码。
|
||||
|
||||
$code_stream_frames
|
||||
40
guides/cn/02_building-interfaces/03_more-on-examples.md
Normal file
@ -0,0 +1,40 @@
|
||||
# 更多示例 (More on Examples)
|
||||
|
||||
本指南介绍了有关示例的更多内容:从目录中加载示例,提供部分示例和缓存。如果你对示例还不熟悉,请查看 [关键特性](../key-features/#example-inputs) 指南中的介绍。
|
||||
|
||||
## 提供示例 (Providing Examples)
|
||||
|
||||
正如 [关键特性](../key-features/#example-inputs) 指南中所介绍的,向接口添加示例就像提供一个列表的列表给 `examples` 关键字参数一样简单。
|
||||
每个子列表都是一个数据样本,其中每个元素对应于预测函数的一个输入。
|
||||
输入必须按照与预测函数期望的顺序排序。
|
||||
|
||||
如果你的接口只有一个输入组件,那么可以将示例提供为常规列表,而不是列表的列表。
|
||||
|
||||
### 从目录加载示例 (Loading Examples from a Directory)
|
||||
|
||||
你还可以指定一个包含示例的目录路径。如果你的接口只接受单个文件类型的输入(例如图像分类器),你只需将目录文件路径传递给 `examples=` 参数,`Interface` 将加载目录中的图像作为示例。
|
||||
对于多个输入,该目录必须包含一个带有示例值的 log.csv 文件。
|
||||
在计算器演示的上下文中,我们可以设置 `examples='/demo/calculator/examples'` ,在该目录中包含以下 `log.csv` 文件:
|
||||
contain a log.csv file with the example values.
|
||||
In the context of the calculator demo, we can set `examples='/demo/calculator/examples'` and in that directory we include the following `log.csv` file:
|
||||
```csv
|
||||
num,operation,num2
|
||||
5,"add",3
|
||||
4,"divide",2
|
||||
5,"multiply",3
|
||||
```
|
||||
|
||||
当浏览标记数据时,这将非常有用。只需指向标记目录,`Interface` 将从标记数据加载示例。
|
||||
|
||||
### 提供部分示例
|
||||
|
||||
有时你的应用程序有许多输入组件,但你只想为其中的一部分提供示例。为了在示例中排除某些输入,对于那些特定输入对应的所有数据样本都传递 `None`。
|
||||
|
||||
## 示例缓存 (Caching examples)
|
||||
|
||||
你可能希望为用户提供一些模型的缓存示例,以便他们可以快速尝试,以防您的模型运行时间较长。
|
||||
如果 `cache_examples=True` ,当你调用 `launch()` 方法时,`Interface` 将运行所有示例,并保存输出。这些数据将保存在一个名为 `gradio_cached_examples` 的目录中。
|
||||
|
||||
每当用户点击示例时,输出将自动填充到应用程序中,使用来自该缓存目录的数据,而不是实际运行函数。这对于用户可以快速尝试您的模型而不增加任何负载是非常有用的!
|
||||
|
||||
请记住一旦生成了缓存,它将不会在以后的启动中更新。如果示例或函数逻辑发生更改,请删除缓存文件夹以清除缓存并使用另一个 `launch()` 重新构建它。
|
||||
@ -0,0 +1,97 @@
|
||||
# 高级接口特性
|
||||
|
||||
在[接口 Interface](https://gradio.app/docs#interface)类上还有更多内容需要介绍。本指南涵盖了所有高级特性:使用[解释器 Interpretation](https://gradio.app/docs#interpretation),自定义样式,从[Hugging Face Hub](https://hf.co)加载模型,以及使用[并行 Parallel](https://gradio.app/docs#parallel)和[串行 Series](https://gradio.app/docs#series)。
|
||||
|
||||
## 解释您的预测
|
||||
|
||||
大多数模型都是黑盒模型,函数的内部逻辑对最终用户来说是隐藏的。为了鼓励透明度,我们通过在 `Interface` 类中简单地将 `interpretation` 关键字设置为 `default`,使得为模型添加解释非常容易。这样,您的用户就可以了解到哪些输入部分对输出结果负责。请看下面的简单界面示例,它展示了一个图像分类器,还包括解释功能:
|
||||
|
||||
$code_image_classifier_interpretation
|
||||
|
||||
除了 `default`,Gradio 还包括了基于[Shapley-based interpretation](https://christophm.github.io/interpretable-ml-book/shap.html),它提供了更准确的解释,尽管运行时间通常较慢。要使用它,只需将 `interpretation` 参数设置为 `"shap"`(注意:还要确保安装了 Python 包 `shap`)。您还可以选择修改 `num_shap` 参数,该参数控制准确性和运行时间之间的权衡(增加此值通常会增加准确性)。下面是一个示例:
|
||||
|
||||
```python
|
||||
gr.Interface(fn=classify_image, inputs=image, outputs=label, interpretation="shap", num_shap=5).launch()
|
||||
```
|
||||
|
||||
这适用于任何函数,即使在内部,模型是复杂的神经网络或其他黑盒模型。如果使用 Gradio 的 `default` 或 `shap` 解释,输出组件必须是 `Label`。支持所有常见的输入组件。下面是一个包含文本输入的示例。
|
||||
|
||||
$code_gender_sentence_default_interpretation
|
||||
|
||||
那么在幕后发生了什么?使用这些解释方法,Gradio 会使用修改后的输入的多个版本进行多次预测。根据结果,您将看到界面自动将增加类别可能性的文本部分(或图像等)以红色突出显示。颜色的强度对应于输入部分的重要性。减少类别置信度的部分以蓝色突出显示。
|
||||
|
||||
您还可以编写自己的解释函数。下面的演示在前一个演示中添加了自定义解释。此函数将使用与主封装函数相同的输入。该解释函数的输出将用于突出显示每个输入组件的输入-因此函数必须返回一个列表,其中元素的数量与输入组件的数量相对应。要查看每个输入组件的解释格式,请查阅文档。
|
||||
|
||||
$code_gender_sentence_custom_interpretation
|
||||
|
||||
在[文档](https://gradio.app/docs#interpretation)中了解更多关于解释的信息。
|
||||
|
||||
## 自定义样式
|
||||
|
||||
如果您希望对演示的任何方面都有更精细的控制,还可以编写自己的 CSS 或通过 `Interface` 类的 `css` 参数传递 CSS 文件的文件路径。
|
||||
|
||||
```python
|
||||
gr.Interface(..., css="body {background-color: red}")
|
||||
```
|
||||
|
||||
如果您希望在 CSS 中引用外部文件,请在文件路径(可以是相对路径或绝对路径)之前加上 `"file="`,例如:
|
||||
|
||||
```python
|
||||
gr.Interface(..., css="body {background-image: url('file=clouds.jpg')}")
|
||||
```
|
||||
|
||||
**警告**:不能保证自定义 CSS 能够在 Gradio 的不同版本之间正常工作,因为 Gradio 的 HTML DOM 可能会发生更改。我们建议尽量少使用自定义 CSS,而尽可能使用[主题 Themes](/theming-guide/)。
|
||||
|
||||
## 加载 Hugging Face 模型和 Spaces
|
||||
|
||||
Gradio 与[Hugging Face Hub](https://hf.co)完美集成,只需一行代码即可加载模型和 Spaces。要使用它,只需在 `Interface` 类中使用 `load()` 方法。所以:
|
||||
|
||||
- 要从 Hugging Face Hub 加载任何模型并围绕它创建一个界面,您需要传递 `"model/"` 或 `"huggingface/"`,后面跟着模型名称,就像这些示例一样:
|
||||
|
||||
```python
|
||||
gr.Interface.load("huggingface/gpt2").launch();
|
||||
```
|
||||
|
||||
```python
|
||||
gr.Interface.load("huggingface/EleutherAI/gpt-j-6B",
|
||||
inputs=gr.Textbox(lines=5, label="Input Text") # customizes the input component
|
||||
).launch()
|
||||
```
|
||||
|
||||
- 要从 Hugging Face Hub 加载任何 Space 并在本地重新创建它(这样您可以自定义输入和输出),您需要传递 `"spaces/"`,后面跟着模型名称:
|
||||
|
||||
```python
|
||||
gr.Interface.load("spaces/eugenesiow/remove-bg", inputs="webcam", title="Remove your webcam background!").launch()
|
||||
```
|
||||
|
||||
使用 Gradio 使用加载 Hugging Face 模型或 spaces 的一个很棒的功能是,您可以立即像 Python 代码中的函数一样使用生成的 `Interface` 对象(这适用于每种类型的模型 / 空间:文本,图像,音频,视频,甚至是多模态模型):
|
||||
|
||||
```python
|
||||
io = gr.Interface.load("models/EleutherAI/gpt-neo-2.7B")
|
||||
io("It was the best of times") # outputs model completion
|
||||
```
|
||||
|
||||
## 并行和串行放置接口
|
||||
|
||||
Gradio 还可以使用 `gradio.Parallel` 和 `gradio.Series` 类非常容易地混合接口。`Parallel` 允许您将两个相似的模型(如果它们具有相同的输入类型)并行放置以比较模型预测:
|
||||
|
||||
```python
|
||||
generator1 = gr.Interface.load("huggingface/gpt2")
|
||||
generator2 = gr.Interface.load("huggingface/EleutherAI/gpt-neo-2.7B")
|
||||
generator3 = gr.Interface.load("huggingface/EleutherAI/gpt-j-6B")
|
||||
|
||||
gr.Parallel(generator1, generator2, generator3).launch()
|
||||
```
|
||||
|
||||
`Series` 允许您将模型和 spaces 串行放置,将一个模型的输出传输到下一个模型的输入。
|
||||
|
||||
```python
|
||||
generator = gr.Interface.load("huggingface/gpt2")
|
||||
translator = gr.Interface.load("huggingface/t5-small")
|
||||
|
||||
gr.Series(generator, translator).launch() # this demo generates text, then translates it to German, and outputs the final result.
|
||||
```
|
||||
|
||||
当然,您还可以在适当的情况下同时使用 `Parallel` 和 `Series`!
|
||||
|
||||
在[文档](https://gradio.app/docs#parallel)中了解有关并行和串行 (`Parallel` 和 `Series`) 的更多信息。
|
||||
@ -0,0 +1,44 @@
|
||||
# Gradio 界面的 4 种类型
|
||||
|
||||
到目前为止,我们一直假设构建 Gradio 演示需要同时具备输入和输出。但对于机器学习演示来说,并不总是如此:例如,*无条件图像生成模型*不需要任何输入,但会生成一张图像作为输出。
|
||||
|
||||
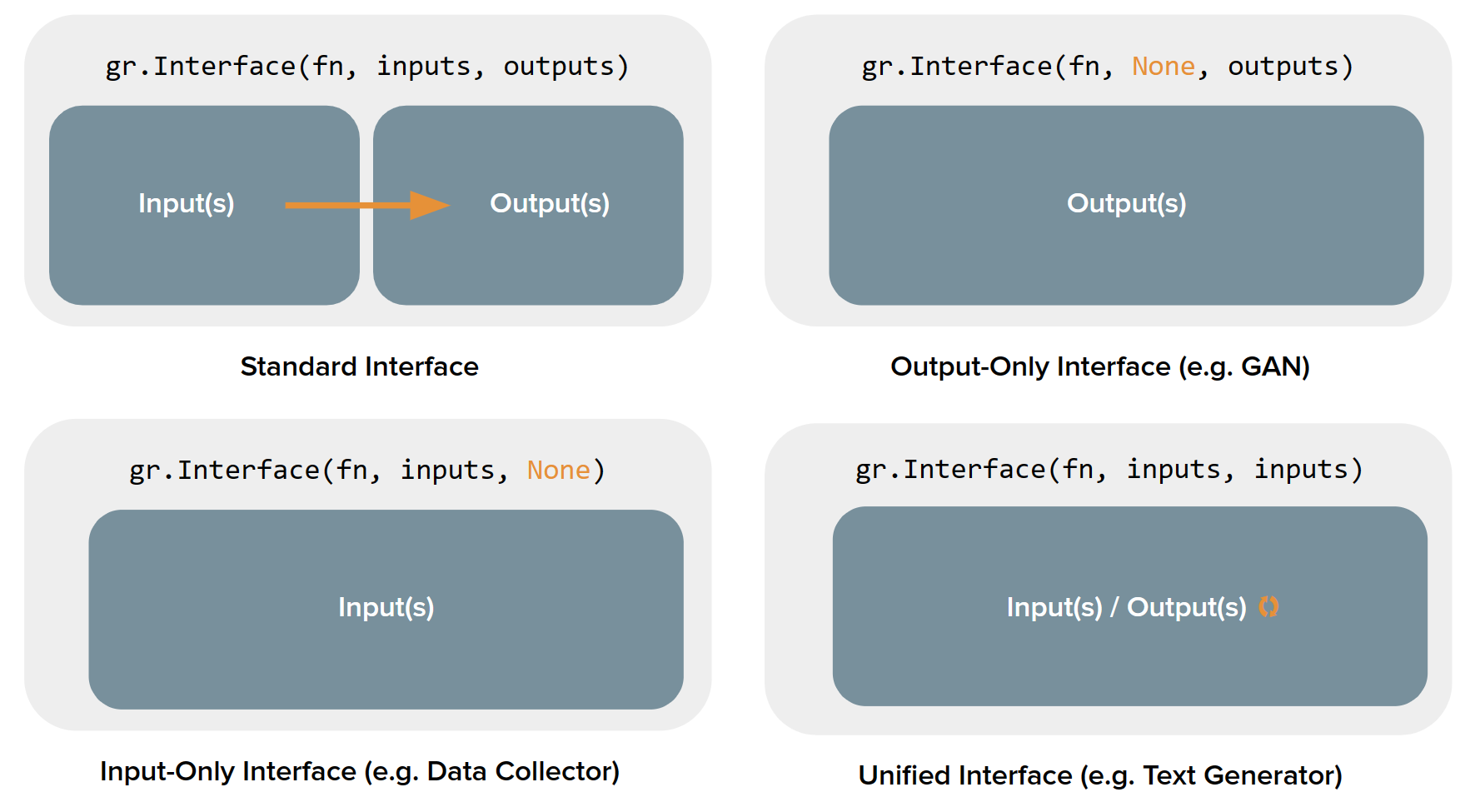
事实证明,`gradio.Interface` 类实际上可以处理 4 种不同类型的演示:
|
||||
|
||||
1. **Standard demos 标准演示**:同时具有独立的输入和输出(例如图像分类器或语音转文本模型)
|
||||
2. **Output-only demos 仅输出演示**:不接受任何输入,但会产生输出(例如无条件图像生成模型)
|
||||
3. **Input-only demos 仅输入演示**:不产生任何输出,但会接受某种形式的输入(例如保存您上传到外部持久数据库的图像的演示)
|
||||
4. **Unified demos 统一演示**:同时具有输入和输出组件,但这些组件是*相同的*。这意味着生成的输出将覆盖输入(例如文本自动完成模型)
|
||||
|
||||
根据演示类型的不同,用户界面(UI)会有略微不同的外观:
|
||||
|
||||
|
||||
|
||||
我们来看一下如何使用 `Interface` 类构建每种类型的演示,以及示例:
|
||||
|
||||
## 标准演示 (Standard demos)
|
||||
|
||||
要创建具有输入和输出组件的演示,只需在 `Interface()` 中设置 `inputs` 和 `outputs` 参数的值。以下是一个简单图像滤镜的示例演示:
|
||||
|
||||
$code_sepia_filter
|
||||
$demo_sepia_filter
|
||||
|
||||
## 仅输出演示 (Output-only demos)
|
||||
|
||||
那么仅包含输出的演示呢?为了构建这样的演示,只需将 `Interface()` 中的 `inputs` 参数值设置为 `None`。以下是模拟图像生成模型的示例演示:
|
||||
|
||||
$code_fake_gan_no_input
|
||||
$demo_fake_gan_no_input
|
||||
|
||||
## 仅输入演示 (Input-only demos)
|
||||
|
||||
同样地,要创建仅包含输入的演示,将 `Interface()` 中的 `outputs` 参数值设置为 `None`。以下是将任何上传的图像保存到磁盘的示例演示:
|
||||
|
||||
$code_save_file_no_output
|
||||
$demo_save_file_no_output
|
||||
|
||||
## 统一演示 (Unified demos)
|
||||
|
||||
这种演示将单个组件同时作为输入和输出。只需将 `Interface()` 中的 `inputs` 和 `outputs` 参数值设置为相同的组件即可创建此演示。以下是文本生成模型的示例演示:
|
||||
|
||||
$code_unified_demo_text_generation
|
||||
$demo_unified_demo_text_generation
|
||||
@ -0,0 +1,157 @@
|
||||
# 区块和事件监听器 (Blocks and Event Listeners)
|
||||
|
||||
我们在[快速入门](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)中简要介绍了区块。让我们深入探讨一下。本指南将涵盖区块的结构、事件监听器及其类型、连续运行事件、更新配置以及使用字典与列表。
|
||||
|
||||
## 区块结构 (Blocks Structure)
|
||||
|
||||
请查看下面的演示。
|
||||
|
||||
$code_hello_blocks
|
||||
$demo_hello_blocks
|
||||
|
||||
- 首先,注意 `with gr.Blocks() as demo:` 子句。区块应用程序代码将被包含在该子句中。
|
||||
- 接下来是组件。这些组件是在 `Interface` 中使用的相同组件。但是,与将组件传递给某个构造函数不同,组件在 `with` 子句内创建时会自动添加到区块中。
|
||||
- 最后,`click()` 事件监听器。事件监听器定义了应用程序内的数据流。在上面的示例中,监听器将两个文本框相互关联。文本框 `name` 作为输入,文本框 `output` 作为 `greet` 方法的输出。当单击按钮 `greet_btn` 时触发此数据流。与界面类似,事件监听器可以具有多个输入或输出。
|
||||
|
||||
## 事件监听器与交互性 (Event Listeners and Interactivity)
|
||||
|
||||
在上面的示例中,您会注意到可以编辑文本框 `name`,但无法编辑文本框 `output`。这是因为作为事件监听器的任何组件都具有交互性。然而,由于文本框 `output` 仅作为输出,它没有交互性。您可以使用 `interactive=` 关键字参数直接配置组件的交互性。
|
||||
|
||||
```python
|
||||
output = gr.Textbox(label="输出", interactive=True)
|
||||
```
|
||||
|
||||
## 事件监听器的类型 (Types of Event Listeners)
|
||||
|
||||
请查看下面的演示:
|
||||
|
||||
$code_blocks_hello
|
||||
$demo_blocks_hello
|
||||
|
||||
`welcome` 函数不是由点击触发的,而是由在文本框 `inp` 中输入文字触发的。这是由于 `change()` 事件监听器。不同的组件支持不同的事件监听器。例如,`Video` 组件支持一个 `play()` 事件监听器,当用户按下播放按钮时触发。有关每个组件的事件监听器,请参见[文档](http://gradio.app/docs#components)。
|
||||
|
||||
## 多个数据流 (Multiple Data Flows)
|
||||
|
||||
区块应用程序不像界面那样限制于单个数据流。请查看下面的演示:
|
||||
|
||||
$code_reversible_flow
|
||||
$demo_reversible_flow
|
||||
|
||||
请注意,`num1` 可以充当 `num2` 的输入,反之亦然!随着应用程序变得更加复杂,您将能够连接各种组件的多个数据流。
|
||||
|
||||
下面是一个 " 多步骤 " 示例,其中一个模型的输出(语音到文本模型)被传递给下一个模型(情感分类器)。
|
||||
|
||||
$code_blocks_speech_text_sentiment
|
||||
$demo_blocks_speech_text_sentiment
|
||||
|
||||
## 函数输入列表与字典 (Function Input List vs Dict)
|
||||
|
||||
到目前为止,您看到的事件监听器都只有一个输入组件。如果您希望有多个输入组件将数据传递给函数,有两种选项可供函数接受输入组件值:
|
||||
|
||||
1. 作为参数列表,或
|
||||
2. 作为以组件为键的单个值字典
|
||||
|
||||
让我们分别看一个例子:
|
||||
$code_calculator_list_and_dict
|
||||
|
||||
`add()` 和 `sub()` 都将 `a` 和 `b` 作为输入。然而,这些监听器之间的语法不同。
|
||||
|
||||
1. 对于 `add_btn` 监听器,我们将输入作为列表传递。函数 `add()` 将每个输入作为参数。`a` 的值映射到参数 `num1`,`b` 的值映射到参数 `num2`。
|
||||
2. 对于 `sub_btn` 监听器,我们将输入作为集合传递(注意花括号!)。函数 `sub()` 接受一个名为 `data` 的单个字典参数,其中键是输入组件,值是这些组件的值。
|
||||
|
||||
使用哪种语法是个人偏好!对于具有许多输入组件的函数,选项 2 可能更容易管理。
|
||||
|
||||
$demo_calculator_list_and_dict
|
||||
|
||||
## 函数返回列表与字典 (Function Return List vs Dict)
|
||||
|
||||
类似地,您可以返回多个输出组件的值,可以是:
|
||||
|
||||
1. 值列表,或
|
||||
2. 以组件为键的字典
|
||||
|
||||
首先让我们看一个(1)的示例,其中我们通过返回两个值来设置两个输出组件的值:
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
food_box = gr.Number(value=10, label="Food Count")
|
||||
status_box = gr.Textbox()
|
||||
def eat(food):
|
||||
if food > 0:
|
||||
return food - 1, "full"
|
||||
else:
|
||||
return 0, "hungry"
|
||||
gr.Button("EAT").click(
|
||||
fn=eat,
|
||||
inputs=food_box,
|
||||
outputs=[food_box, status_box]
|
||||
)
|
||||
```
|
||||
|
||||
上面的每个返回语句分别返回与 `food_box` 和 `status_box` 相对应的两个值。
|
||||
|
||||
除了返回与每个输出组件顺序相对应的值列表外,您还可以返回一个字典,其中键对应于输出组件,值作为新值。这还允许您跳过更新某些输出组件。
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
food_box = gr.Number(value=10, label="Food Count")
|
||||
status_box = gr.Textbox()
|
||||
def eat(food):
|
||||
if food > 0:
|
||||
return {food_box: food - 1, status_box: "full"}
|
||||
else:
|
||||
return {status_box: "hungry"}
|
||||
gr.Button("EAT").click(
|
||||
fn=eat,
|
||||
inputs=food_box,
|
||||
outputs=[food_box, status_box]
|
||||
)
|
||||
```
|
||||
|
||||
注意,在没有食物的情况下,我们只更新 `status_box` 元素。我们跳过更新 `food_box` 组件。
|
||||
|
||||
字典返回在事件监听器影响多个组件的返回值或有条件地影响输出时非常有用。
|
||||
|
||||
请记住,对于字典返回,我们仍然需要在事件监听器中指定可能的输出组件。
|
||||
|
||||
## 更新组件配置 (Updating Component Configurations)
|
||||
|
||||
事件监听器函数的返回值通常是相应输出组件的更新值。有时我们还希望更新组件的配置,例如可见性。在这种情况下,我们返回一个 `gr.update()` 对象,而不仅仅是更新组件的值。
|
||||
|
||||
$code_blocks_essay_update
|
||||
$demo_blocks_essay_update
|
||||
|
||||
请注意,我们可以通过 `gr.update()` 方法自我配置文本框。`value=` 参数仍然可以用于更新值以及组件配置。
|
||||
|
||||
## 连续运行事件 (Running Events Consecutively)
|
||||
|
||||
你也可以使用事件监听器的 `then` 方法按顺序运行事件。在前一个事件运行完成后,这将运行下一个事件。这对于多步更新组件的事件非常有用。
|
||||
|
||||
例如,在下面的聊天机器人示例中,我们首先立即使用用户消息更新聊天机器人,然后在模拟延迟后使用计算机回复更新聊天机器人。
|
||||
|
||||
$code_chatbot_simple
|
||||
$demo_chatbot_simple
|
||||
|
||||
事件监听器的 `.then()` 方法会执行后续事件,无论前一个事件是否引发任何错误。如果只想在前一个事件成功执行后才运行后续事件,请使用 `.success()` 方法,该方法与 `.then()` 接受相同的参数。
|
||||
|
||||
## 连续运行事件 (Running Events Continuously)
|
||||
|
||||
您可以使用事件监听器的 `every` 参数按固定计划运行事件。这将在客户端连接打开的情况下,每隔一定秒数运行一次事件。如果连接关闭,事件将在下一次迭代后停止运行。
|
||||
请注意,这不考虑事件本身的运行时间。因此,使用 `every=5` 运行时间为 1 秒的函数实际上每 6 秒运行一次。
|
||||
|
||||
以下是每秒更新的正弦曲线示例!
|
||||
|
||||
$code_sine_curve
|
||||
$demo_sine_curve
|
||||
|
||||
## 收集事件数据 (Gathering Event Data)
|
||||
|
||||
您可以通过将相关的事件数据类作为类型提示添加到事件监听器函数的参数中,收集有关事件的特定数据。
|
||||
|
||||
例如,使用 `gradio.SelectData` 参数可以为 `.select()` 的事件数据添加类型提示。当用户选择触发组件的一部分时,将触发此事件,并且事件数据包含有关用户的具体选择的信息。如果用户在 `Textbox` 中选择了特定单词,在 `Gallery` 中选择了特定图像或在 `DataFrame` 中选择了特定单元格,则事件数据参数将包含有关具体选择的信息。
|
||||
|
||||
在下面的双人井字游戏演示中,用户可以选择 `DataFrame` 中的一个单元格进行移动。事件数据参数包含有关所选单元格的信息。我们可以首先检查单元格是否为空,然后用用户的移动更新单元格。
|
||||
|
||||
$code_tictactoe
|
||||
|
||||
$demo_tictactoe
|
||||
95
guides/cn/03_building-with-blocks/02_controlling-layout.md
Normal file
@ -0,0 +1,95 @@
|
||||
# 控制布局 (Controlling Layout)
|
||||
|
||||
默认情况下,块中的组件是垂直排列的。让我们看看如何重新排列组件。在幕后,这种布局结构使用了[Web 开发的 flexbox 模型](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox)。
|
||||
|
||||
## Row 行
|
||||
|
||||
`with gr.Row` 下的元素将水平显示。例如,要并排显示两个按钮:
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
btn1 = gr.Button("按钮1")
|
||||
btn2 = gr.Button("按钮2")
|
||||
```
|
||||
|
||||
要使行中的每个元素具有相同的高度,请使用 `style` 方法的 `equal_height` 参数。
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row().style(equal_height=True):
|
||||
textbox = gr.Textbox()
|
||||
btn2 = gr.Button("按钮2")
|
||||
```
|
||||
|
||||
可以通过每个组件中存在的 `scale` 和 `min_width` 参数来控制行中元素的宽度。
|
||||
|
||||
- `scale` 是一个整数,定义了元素在行中的占用空间。如果将 scale 设置为 `0`,则元素不会扩展占用空间。如果将 scale 设置为 `1` 或更大,则元素将扩展。行中的多个元素将按比例扩展。在下面的示例中,`btn1` 将比 `btn2` 扩展两倍,而 `btn0` 将根本不会扩展:
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
btn0 = gr.Button("按钮0", scale=0)
|
||||
btn1 = gr.Button("按钮1", scale=1)
|
||||
btn2 = gr.Button("按钮2", scale=2)
|
||||
```
|
||||
|
||||
- `min_width` 将设置元素的最小宽度。如果没有足够的空间满足所有的 `min_width` 值,行将换行。
|
||||
|
||||
在[文档](https://gradio.app/docs/#row)中了解有关行的更多信息。
|
||||
|
||||
## 列和嵌套 (Columns and Nesting)
|
||||
|
||||
列中的组件将垂直放置在一起。由于默认布局对于块应用程序来说是垂直布局,因此为了有用,列通常嵌套在行中。例如:
|
||||
|
||||
$code_rows_and_columns
|
||||
$demo_rows_and_columns
|
||||
|
||||
查看第一列如何垂直排列两个文本框。第二列垂直排列图像和按钮。注意两列的相对宽度由 `scale` 参数设置。具有两倍 `scale` 值的列占据两倍的宽度。
|
||||
|
||||
在[文档](https://gradio.app/docs/#column)中了解有关列的更多信息。
|
||||
|
||||
## 选项卡和手风琴 (Tabs and Accordions)
|
||||
|
||||
您还可以使用 `with gr.Tab('tab_name'):` 语句创建选项卡。在 `with gr.Tab('tab_name'):` 上下文中创建的任何组件都将显示在该选项卡中。连续的 Tab 子句被分组在一起,以便一次只能选择一个选项卡,并且只显示该选项卡上下文中的组件。
|
||||
|
||||
例如:
|
||||
|
||||
$code_blocks_flipper
|
||||
$demo_blocks_flipper
|
||||
|
||||
还请注意本示例中的 `gr.Accordion('label')`。手风琴是一种可以切换打开或关闭的布局。与 `Tabs` 一样,它是可以选择性隐藏或显示内容的布局元素。在 `with gr.Accordion('label'):` 内定义的任何组件在单击手风琴的切换图标时都会被隐藏或显示。
|
||||
|
||||
在文档中了解有关[Tabs](https://gradio.app/docs/#tab)和[Accordions](https://gradio.app/docs/#accordion)的更多信息。
|
||||
|
||||
## 可见性 (Visibility)
|
||||
|
||||
组件和布局元素都有一个 `visible` 参数,可以在初始时设置,并使用 `gr.update()` 进行更新。在 Column 上设置 `gr.update(visible=...)` 可用于显示或隐藏一组组件。
|
||||
|
||||
$code_blocks_form
|
||||
$demo_blocks_form
|
||||
|
||||
## 可变数量的输出 (Variable Number of Outputs)
|
||||
|
||||
通过以动态方式调整组件的可见性,可以创建支持 *可变数量输出* 的 Gradio 演示。这是一个非常简单的例子,其中输出文本框的数量由输入滑块控制:
|
||||
|
||||
例如:
|
||||
|
||||
$code_variable_outputs
|
||||
$demo_variable_outputs
|
||||
|
||||
## 分开定义和渲染组件 (Defining and Rendering Components Separately)
|
||||
|
||||
在某些情况下,您可能希望在实际渲染 UI 之前定义组件。例如,您可能希望在相应的 `gr.Textbox` 输入上方显示示例部分,使用 `gr.Examples`。由于 `gr.Examples` 需要一个参数作为输入组件对象,您需要先定义输入组件,然后在定义 `gr.Examples` 对象之后再渲染它。
|
||||
|
||||
解决方法是在 `gr.Blocks()` 范围之外定义 `gr.Textbox`,并在 UI 中想要放置它的位置使用组件的 `.render()` 方法。
|
||||
|
||||
这是一个完整的代码示例:
|
||||
|
||||
```python
|
||||
input_textbox = gr.Textbox()
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.Examples(["hello", "bonjour", "merhaba"], input_textbox)
|
||||
input_textbox.render()
|
||||
```
|
||||
30
guides/cn/03_building-with-blocks/03_state-in-blocks.md
Normal file
@ -0,0 +1,30 @@
|
||||
# 分块状态 (State in Blocks)
|
||||
|
||||
我们已经介绍了[接口状态](https://gradio.app/interface-state),这篇指南将介绍分块状态,它的工作原理大致相同。
|
||||
|
||||
## 全局状态 (Global State)
|
||||
|
||||
分块中的全局状态与接口中的全局状态相同。在函数调用外创建的任何变量都是在所有用户之间共享的引用。
|
||||
|
||||
## 会话状态 (Session State)
|
||||
|
||||
Gradio 在分块应用程序中同样支持会话**状态**,即在页面会话中跨多次提交保持的数据。需要再次强调,会话数据*不会*在模型的不同用户之间共享。要在会话状态中存储数据,需要完成以下三个步骤:
|
||||
|
||||
1. 创建一个 `gr.State()` 对象。如果此可状态对象有一个默认值,请将其传递给构造函数。
|
||||
2. 在事件监听器中,将 `State` 对象作为输入和输出。
|
||||
3. 在事件监听器函数中,将变量添加到输入参数和返回值中。
|
||||
|
||||
让我们来看一个猜词游戏的例子。
|
||||
|
||||
$code_hangman
|
||||
$demo_hangman
|
||||
|
||||
让我们看看在这个游戏中如何完成上述的 3 个步骤:
|
||||
|
||||
1. 我们将已使用的字母存储在 `used_letters_var` 中。在 `State` 的构造函数中,将其初始值设置为空列表`[]`。
|
||||
2. 在 `btn.click()` 中,我们在输入和输出中都引用了 `used_letters_var`。
|
||||
3. 在 `guess_letter` 中,我们将此 `State` 的值传递给 `used_letters`,然后在返回语句中返回更新后的该 `State` 的值。
|
||||
|
||||
对于更复杂的应用程序,您可能会在一个单独的分块应用程序中使用许多存储会话状态的 `State` 变量。
|
||||
|
||||
在[文档](https://gradio.app/docs#state)中了解更多关于 `State` 的信息。
|
||||
57
guides/cn/03_building-with-blocks/04_custom-CSS-and-JS.md
Normal file
@ -0,0 +1,57 @@
|
||||
# 自定义的 JS 和 CSS
|
||||
|
||||
本指南介绍了如何更灵活地为 Blocks 添加样式,并添加 JavaScript 代码到事件监听器中。
|
||||
|
||||
**警告**:在自定义的 JS 和 CSS 中使用查询选择器不能保证能在所有 Gradio 版本中正常工作,因为 Gradio 的 HTML DOM 可能会发生变化。我们建议谨慎使用查询选择器。
|
||||
|
||||
## 自定义的 CSS
|
||||
|
||||
Gradio 主题是自定义应用程序外观和感觉的最简单方式。您可以从各种主题中进行选择,或者创建自己的主题。要实现这一点,请将 `theme=` kwarg 传递给 `Blocks` 构造函数。例如:
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Glass()):
|
||||
...
|
||||
```
|
||||
|
||||
Gradio 自带一套预构建的主题,您可以从 `gr.themes.*` 中加载这些主题。您可以扩展这些主题,或者从头开始创建自己的主题 - 有关更多详细信息,请参阅[主题指南](/theming-guide)。
|
||||
|
||||
要增加附加的样式能力,您可以使用 `css=` kwarg 将任何 CSS 传递给您的应用程序。
|
||||
|
||||
Gradio 应用程序的基类是 `gradio-container`,因此下面是一个示例,用于更改 Gradio 应用程序的背景颜色:
|
||||
```python
|
||||
with gr.Blocks(css=".gradio-container {background-color: red}") as demo:
|
||||
...
|
||||
```
|
||||
|
||||
如果您想在您的 CSS 中引用外部文件,请使用 `"file="` 作为文件路径的前缀(可以是相对路径或绝对路径),例如:
|
||||
|
||||
```python
|
||||
with gr.Blocks(css=".gradio-container {background: url('file=clouds.jpg')}") as demo:
|
||||
...
|
||||
```
|
||||
|
||||
您还可以将 CSS 文件的文件路径传递给 `css` 参数。
|
||||
|
||||
## `elem_id` 和 `elem_classes` 参数
|
||||
|
||||
您可以使用 `elem_id` 来为任何组件添加 HTML 元素 `id`,并使用 `elem_classes` 添加一个类或类列表。这将使您能够更轻松地使用 CSS 选择元素。这种方法更有可能在 Gradio 版本之间保持稳定,因为内置的类名或 id 可能会发生变化(但正如上面的警告中所提到的,如果您使用自定义 CSS,我们不能保证在 Gradio 版本之间完全兼容,因为 DOM 元素本身可能会发生变化)。
|
||||
|
||||
```python
|
||||
css = """
|
||||
#warning {background-color: #FFCCCB}
|
||||
.feedback textarea {font-size: 24px !important}
|
||||
"""
|
||||
|
||||
with gr.Blocks(css=css) as demo:
|
||||
box1 = gr.Textbox(value="Good Job", elem_classes="feedback")
|
||||
box2 = gr.Textbox(value="Failure", elem_id="warning", elem_classes="feedback")
|
||||
```
|
||||
|
||||
CSS `#warning` 规则集仅针对第二个文本框,而 `.feedback` 规则集将同时作用于两个文本框。请注意,在针对类时,您可能需要使用 `!important` 选择器来覆盖默认的 Gradio 样式。
|
||||
|
||||
## 自定义的 JS
|
||||
|
||||
事件监听器具有 `_js` 参数,可以接受 JavaScript 函数作为字符串,并像 Python 事件监听器函数一样处理它。您可以传递 JavaScript 函数和 Python 函数(在这种情况下,先运行 JavaScript 函数),或者仅传递 JavaScript(并将 Python 的 `fn` 设置为 `None`)。请查看下面的代码:
|
||||
|
||||
$code_blocks_js_methods
|
||||
$demo_blocks_js_methods
|
||||
@ -0,0 +1,89 @@
|
||||
# 使用 Gradio 块像函数一样
|
||||
Tags: TRANSLATION, HUB, SPACES
|
||||
|
||||
**先决条件**: 本指南是在块介绍的基础上构建的。请确保[先阅读该指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)。
|
||||
|
||||
## 介绍
|
||||
|
||||
你知道吗,除了作为一个全栈机器学习演示,Gradio 块应用其实也是一个普通的 Python 函数!?
|
||||
|
||||
这意味着如果你有一个名为 `demo` 的 Gradio 块(或界面)应用,你可以像使用任何 Python 函数一样使用 `demo`。
|
||||
|
||||
所以,像 `output = demo("Hello", "friend")` 这样的操作会在输入为 "Hello" 和 "friend" 的情况下运行 `demo` 中定义的第一个事件,并将其存储在变量 `output` 中。
|
||||
|
||||
如果以上内容让你打瞌睡 🥱,请忍耐一下!通过将应用程序像函数一样使用,你可以轻松地组合 Gradio 应用。
|
||||
接下来的部分将展示如何实现。
|
||||
|
||||
## 将块视为函数
|
||||
|
||||
假设我们有一个将英文文本翻译为德文文本的演示块。
|
||||
|
||||
$code_english_translator
|
||||
|
||||
我已经将它托管在 Hugging Face Spaces 上的 [gradio/english_translator](https://huggingface.co/spaces/gradio/english_translator)。
|
||||
|
||||
你也可以在下面看到演示:
|
||||
|
||||
$demo_english_translator
|
||||
|
||||
现在,假设你有一个生成英文文本的应用程序,但你还想额外生成德文文本。
|
||||
|
||||
你可以选择:
|
||||
|
||||
1. 将我的英德翻译的源代码复制粘贴到你的应用程序中。
|
||||
|
||||
2. 在你的应用程序中加载我的英德翻译,并将其当作普通的 Python 函数处理。
|
||||
|
||||
选项 1 从技术上讲总是有效的,但它经常引入不必要的复杂性。
|
||||
|
||||
选项 2 允许你借用所需的功能,而不会过于紧密地耦合我们的应用程序。
|
||||
|
||||
你只需要在源文件中调用 `Blocks.load` 类方法即可。
|
||||
之后,你就可以像使用普通的 Python 函数一样使用我的翻译应用程序了!
|
||||
|
||||
下面的代码片段和演示展示了如何使用 `Blocks.load`。
|
||||
|
||||
请注意,变量 `english_translator` 是我的英德翻译应用程序,但它在 `generate_text` 中像普通函数一样使用。
|
||||
|
||||
$code_generate_english_german
|
||||
|
||||
$demo_generate_english_german
|
||||
|
||||
## 如何控制使用应用程序中的哪个函数
|
||||
|
||||
如果你正在加载的应用程序定义了多个函数,你可以使用 `fn_index` 和 `api_name` 参数指定要使用的函数。
|
||||
|
||||
在英德演示的代码中,你会看到以下代码行:
|
||||
|
||||
translate_btn.click(translate, inputs=english, outputs=german, api_name="translate-to-german")
|
||||
|
||||
这个 `api_name` 在我们的应用程序中给这个函数一个唯一的名称。你可以使用这个名称告诉 Gradio 你想使用
|
||||
上游空间中的哪个函数:
|
||||
|
||||
english_generator(text, api_name="translate-to-german")[0]["generated_text"]
|
||||
|
||||
你也可以使用 `fn_index` 参数。
|
||||
假设我的应用程序还定义了一个英语到西班牙语的翻译函数。
|
||||
为了在我们的文本生成应用程序中使用它,我们将使用以下代码:
|
||||
|
||||
english_generator(text, fn_index=1)[0]["generated_text"]
|
||||
|
||||
Gradio 空间中的函数是从零开始索引的,所以西班牙语翻译器将是我的空间中的第二个函数,
|
||||
因此你会使用索引 1。
|
||||
|
||||
## 结语
|
||||
|
||||
我们展示了将块应用视为普通 Python 函数的方法,这有助于在不同的应用程序之间组合功能。
|
||||
任何块应用程序都可以被视为一个函数,但一个强大的模式是在将其视为函数之前,
|
||||
在[自己的应用程序中加载](https://huggingface.co/spaces)托管在[Hugging Face Spaces](https://huggingface.co/spaces)上的应用程序。
|
||||
您也可以加载托管在[Hugging Face Model Hub](https://huggingface.co/models)上的模型——有关示例,请参阅[使用 Hugging Face 集成](/using_hugging_face_integrations)指南。
|
||||
|
||||
### 开始构建!⚒️
|
||||
|
||||
## Parting Remarks
|
||||
|
||||
我们展示了如何将 Blocks 应用程序视为常规 Python 函数,以便在不同的应用程序之间组合功能。
|
||||
任何 Blocks 应用程序都可以被视为函数,但是一种有效的模式是在将其视为自己应用程序的函数之前,先`加载`托管在[Hugging Face Spaces](https://huggingface.co/spaces)上的应用程序。
|
||||
您还可以加载托管在[Hugging Face Model Hub](https://huggingface.co/models)上的模型-请参见[使用 Hugging Face 集成指南](/using_hugging_face_integrations)中的示例。
|
||||
|
||||
### Happy building! ⚒️
|
||||
@ -0,0 +1,135 @@
|
||||
# 使用 Hugging Face 集成
|
||||
|
||||
相关空间:https://huggingface.co/spaces/gradio/helsinki_translation_en_es
|
||||
标签:HUB,SPACES,EMBED
|
||||
|
||||
由 <a href="https://huggingface.co/osanseviero">Omar Sanseviero</a> 贡献🦙
|
||||
|
||||
## 介绍
|
||||
|
||||
Hugging Face Hub 是一个集成平台,拥有超过 190,000 个[模型](https://huggingface.co/models),32,000 个[数据集](https://huggingface.co/datasets)和 40,000 个[演示](https://huggingface.co/spaces),也被称为 Spaces。虽然 Hugging Face 以其🤗 transformers 和 diffusers 库而闻名,但 Hub 还支持许多机器学习库,如 PyTorch,TensorFlow,spaCy 等,涵盖了从计算机视觉到强化学习等各个领域。
|
||||
|
||||
Gradio 拥有多个功能,使其非常容易利用 Hub 上的现有模型和 Spaces。本指南将介绍这些功能。
|
||||
|
||||
## 使用 `pipeline` 进行常规推理
|
||||
|
||||
首先,让我们构建一个简单的界面,将英文翻译成西班牙文。在赫尔辛基大学共享的一千多个模型中,有一个[现有模型](https://huggingface.co/Helsinki-NLP/opus-mt-en-es),名为 `opus-mt-en-es`,可以正好做到这一点!
|
||||
|
||||
🤗 transformers 库有一个非常易于使用的抽象层,[`pipeline()`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/pipelines#transformers.pipeline)处理大部分复杂代码,为常见任务提供简单的 API。通过指定任务和(可选)模型,您可以使用几行代码使用现有模型:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
|
||||
|
||||
def predict(text):
|
||||
return pipe(text)[0]["translation_text"]
|
||||
|
||||
demo = gr.Interface(
|
||||
fn=predict,
|
||||
inputs='text',
|
||||
outputs='text',
|
||||
)
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
但是,`gradio` 实际上使将 `pipeline` 转换为演示更加容易,只需使用 `gradio.Interface.from_pipeline` 方法,无需指定输入和输出组件:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
import gradio as gr
|
||||
|
||||
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
|
||||
|
||||
demo = gr.Interface.from_pipeline(pipe)
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
上述代码生成了以下界面,您可以在浏览器中直接尝试:
|
||||
|
||||
<gradio-app space="Helsinki-NLP/opus-mt-en-es"></gradio-app>
|
||||
|
||||
## Using Hugging Face Inference API
|
||||
|
||||
Hugging Face 提供了一个名为[Inference API](https://huggingface.co/inference-api)的免费服务,允许您向 Hub 中的模型发送 HTTP 请求。对于基于 transformers 或 diffusers 的模型,API 的速度可以比自己运行推理快 2 到 10 倍。该 API 是免费的(受速率限制),您可以在想要在生产中使用时切换到专用的[推理端点](https://huggingface.co/pricing)。
|
||||
|
||||
让我们尝试使用推理 API 而不是自己加载模型的方式进行相同的演示。鉴于 Inference API 支持的 Hugging Face 模型,Gradio 可以自动推断出预期的输入和输出,并进行底层服务器调用,因此您不必担心定义预测函数。以下是代码示例!
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
demo = gr.load("Helsinki-NLP/opus-mt-en-es", src="models")
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
请注意,我们只需指定模型名称并说明 `src` 应为 `models`(Hugging Face 的 Model Hub)。由于您不会在计算机上加载模型,因此无需安装任何依赖项(除了 `gradio`)。
|
||||
|
||||
您可能会注意到,第一次推理大约需要 20 秒。这是因为推理 API 正在服务器中加载模型。之后您会获得一些好处:
|
||||
|
||||
* 推理速度更快。
|
||||
* 服务器缓存您的请求。
|
||||
* 您获得内置的自动缩放功能。
|
||||
|
||||
## 托管您的 Gradio 演示
|
||||
|
||||
[Hugging Face Spaces](https://hf.co/spaces)允许任何人免费托管其 Gradio 演示,上传 Gradio 演示只需几分钟。您可以前往[hf.co/new-space](https://huggingface.co/new-space),选择 Gradio SDK,创建一个 `app.py` 文件,完成!您将拥有一个可以与任何人共享的演示。要了解更多信息,请阅读[此指南以使用网站在 Hugging Face Spaces 上托管](https://huggingface.co/blog/gradio-spaces)。
|
||||
|
||||
或者,您可以通过使用[huggingface_hub client library](https://huggingface.co/docs/huggingface_hub/index)库来以编程方式创建一个 Space。这是一个示例:
|
||||
|
||||
```python
|
||||
from huggingface_hub import (
|
||||
create_repo,
|
||||
get_full_repo_name,
|
||||
upload_file,
|
||||
)
|
||||
create_repo(name=target_space_name, token=hf_token, repo_type="space", space_sdk="gradio")
|
||||
repo_name = get_full_repo_name(model_id=target_space_name, token=hf_token)
|
||||
file_url = upload_file(
|
||||
path_or_fileobj="file.txt",
|
||||
path_in_repo="app.py",
|
||||
repo_id=repo_name,
|
||||
repo_type="space",
|
||||
token=hf_token,
|
||||
)
|
||||
```
|
||||
在这里,`create_repo` 使用特定帐户的 Write Token 在特定帐户下创建一个带有目标名称的 gradio repo。`repo_name` 获取相关存储库的完整存储库名称。最后,`upload_file` 将文件上传到存储库中,并将其命名为 `app.py`。
|
||||
|
||||
## 在其他网站上嵌入您的 Space 演示
|
||||
|
||||
在本指南中,您已经看到了许多嵌入的 Gradio 演示。您也可以在自己的网站上这样做!第一步是创建一个包含您想展示的演示的 Hugging Face Space。然后,[按照此处的步骤将 Space 嵌入到您的网站上](/sharing-your-app/#embedding-hosted-spaces)。
|
||||
|
||||
## 从 Spaces 加载演示
|
||||
|
||||
您还可以在 Hugging Face Spaces 上使用和混合现有的 Gradio 演示。例如,您可以将两个现有的 Gradio 演示放在单独的选项卡中并创建一个新的演示。您可以在本地运行此新演示,或将其上传到 Spaces,为混合和创建新的演示提供无限可能性!
|
||||
|
||||
以下是一个完全实现此目标的示例:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Tab("Translate to Spanish"):
|
||||
gr.load("gradio/helsinki_translation_en_es", src="spaces")
|
||||
with gr.Tab("Translate to French"):
|
||||
gr.load("abidlabs/en2fr", src="spaces")
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
请注意,我们使用了 `gr.load()`,这与使用推理 API 加载模型所使用的方法相同。但是,在这里,我们指定 `src` 为 `spaces`(Hugging Face Spaces)。
|
||||
|
||||
## 小结
|
||||
|
||||
就是这样!让我们回顾一下 Gradio 和 Hugging Face 共同工作的各种方式:
|
||||
|
||||
1. 您可以使用 `from_pipeline()` 将 `transformers` pipeline 转换为 Gradio 演示
|
||||
2. 您可以使用 `gr.load()` 轻松地围绕推理 API 构建演示,而无需加载模型
|
||||
3. 您可以在 Hugging Face Spaces 上托管您的 Gradio 演示,可以使用 GUI 或完全使用 Python。
|
||||
4. 您可以将托管在 Hugging Face Spaces 上的 Gradio 演示嵌入到自己的网站上。
|
||||
5. 您可以使用 `gr.load()` 从 Hugging Face Spaces 加载演示,以重新混合和创建新的 Gradio 演示。
|
||||
|
||||
🤗
|
||||
269
guides/cn/04_integrating-other-frameworks/Gradio-and-Comet.md
Normal file
@ -0,0 +1,269 @@
|
||||
# 使用 Gradio 和 Comet
|
||||
|
||||
Tags: COMET, SPACES
|
||||
由 Comet 团队贡献
|
||||
|
||||
## 介绍
|
||||
|
||||
在这个指南中,我们将展示您可以如何使用 Gradio 和 Comet。我们将介绍使用 Comet 和 Gradio 的基本知识,并向您展示如何利用 Gradio 的高级功能,如 [使用 iFrames 进行嵌入](https://www.gradio.app/sharing-your-app/#embedding-with-iframes) 和 [状态](https://www.gradio.app/docs/#state) 来构建一些令人惊叹的模型评估工作流程。
|
||||
|
||||
下面是本指南涵盖的主题列表。
|
||||
|
||||
1. 将 Gradio UI 记录到您的 Comet 实验中
|
||||
2. 直接将 Gradio 应用程序嵌入到您的 Comet 项目中
|
||||
3. 直接将 Hugging Face Spaces 嵌入到您的 Comet 项目中
|
||||
4. 将 Gradio 应用程序的模型推理记录到 Comet 中
|
||||
|
||||
## 什么是 Comet?
|
||||
|
||||
[Comet](https://www.comet.com?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) 是一个 MLOps 平台,旨在帮助数据科学家和团队更快地构建更好的模型!Comet 提供工具来跟踪、解释、管理和监控您的模型,集中在一个地方!它可以与 Jupyter 笔记本和脚本配合使用,最重要的是,它是 100% 免费的!
|
||||
|
||||
## 设置
|
||||
|
||||
首先,安装运行这些示例所需的依赖项
|
||||
|
||||
```shell
|
||||
pip install comet_ml torch torchvision transformers gradio shap requests Pillow
|
||||
```
|
||||
|
||||
接下来,您需要[注册一个 Comet 账户](https://www.comet.com/signup?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs)。一旦您设置了您的账户,[获取您的 API 密钥](https://www.comet.com/docs/v2/guides/getting-started/quickstart/#get-an-api-key?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) 并配置您的 Comet 凭据
|
||||
|
||||
如果您将这些示例作为脚本运行,您可以将您的凭据导出为环境变量
|
||||
|
||||
```shell
|
||||
export COMET_API_KEY="<您的 API 密钥>"
|
||||
export COMET_WORKSPACE="<您的工作空间名称>"
|
||||
export COMET_PROJECT_NAME="<您的项目名称>"
|
||||
```
|
||||
|
||||
或者将它们设置在您的工作目录中的 `.comet.config` 文件中。您的文件应按以下方式格式化。
|
||||
|
||||
```shell
|
||||
[comet]
|
||||
api_key=<您的 API 密钥>
|
||||
workspace=<您的工作空间名称>
|
||||
project_name=<您的项目名称>
|
||||
```
|
||||
|
||||
如果您使用提供的 Colab Notebooks 运行这些示例,请在开始 Gradio UI 之前运行带有以下片段的单元格。运行此单元格可以让您交互式地将 API 密钥添加到笔记本中。
|
||||
|
||||
```python
|
||||
import comet_ml
|
||||
comet_ml.init()
|
||||
```
|
||||
|
||||
## 1. 将 Gradio UI 记录到您的 Comet 实验中
|
||||
|
||||
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Gradio_and_Comet.ipynb)
|
||||
|
||||
在这个例子中,我们将介绍如何将您的 Gradio 应用程序记录到 Comet,并使用 Gradio 自定义面板与其进行交互。
|
||||
|
||||
我们先通过使用 `resnet18` 构建一个简单的图像分类示例。
|
||||
|
||||
```python
|
||||
import comet_ml
|
||||
|
||||
import requests
|
||||
import torch
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
torch.hub.download_url_to_file("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
|
||||
|
||||
if torch.cuda.is_available():
|
||||
device = "cuda"
|
||||
else:
|
||||
device = "cpu"
|
||||
|
||||
model = torch.hub.load("pytorch/vision:v0.6.0", "resnet18", pretrained=True).eval()
|
||||
model = model.to(device)
|
||||
|
||||
# 为 ImageNet 下载可读的标签。
|
||||
response = requests.get("https://git.io/JJkYN")
|
||||
labels = response.text.split("\n")
|
||||
|
||||
|
||||
def predict(inp):
|
||||
inp = Image.fromarray(inp.astype("uint8"), "RGB")
|
||||
inp = transforms.ToTensor()(inp).unsqueeze(0)
|
||||
with torch.no_grad():
|
||||
prediction = torch.nn.functional.softmax(model(inp.to(device))[0], dim=0)
|
||||
return {labels[i]: float(prediction[i]) for i in range(1000)}
|
||||
|
||||
|
||||
inputs = gr.Image()
|
||||
outputs = gr.Label(num_top_classes=3)
|
||||
|
||||
io = gr.Interface(
|
||||
fn=predict, inputs=inputs, outputs=outputs, examples=["dog.jpg"]
|
||||
)
|
||||
io.launch(inline=False, share=True)
|
||||
|
||||
experiment = comet_ml.Experiment()
|
||||
experiment.add_tag("image-classifier")
|
||||
|
||||
io.integrate(comet_ml=experiment)
|
||||
```
|
||||
|
||||
此片段中的最后一行将将 Gradio 应用程序的 URL 记录到您的 Comet 实验中。您可以在实验的文本选项卡中找到该 URL。
|
||||
|
||||
<video width="560" height="315" controls>
|
||||
<source src="https://user-images.githubusercontent.com/7529846/214328034-09369d4d-8b94-4c4a-aa3c-25e3ed8394c4.mp4"></source>
|
||||
</video>
|
||||
|
||||
将 Gradio 面板添加到您的实验中,与应用程序进行交互。
|
||||
|
||||
<video width="560" height="315" controls>
|
||||
<source src="https://user-images.githubusercontent.com/7529846/214328194-95987f83-c180-4929-9bed-c8a0d3563ed7.mp4"></source>
|
||||
</video>
|
||||
|
||||
## 2. 直接将 Gradio 应用程序嵌入到您的 Comet 项目中
|
||||
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=9" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
|
||||
|
||||
如果您要长期托管 Gradio 应用程序,可以使用 Gradio Panel Extended 自定义面板进行嵌入 UI。
|
||||
|
||||
转到您的 Comet 项目页面,转到面板选项卡。单击“+ 添加”按钮以打开面板搜索页面。
|
||||
|
||||
<img width="560" alt="adding-panels" src="https://user-images.githubusercontent.com/7529846/214329314-70a3ff3d-27fb-408c-a4d1-4b58892a3854.jpeg">
|
||||
|
||||
接下来,在公共面板部分搜索 Gradio Panel Extended 并单击“添加”。
|
||||
|
||||
<img width="560" alt="gradio-panel-extended" src="https://user-images.githubusercontent.com/7529846/214325577-43226119-0292-46be-a62a-0c7a80646ebb.png">
|
||||
|
||||
添加面板后,单击“编辑”以访问面板选项页面,并粘贴您的 Gradio 应用程序的 URL。
|
||||
|
||||
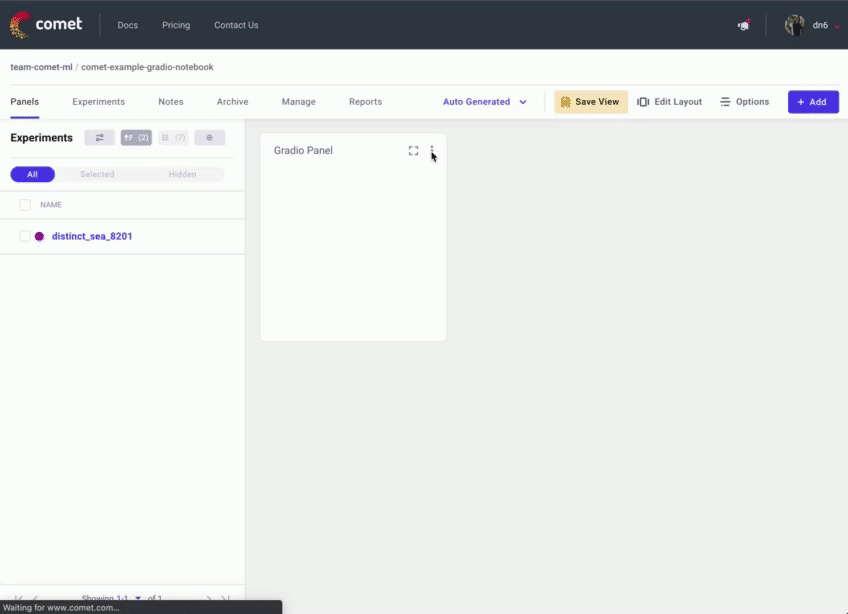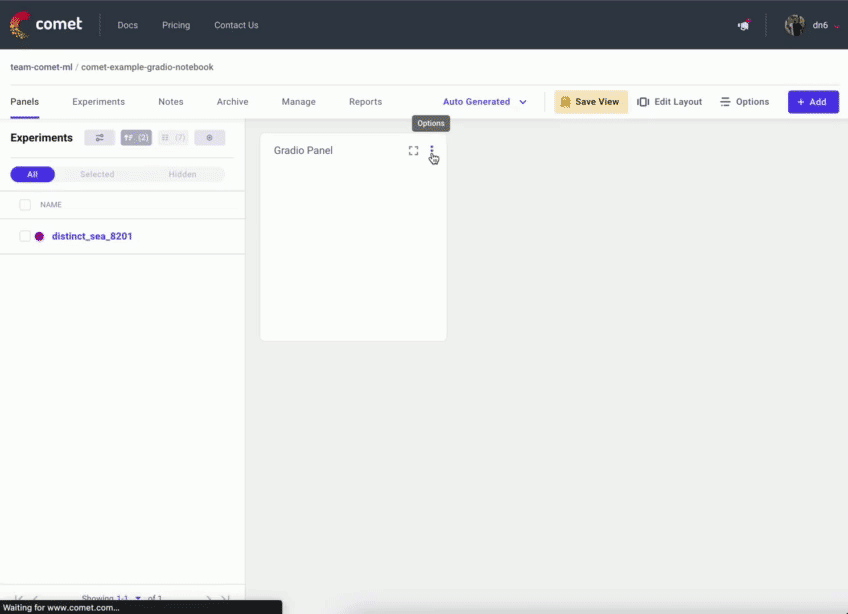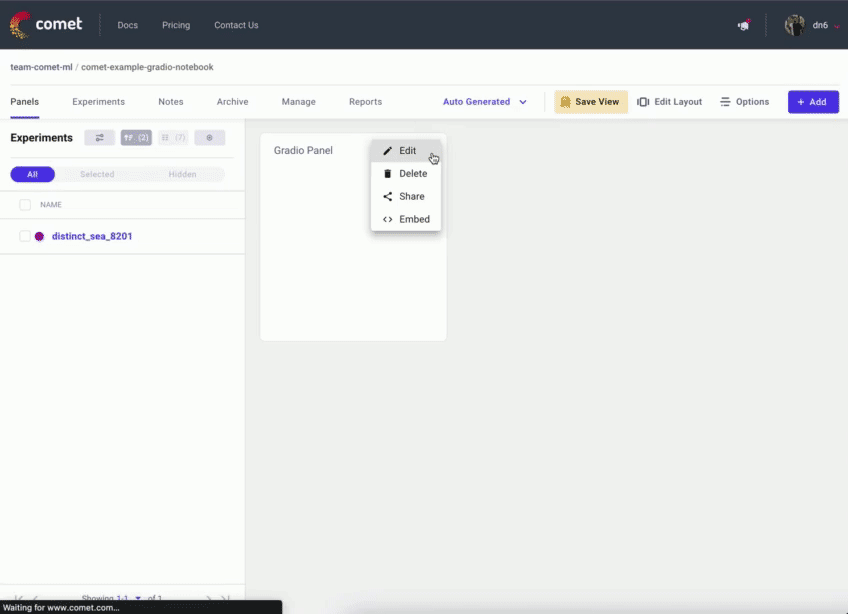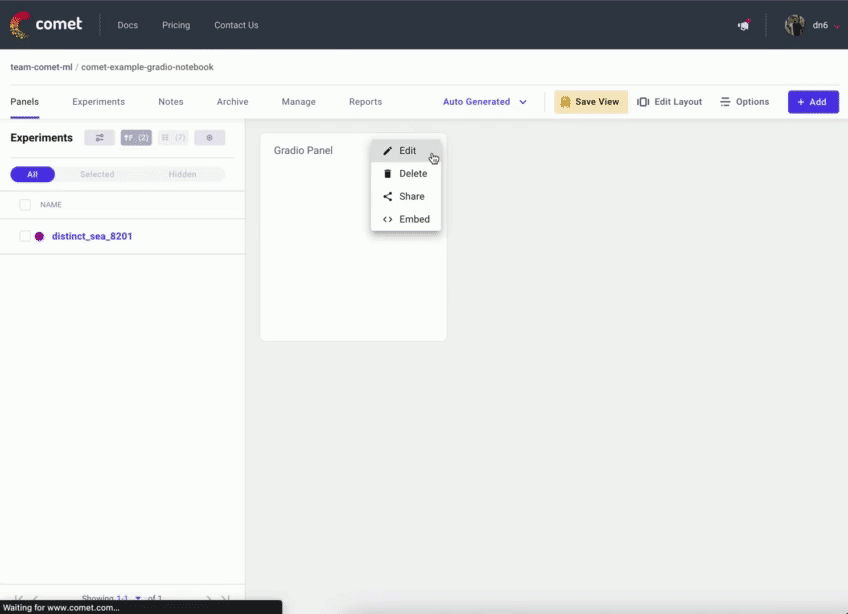
|
||||
|
||||
<img width="560" alt="Edit-Gradio-Panel-URL" src="https://user-images.githubusercontent.com/7529846/214334843-870fe726-0aa1-4b21-bbc6-0c48f56c48d8.png">
|
||||
|
||||
## 3. 直接将 Hugging Face Spaces 嵌入到您的 Comet 项目中
|
||||
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=107" title="YouTube 视频播放器 " frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
|
||||
|
||||
您还可以使用 Hugging Face Spaces 面板将托管在 Hugging Faces Spaces 中的 Gradio 应用程序嵌入到您的 Comet 项目中。
|
||||
|
||||
转到 Comet 项目页面,转到面板选项卡。单击“+添加”按钮以打开面板搜索页面。然后,在公共面板部分搜索 Hugging Face Spaces 面板并单击“添加”。
|
||||
|
||||
<img width="560" height="315" alt="huggingface-spaces-panel" src="https://user-images.githubusercontent.com/7529846/214325606-99aa3af3-b284-4026-b423-d3d238797e12.png">
|
||||
|
||||
添加面板后,单击“编辑”以访问面板选项页面,并粘贴您的 Hugging Face Space 路径,例如 `pytorch/ResNet`
|
||||
|
||||
<img width="560" height="315" alt="Edit-HF-Space" src="https://user-images.githubusercontent.com/7529846/214335868-c6f25dee-13db-4388-bcf5-65194f850b02.png">
|
||||
|
||||
## 4. 记录模型推断结果到 Comet
|
||||
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=176" title="YouTube 视频播放器 " frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
|
||||
|
||||
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Logging_Model_Inferences_with_Comet_and_Gradio.ipynb)
|
||||
|
||||
在前面的示例中,我们演示了通过 Comet UI 与 Gradio 应用程序交互的各种方法。此外,您还可以将 Gradio 应用程序的模型推断(例如 SHAP 图)记录到 Comet 中。
|
||||
|
||||
在以下代码段中,我们将记录来自文本生成模型的推断。我们可以使用 Gradio 的[State](https://www.gradio.app/docs/#state)对象在多次推断调用之间保持实验的持久性。这将使您能够将多个模型推断记录到单个实验中。
|
||||
|
||||
```python
|
||||
import comet_ml
|
||||
import gradio as gr
|
||||
import shap
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
if torch.cuda.is_available():
|
||||
device = "cuda"
|
||||
else:
|
||||
device = "cpu"
|
||||
|
||||
MODEL_NAME = "gpt2"
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
|
||||
|
||||
# set model decoder to true
|
||||
model.config.is_decoder = True
|
||||
# set text-generation params under task_specific_params
|
||||
model.config.task_specific_params["text-generation"] = {
|
||||
"do_sample": True,
|
||||
"max_length": 50,
|
||||
"temperature": 0.7,
|
||||
"top_k": 50,
|
||||
"no_repeat_ngram_size": 2,
|
||||
}
|
||||
model = model.to(device)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
||||
explainer = shap.Explainer(model, tokenizer)
|
||||
|
||||
|
||||
def start_experiment():
|
||||
"""Returns an APIExperiment object that is thread safe
|
||||
and can be used to log inferences to a single Experiment
|
||||
"""
|
||||
try:
|
||||
api = comet_ml.API()
|
||||
workspace = api.get_default_workspace()
|
||||
project_name = comet_ml.config.get_config()["comet.project_name"]
|
||||
|
||||
experiment = comet_ml.APIExperiment(
|
||||
workspace=workspace, project_name=project_name
|
||||
)
|
||||
experiment.log_other("Created from", "gradio-inference")
|
||||
|
||||
message = f"Started Experiment: [{experiment.name}]({experiment.url})"
|
||||
return (experiment, message)
|
||||
|
||||
except Exception as e:
|
||||
return None, None
|
||||
|
||||
|
||||
def predict(text, state, message):
|
||||
experiment = state
|
||||
|
||||
shap_values = explainer([text])
|
||||
plot = shap.plots.text(shap_values, display=False)
|
||||
|
||||
if experiment is not None:
|
||||
experiment.log_other("message", message)
|
||||
experiment.log_html(plot)
|
||||
|
||||
return plot
|
||||
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
start_experiment_btn = gr.Button("Start New Experiment")
|
||||
experiment_status = gr.Markdown()
|
||||
|
||||
# Log a message to the Experiment to provide more context
|
||||
experiment_message = gr.Textbox(label="Experiment Message")
|
||||
experiment = gr.State()
|
||||
|
||||
input_text = gr.Textbox(label="Input Text", lines=5, interactive=True)
|
||||
submit_btn = gr.Button("Submit")
|
||||
|
||||
output = gr.HTML(interactive=True)
|
||||
|
||||
start_experiment_btn.click(
|
||||
start_experiment, outputs=[experiment, experiment_status]
|
||||
)
|
||||
submit_btn.click(
|
||||
predict, inputs=[input_text, experiment, experiment_message], outputs=[output]
|
||||
)
|
||||
```
|
||||
|
||||
该代码段中的推断结果将保存在实验的 HTML 选项卡中。
|
||||
|
||||
<video width="560" height="315" controls>
|
||||
<source src="https://user-images.githubusercontent.com/7529846/214328610-466e5c81-4814-49b9-887c-065aca14dd30.mp4"></source>
|
||||
</video>
|
||||
|
||||
## 结论
|
||||
|
||||
希望您对本指南有所裨益,并能为您构建出色的 Comet 和 Gradio 模型评估工作流程提供一些启示。
|
||||
|
||||
## 如何在 Comet 组织上贡献 Gradio 演示
|
||||
|
||||
* 在 Hugging Face 上创建帐号[此处](https://huggingface.co/join)。
|
||||
* 在用户名下添加 Gradio 演示,请参阅[此处](https://huggingface.co/course/chapter9/4?fw=pt)以设置 Gradio 演示。
|
||||
* 请求加入 Comet 组织[此处](https://huggingface.co/Comet)。
|
||||
|
||||
## 更多资源
|
||||
|
||||
* [Comet 文档](https://www.comet.com/docs/v2/?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs)
|
||||
@ -0,0 +1,139 @@
|
||||
# Gradio 和 ONNX 在 Hugging Face 上
|
||||
|
||||
Related spaces: https://huggingface.co/spaces/onnx/EfficientNet-Lite4
|
||||
Tags: ONNX,SPACES
|
||||
由 Gradio 和 <a href="https://onnx.ai/">ONNX</a> 团队贡献
|
||||
|
||||
## 介绍
|
||||
|
||||
在这个指南中,我们将为您介绍以下内容:
|
||||
|
||||
* ONNX、ONNX 模型仓库、Gradio 和 Hugging Face Spaces 的介绍
|
||||
* 如何为 EfficientNet-Lite4 设置 Gradio 演示
|
||||
* 如何为 Hugging Face 上的 ONNX 组织贡献自己的 Gradio 演示
|
||||
|
||||
下面是一个 ONNX 模型的示例:在下面尝试 EfficientNet-Lite4 演示。
|
||||
|
||||
<iframe src="https://onnx-efficientnet-lite4.hf.space" frameBorder="0" height="810" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
## ONNX 模型仓库是什么?
|
||||
Open Neural Network Exchange([ONNX](https://onnx.ai/))是一种表示机器学习模型的开放标准格式。ONNX 由一个实现了该格式的合作伙伴社区支持,该社区将其实施到许多框架和工具中。例如,如果您在 TensorFlow 或 PyTorch 中训练了一个模型,您可以轻松地将其转换为 ONNX,然后使用类似 ONNX Runtime 的引擎 / 编译器在各种设备上运行它。
|
||||
|
||||
[ONNX 模型仓库](https://github.com/onnx/models)是由社区成员贡献的一组预训练的先进模型,格式为 ONNX。每个模型都附带了用于模型训练和运行推理的 Jupyter 笔记本。这些笔记本以 Python 编写,并包含到训练数据集的链接,以及描述模型架构的原始论文的参考文献。
|
||||
|
||||
## Hugging Face Spaces 和 Gradio 是什么?
|
||||
|
||||
### Gradio
|
||||
|
||||
Gradio 可让用户使用 Python 代码将其机器学习模型演示为 Web 应用程序。Gradio 将 Python 函数封装到用户界面中,演示可以在 jupyter 笔记本、colab 笔记本中启动,并可以嵌入到您自己的网站上,并在 Hugging Face Spaces 上免费托管。
|
||||
|
||||
在此处开始[https://gradio.app/getting_started](https://gradio.app/getting_started)
|
||||
|
||||
### Hugging Face Spaces
|
||||
|
||||
Hugging Face Spaces 是 Gradio 演示的免费托管选项。Spaces 提供了 3 种 SDK 选项:Gradio、Streamlit 和静态 HTML 演示。Spaces 可以是公共的或私有的,工作流程与 github repos 类似。目前 Hugging Face 上有 2000 多个 Spaces。在此处了解更多关于 Spaces 的信息[https://huggingface.co/spaces/launch](https://huggingface.co/spaces/launch)。
|
||||
|
||||
### Hugging Face 模型
|
||||
|
||||
Hugging Face 模型中心还支持 ONNX 模型,并且可以通过[ONNX 标签](https://huggingface.co/models?library=onnx&sort=downloads)对 ONNX 模型进行筛选
|
||||
|
||||
## Hugging Face 是如何帮助 ONNX 模型仓库的?
|
||||
ONNX 模型仓库中有许多 Jupyter 笔记本供用户测试模型。以前,用户需要自己下载模型并在本地运行这些笔记本测试。有了 Hugging Face,测试过程可以更简单和用户友好。用户可以在 Hugging Face Spaces 上轻松尝试 ONNX 模型仓库中的某个模型,并使用 ONNX Runtime 运行由 Gradio 提供支持的快速演示,全部在云端进行,无需在本地下载任何内容。请注意,ONNX 有各种运行时,例如[ONNX Runtime](https://github.com/microsoft/onnxruntime)、[MXNet](https://github.com/apache/incubator-mxnet)等
|
||||
|
||||
## ONNX Runtime 的作用是什么?
|
||||
ONNX Runtime 是一个跨平台的推理和训练机器学习加速器。它使得在 Hugging Face 上使用 ONNX 模型仓库中的模型进行实时 Gradio 演示成为可能。
|
||||
|
||||
ONNX Runtime 可以实现更快的客户体验和更低的成本,支持来自 PyTorch 和 TensorFlow/Keras 等深度学习框架以及 scikit-learn、LightGBM、XGBoost 等传统机器学习库的模型。ONNX Runtime 与不同的硬件、驱动程序和操作系统兼容,并通过利用适用的硬件加速器以及图形优化和转换提供最佳性能。有关更多信息,请参阅[官方网站](https://onnxruntime.ai/)。
|
||||
|
||||
## 为 EfficientNet-Lite4 设置 Gradio 演示
|
||||
|
||||
EfficientNet-Lite 4 是 EfficientNet-Lite 系列中最大和最准确的模型。它是一个仅使用整数量化的模型,能够在所有 EfficientNet 模型中提供最高的准确率。在 Pixel 4 CPU 上以实时方式运行(例如 30ms/ 图像)时,可以实现 80.4%的 ImageNet top-1 准确率。要了解更多信息,请阅读[模型卡片](https://github.com/onnx/models/tree/main/vision/classification/efficientnet-lite4)
|
||||
|
||||
在这里,我们将演示如何使用 Gradio 为 EfficientNet-Lite4 设置示例演示
|
||||
|
||||
首先,我们导入所需的依赖项并下载和载入来自 ONNX 模型仓库的 efficientnet-lite4 模型。然后从 labels_map.txt 文件加载标签。接下来,我们设置预处理函数、加载用于推理的模型并设置推理函数。最后,将推理函数封装到 Gradio 接口中,供用户进行交互。下面是完整的代码。
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import math
|
||||
import matplotlib.pyplot as plt
|
||||
import cv2
|
||||
import json
|
||||
import gradio as gr
|
||||
from huggingface_hub import hf_hub_download
|
||||
from onnx import hub
|
||||
import onnxruntime as ort
|
||||
|
||||
# 从ONNX模型仓库加载ONNX模型
|
||||
model = hub.load("efficientnet-lite4")
|
||||
# 加载标签文本文件
|
||||
labels = json.load(open("labels_map.txt", "r"))
|
||||
|
||||
# 通过将图像从中心调整大小并裁剪到224x224来设置图像文件的尺寸
|
||||
def pre_process_edgetpu(img, dims):
|
||||
output_height, output_width, _ = dims
|
||||
img = resize_with_aspectratio(img, output_height, output_width, inter_pol=cv2.INTER_LINEAR)
|
||||
img = center_crop(img, output_height, output_width)
|
||||
img = np.asarray(img, dtype='float32')
|
||||
# 将jpg像素值从[0 - 255]转换为浮点数组[-1.0 - 1.0]
|
||||
img -= [127.0, 127.0, 127.0]
|
||||
img /= [128.0, 128.0, 128.0]
|
||||
return img
|
||||
|
||||
# 使用等比例缩放调整图像尺寸
|
||||
def resize_with_aspectratio(img, out_height, out_width, scale=87.5, inter_pol=cv2.INTER_LINEAR):
|
||||
height, width, _ = img.shape
|
||||
new_height = int(100. * out_height / scale)
|
||||
new_width = int(100. * out_width / scale)
|
||||
if height > width:
|
||||
w = new_width
|
||||
h = int(new_height * height / width)
|
||||
else:
|
||||
h = new_height
|
||||
w = int(new_width * width / height)
|
||||
img = cv2.resize(img, (w, h), interpolation=inter_pol)
|
||||
return img
|
||||
|
||||
# crops the image around the center based on given height and width
|
||||
def center_crop(img, out_height, out_width):
|
||||
height, width, _ = img.shape
|
||||
left = int((width - out_width) / 2)
|
||||
right = int((width + out_width) / 2)
|
||||
top = int((height - out_height) / 2)
|
||||
bottom = int((height + out_height) / 2)
|
||||
img = img[top:bottom, left:right]
|
||||
return img
|
||||
|
||||
|
||||
sess = ort.InferenceSession(model)
|
||||
|
||||
def inference(img):
|
||||
img = cv2.imread(img)
|
||||
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||
|
||||
img = pre_process_edgetpu(img, (224, 224, 3))
|
||||
|
||||
img_batch = np.expand_dims(img, axis=0)
|
||||
|
||||
results = sess.run(["Softmax:0"], {"images:0": img_batch})[0]
|
||||
result = reversed(results[0].argsort()[-5:])
|
||||
resultdic = {}
|
||||
for r in result:
|
||||
resultdic[labels[str(r)]] = float(results[0][r])
|
||||
return resultdic
|
||||
|
||||
title = "EfficientNet-Lite4"
|
||||
description = "EfficientNet-Lite 4是最大的变体,也是EfficientNet-Lite模型集合中最准确的。它是一个仅包含整数的量化模型,具有所有EfficientNet模型中最高的准确度。在Pixel 4 CPU上,它实现了80.4%的ImageNet top-1准确度,同时仍然可以实时运行(例如30ms/图像)。"
|
||||
examples = [['catonnx.jpg']]
|
||||
gr.Interface(inference, gr.Image(type="filepath"), "label", title=title, description=description, examples=examples).launch()
|
||||
```
|
||||
|
||||
## 如何使用 ONNX 模型在 HF Spaces 上贡献 Gradio 演示
|
||||
|
||||
* 将模型添加到[onnx model zoo](https://github.com/onnx/models/blob/main/.github/PULL_REQUEST_TEMPLATE.md)
|
||||
* 在 Hugging Face 上创建一个账号[here](https://huggingface.co/join).
|
||||
* 要查看还有哪些模型需要添加到 ONNX 组织中,请参阅[Models list](https://github.com/onnx/models#models)中的列表
|
||||
* 在您的用户名下添加 Gradio Demo,请参阅此[博文](https://huggingface.co/blog/gradio-spaces)以在 Hugging Face 上设置 Gradio Demo。
|
||||
* 请求加入 ONNX 组织[here](https://huggingface.co/onnx).
|
||||
* 一旦获准,将模型从您的用户名下转移到 ONNX 组织
|
||||
* 在模型表中为模型添加徽章,在[Models list](https://github.com/onnx/models#models)中查看示例
|
||||
@ -0,0 +1,285 @@
|
||||
# Gradio and W&B Integration
|
||||
|
||||
相关空间:https://huggingface.co/spaces/akhaliq/JoJoGAN
|
||||
标签:WANDB, SPACES
|
||||
由 Gradio 团队贡献
|
||||
|
||||
## 介绍
|
||||
|
||||
在本指南中,我们将引导您完成以下内容:
|
||||
|
||||
* Gradio、Hugging Face Spaces 和 Wandb 的介绍
|
||||
* 如何使用 Wandb 集成为 JoJoGAN 设置 Gradio 演示
|
||||
* 如何在 Hugging Face 的 Wandb 组织中追踪实验并贡献您自己的 Gradio 演示
|
||||
|
||||
下面是一个使用 Wandb 跟踪训练和实验的模型示例,请在下方尝试 JoJoGAN 演示。
|
||||
|
||||
<iframe src="https://akhaliq-jojogan.hf.space" frameBorder="0" height="810" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
## 什么是 Wandb?
|
||||
|
||||
Weights and Biases (W&B) 允许数据科学家和机器学习科学家在从训练到生产的每个阶段跟踪他们的机器学习实验。任何指标都可以对样本进行聚合,并在可自定义和可搜索的仪表板中显示,如下所示:
|
||||
|
||||
<img alt="Screen Shot 2022-08-01 at 5 54 59 PM" src="https://user-images.githubusercontent.com/81195143/182252755-4a0e1ca8-fd25-40ff-8c91-c9da38aaa9ec.png">
|
||||
|
||||
## 什么是 Hugging Face Spaces 和 Gradio?
|
||||
|
||||
### Gradio
|
||||
|
||||
Gradio 让用户可以使用几行 Python 代码将其机器学习模型演示为 Web 应用程序。Gradio 将任何 Python 函数(例如机器学习模型的推断函数)包装成一个用户界面,这些演示可以在 jupyter 笔记本、colab 笔记本中启动,也可以嵌入到您自己的网站中,免费托管在 Hugging Face Spaces 上。
|
||||
|
||||
在这里开始 [here](https://gradio.app/getting_started)
|
||||
|
||||
### Hugging Face Spaces
|
||||
|
||||
Hugging Face Spaces 是 Gradio 演示的免费托管选项。Spaces 有 3 个 SDK 选项:Gradio、Streamlit 和静态 HTML 演示。Spaces 可以是公共的或私有的,工作流程类似于 github 存储库。目前在 Hugging Face 上有 2000 多个 Spaces。了解更多关于 Spaces 的信息 [here](https://huggingface.co/spaces/launch)。
|
||||
|
||||
## 为 JoJoGAN 设置 Gradio 演示
|
||||
|
||||
现在,让我们引导您如何在自己的环境中完成此操作。我们假设您对 W&B 和 Gradio 还不太了解,只是为了本教程的目的。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
1. 创建 W&B 账号
|
||||
|
||||
如果您还没有 W&B 账号,请按照[这些快速说明](https://app.wandb.ai/login)创建免费账号。这不应该超过几分钟的时间。一旦完成(或者如果您已经有一个账户),接下来,我们将运行一个快速的 colab。
|
||||
|
||||
2. 打开 Colab 安装 Gradio 和 W&B
|
||||
|
||||
我们将按照 JoJoGAN 存储库中提供的 colab 进行操作,稍作修改以更有效地使用 Wandb 和 Gradio。
|
||||
|
||||
[](https://colab.research.google.com/github/mchong6/JoJoGAN/blob/main/stylize.ipynb)
|
||||
|
||||
在顶部安装 Gradio 和 Wandb:
|
||||
|
||||
```sh
|
||||
|
||||
pip install gradio wandb
|
||||
```
|
||||
|
||||
3. 微调 StyleGAN 和 W&B 实验跟踪
|
||||
|
||||
下一步将打开一个 W&B 仪表板,以跟踪实验,并显示一个 Gradio 演示提供的预训练模型,您可以从下拉菜单中选择。这是您需要的代码:
|
||||
|
||||
```python
|
||||
|
||||
alpha = 1.0
|
||||
alpha = 1-alpha
|
||||
|
||||
preserve_color = True
|
||||
num_iter = 100
|
||||
log_interval = 50
|
||||
|
||||
samples = []
|
||||
column_names = ["Reference (y)", "Style Code(w)", "Real Face Image(x)"]
|
||||
|
||||
wandb.init(project="JoJoGAN")
|
||||
config = wandb.config
|
||||
config.num_iter = num_iter
|
||||
config.preserve_color = preserve_color
|
||||
wandb.log(
|
||||
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
|
||||
step=0)
|
||||
|
||||
# 加载判别器用于感知损失
|
||||
discriminator = Discriminator(1024, 2).eval().to(device)
|
||||
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
|
||||
discriminator.load_state_dict(ckpt["d"], strict=False)
|
||||
|
||||
# 重置生成器
|
||||
del generator
|
||||
generator = deepcopy(original_generator)
|
||||
|
||||
g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
|
||||
|
||||
# 用于生成一族合理真实图像-> 假图像的更换图层
|
||||
if preserve_color:
|
||||
id_swap = [9,11,15,16,17]
|
||||
else:
|
||||
id_swap = list(range(7, generator.n_latent))
|
||||
|
||||
for idx in tqdm(range(num_iter)):
|
||||
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
|
||||
in_latent = latents.clone()
|
||||
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
|
||||
|
||||
img = generator(in_latent, input_is_latent=True)
|
||||
|
||||
with torch.no_grad():
|
||||
real_feat = discriminator(targets)
|
||||
fake_feat = discriminator(img)
|
||||
|
||||
loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
|
||||
|
||||
wandb.log({"loss": loss}, step=idx)
|
||||
if idx % log_interval == 0:
|
||||
generator.eval()
|
||||
my_sample = generator(my_w, input_is_latent=True)
|
||||
generator.train()
|
||||
my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1)))
|
||||
wandb.log(
|
||||
{"Current stylization": [wandb.Image(my_sample)]},
|
||||
step=idx)
|
||||
table_data = [
|
||||
wandb.Image(transforms.ToPILImage()(target_im)),
|
||||
wandb.Image(img),
|
||||
wandb.Image(my_sample),
|
||||
]
|
||||
samples.append(table_data)
|
||||
|
||||
g_optim.zero_grad()
|
||||
loss.backward()
|
||||
g_optim.step()
|
||||
|
||||
out_table = wandb.Table(data=samples, columns=column_names)
|
||||
wandb.log({" 当前样本数 ": out_table})
|
||||
```
|
||||
|
||||
4. 保存、下载和加载模型
|
||||
|
||||
以下是如何保存和下载您的模型。
|
||||
|
||||
```python
|
||||
|
||||
from PIL import Image
|
||||
import torch
|
||||
torch.backends.cudnn.benchmark = True
|
||||
from torchvision import transforms, utils
|
||||
from util import *
|
||||
import math
|
||||
import random
|
||||
import numpy as np
|
||||
from torch import nn, autograd, optim
|
||||
from torch.nn import functional as F
|
||||
from tqdm import tqdm
|
||||
import lpips
|
||||
from model import *
|
||||
from e4e_projection import projection as e4e_projection
|
||||
|
||||
from copy import deepcopy
|
||||
import imageio
|
||||
|
||||
import os
|
||||
import sys
|
||||
import torchvision.transforms as transforms
|
||||
from argparse import Namespace
|
||||
from e4e.models.psp import pSp
|
||||
from util import *
|
||||
from huggingface_hub import hf_hub_download
|
||||
from google.colab import files
|
||||
torch.save({"g": generator.state_dict()}, "your-model-name.pt")
|
||||
|
||||
files.download('your-model-name.pt')
|
||||
|
||||
latent_dim = 512
|
||||
device="cuda"
|
||||
model_path_s = hf_hub_download(repo_id="akhaliq/jojogan-stylegan2-ffhq-config-f", filename="stylegan2-ffhq-config-f.pt")
|
||||
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
|
||||
ckpt = torch.load(model_path_s, map_location=lambda storage, loc: storage)
|
||||
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
|
||||
mean_latent = original_generator.mean_latent(10000)
|
||||
|
||||
generator = deepcopy(original_generator)
|
||||
|
||||
ckpt = torch.load("/content/JoJoGAN/your-model-name.pt", map_location=lambda storage, loc: storage)
|
||||
generator.load_state_dict(ckpt["g"], strict=False)
|
||||
generator.eval()
|
||||
|
||||
plt.rcParams['figure.dpi'] = 150
|
||||
|
||||
transform = transforms.Compose(
|
||||
[
|
||||
transforms.Resize((1024, 1024)),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
|
||||
]
|
||||
)
|
||||
|
||||
def inference(img):
|
||||
img.save('out.jpg')
|
||||
aligned_face = align_face('out.jpg')
|
||||
|
||||
my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0)
|
||||
with torch.no_grad():
|
||||
my_sample = generator(my_w, input_is_latent=True)
|
||||
|
||||
npimage = my_sample[0].cpu().permute(1, 2, 0).detach().numpy()
|
||||
imageio.imwrite('filename.jpeg', npimage)
|
||||
return 'filename.jpeg'
|
||||
```
|
||||
|
||||
5. 构建 Gradio 演示
|
||||
|
||||
```python
|
||||
|
||||
import gradio as gr
|
||||
|
||||
title = "JoJoGAN"
|
||||
description = "JoJoGAN 的 Gradio 演示:一次性面部风格化。要使用它,只需上传您的图像,或单击示例之一加载它们。在下面的链接中阅读更多信息。"
|
||||
|
||||
demo = gr.Interface(
|
||||
inference,
|
||||
gr.Image(type="pil"),
|
||||
gr.Image(type=" 文件 "),
|
||||
title=title,
|
||||
description=description
|
||||
)
|
||||
|
||||
demo.launch(share=True)
|
||||
```
|
||||
|
||||
6. 将 Gradio 集成到 W&B 仪表板
|
||||
|
||||
最后一步——将 Gradio 演示与 W&B 仪表板集成,只需要一行额外的代码 :
|
||||
|
||||
```python
|
||||
|
||||
demo.integrate(wandb=wandb)
|
||||
```
|
||||
|
||||
调用集成之后,将创建一个演示,您可以将其集成到仪表板或报告中
|
||||
|
||||
在 W&B 之外,使用 gradio-app 标记允许任何人直接将 Gradio 演示嵌入到其博客、网站、文档等中的 HF spaces 上 :
|
||||
|
||||
```html
|
||||
|
||||
<gradio-app space="akhaliq/JoJoGAN"> <gradio-app>
|
||||
```
|
||||
|
||||
7.(可选)在 Gradio 应用程序中嵌入 W&B 图
|
||||
|
||||
也可以在 Gradio 应用程序中嵌入 W&B 图。为此,您可以创建一个 W&B 报告,并在一个 `gr.HTML` 块中将其嵌入到 Gradio 应用程序中。
|
||||
|
||||
报告需要是公开的,您需要在 iFrame 中包装 URL,如下所示 :
|
||||
The Report will need to be public and you will need to wrap the URL within an iFrame like this:
|
||||
```python
|
||||
|
||||
import gradio as gr
|
||||
|
||||
def wandb_report(url):
|
||||
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
|
||||
return gr.HTML(iframe)
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
report_url = 'https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx'
|
||||
report = wandb_report(report_url)
|
||||
|
||||
demo.launch(share=True)
|
||||
```
|
||||
|
||||
## 结论
|
||||
|
||||
希望您喜欢此嵌入 Gradio 演示到 W&B 报告的简短演示!感谢您一直阅读到最后。回顾一下 :
|
||||
|
||||
* 仅需要一个单一参考图像即可对 JoJoGAN 进行微调,通常在 GPU 上需要约 1 分钟。训练完成后,可以将样式应用于任何输入图像。在论文中阅读更多内容。
|
||||
|
||||
* W&B 可以通过添加几行代码来跟踪实验,您可以在单个集中的仪表板中可视化、排序和理解您的实验。
|
||||
|
||||
* Gradio 则在用户友好的界面中演示模型,可以在网络上任何地方共享。
|
||||
|
||||
## 如何在 Wandb 组织的 HF spaces 上 贡献 Gradio 演示
|
||||
|
||||
* 在 Hugging Face 上创建一个帐户[此处](https://huggingface.co/join)。
|
||||
* 在您的用户名下添加 Gradio 演示,请参阅[此教程](https://huggingface.co/course/chapter9/4?fw=pt) 以在 Hugging Face 上设置 Gradio 演示。
|
||||
* 申请加入 wandb 组织[此处](https://huggingface.co/wandb)。
|
||||
* 批准后,将模型从自己的用户名转移到 Wandb 组织中。
|
||||
@ -0,0 +1,88 @@
|
||||
# PyTorch 图像分类
|
||||
|
||||
Related spaces: https://huggingface.co/spaces/abidlabs/pytorch-image-classifier, https://huggingface.co/spaces/pytorch/ResNet, https://huggingface.co/spaces/pytorch/ResNext, https://huggingface.co/spaces/pytorch/SqueezeNet
|
||||
Tags: VISION, RESNET, PYTORCH
|
||||
|
||||
## 介绍
|
||||
|
||||
图像分类是计算机视觉中的一个核心任务。构建更好的分类器以区分图片中存在的物体是当前研究的一个热点领域,因为它的应用范围从自动驾驶车辆到医学成像等领域都很广泛。
|
||||
|
||||
这样的模型非常适合 Gradio 的 *image* 输入组件,因此在本教程中,我们将使用 Gradio 构建一个用于图像分类的 Web 演示。我们将能够在 Python 中构建整个 Web 应用程序,效果如下(试试其中一个示例!):
|
||||
|
||||
<iframe src="https://abidlabs-pytorch-image-classifier.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 包。我们将使用一个预训练的图像分类模型,所以您还应该安装了 `torch`。
|
||||
|
||||
## 第一步 - 设置图像分类模型
|
||||
|
||||
首先,我们需要一个图像分类模型。在本教程中,我们将使用一个预训练的 Resnet-18 模型,因为它可以从[PyTorch Hub](https://pytorch.org/hub/pytorch_vision_resnet/)轻松下载。您可以使用其他预训练模型或训练自己的模型。
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True).eval()
|
||||
```
|
||||
|
||||
由于我们将使用模型进行推断,所以我们调用了 `.eval()` 方法。
|
||||
|
||||
## 第二步 - 定义 `predict` 函数
|
||||
|
||||
接下来,我们需要定义一个函数,该函数接受*用户输入*,在本示例中是一张图片,并返回预测结果。预测结果应该以字典的形式返回,其中键是类别名称,值是置信度概率。我们将从这个[text 文件](https://git.io/JJkYN)中加载类别名称。
|
||||
|
||||
对于我们的预训练模型,它的代码如下:
|
||||
|
||||
```python
|
||||
import requests
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
|
||||
# 下载ImageNet的可读标签。
|
||||
response = requests.get("https://git.io/JJkYN")
|
||||
labels = response.text.split("\n")
|
||||
|
||||
def predict(inp):
|
||||
inp = transforms.ToTensor()(inp).unsqueeze(0)
|
||||
with torch.no_grad():
|
||||
prediction = torch.nn.functional.softmax(model(inp)[0], dim=0)
|
||||
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
|
||||
return confidences
|
||||
```
|
||||
|
||||
让我们逐步来看一下这段代码。该函数接受一个参数:
|
||||
|
||||
* `inp`:输入图片,类型为 `PIL` 图像
|
||||
|
||||
然后,该函数将图像转换为 PIL 图像,最终转换为 PyTorch 的 `tensor`,将其输入模型,并返回:
|
||||
|
||||
* `confidences`:预测结果,以字典形式表示,其中键是类别标签,值是置信度概率
|
||||
|
||||
## 第三步 - 创建 Gradio 界面
|
||||
|
||||
现在我们已经设置好了预测函数,我们可以创建一个 Gradio 界面。
|
||||
|
||||
在本例中,输入组件是一个拖放图片的组件。为了创建这个输入组件,我们使用 `Image(type="pil")` 来创建该组件,并处理预处理操作将其转换为 `PIL` 图像。
|
||||
|
||||
输出组件将是一个 `Label`,它以良好的形式显示顶部标签。由于我们不想显示所有 1000 个类别标签,所以我们将其定制为只显示前 3 个标签,构造为 `Label(num_top_classes=3)`。
|
||||
|
||||
最后,我们添加了一个 `examples` 参数,允许我们预填一些预定义的示例到界面中。Gradio 的代码如下:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.Interface(fn=predict,
|
||||
inputs=gr.Image(type="pil"),
|
||||
outputs=gr.Label(num_top_classes=3),
|
||||
examples=["lion.jpg", "cheetah.jpg"]).launch()
|
||||
```
|
||||
|
||||
这将产生以下界面,您可以在浏览器中直接尝试(试试上传自己的示例图片!):
|
||||
|
||||
<iframe src="https://abidlabs-pytorch-image-classifier.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
----------
|
||||
|
||||
完成了!这就是构建图像分类器 Web 演示所需的所有代码。如果您想与他人共享,请在 `launch()` 接口时设置 `share=True`!
|
||||
@ -0,0 +1,86 @@
|
||||
# TensorFlow 和 Keras 中的图像分类
|
||||
|
||||
相关空间:https://huggingface.co/spaces/abidlabs/keras-image-classifier
|
||||
标签:VISION, MOBILENET, TENSORFLOW
|
||||
|
||||
## 简介
|
||||
|
||||
图像分类是计算机视觉中的一项核心任务。构建更好的分类器来识别图像中的物体是一个研究的热点领域,因为它在交通控制系统到卫星成像等应用中都有广泛的应用。
|
||||
|
||||
这样的模型非常适合与 Gradio 的 *image* 输入组件一起使用,因此在本教程中,我们将使用 Gradio 构建一个用于图像分类的 Web 演示。我们可以在 Python 中构建整个 Web 应用程序,它的界面将如下所示(试试其中一个例子!):
|
||||
|
||||
<iframe src="https://abidlabs-keras-image-classifier.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 包。我们将使用一个预训练的 Keras 图像分类模型,因此您还应该安装了 `tensorflow`。
|
||||
|
||||
## 第一步 —— 设置图像分类模型
|
||||
|
||||
首先,我们需要一个图像分类模型。在本教程中,我们将使用一个预训练的 Mobile Net 模型,因为它可以从[Keras](https://keras.io/api/applications/mobilenet/)轻松下载。您也可以使用其他预训练模型或训练自己的模型。
|
||||
|
||||
```python
|
||||
import tensorflow as tf
|
||||
|
||||
inception_net = tf.keras.applications.MobileNetV2()
|
||||
```
|
||||
|
||||
此行代码将使用 Keras 库自动下载 MobileNet 模型和权重。
|
||||
|
||||
## 第二步 —— 定义 `predict` 函数
|
||||
|
||||
接下来,我们需要定义一个函数,该函数接收*用户输入*作为参数(在本例中为图像),并返回预测结果。预测结果应以字典形式返回,其中键是类名,值是置信概率。我们将从这个[text 文件](https://git.io/JJkYN)中加载类名。
|
||||
|
||||
对于我们的预训练模型,函数将如下所示:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
# 从ImageNet下载可读性标签。
|
||||
response = requests.get("https://git.io/JJkYN")
|
||||
labels = response.text.split("\n")
|
||||
|
||||
def classify_image(inp):
|
||||
inp = inp.reshape((-1, 224, 224, 3))
|
||||
inp = tf.keras.applications.mobilenet_v2.preprocess_input(inp)
|
||||
prediction = inception_net.predict(inp).flatten()
|
||||
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
|
||||
return confidences
|
||||
```
|
||||
|
||||
让我们来详细了解一下。该函数接受一个参数:
|
||||
|
||||
* `inp`:输入图像的 `numpy` 数组
|
||||
|
||||
然后,函数添加一个批次维度,通过模型进行处理,并返回:
|
||||
|
||||
* `confidences`:预测结果,以字典形式表示,其中键是类标签,值是置信概率
|
||||
|
||||
## 第三步 —— 创建 Gradio 界面
|
||||
|
||||
现在我们已经设置好了预测函数,我们可以围绕它创建一个 Gradio 界面。
|
||||
|
||||
在这种情况下,输入组件是一个拖放图像组件。要创建此输入组件,我们可以使用 `"gradio.inputs.Image"` 类,该类创建该组件并处理预处理以将其转换为 numpy 数组。我们将使用一个参数来实例化该类,该参数会自动将输入图像预处理为 224 像素 x224 像素的大小,这是 MobileNet 所期望的尺寸。
|
||||
|
||||
输出组件将是一个 `"label"`,它以美观的形式显示顶部标签。由于我们不想显示所有的 1,000 个类标签,所以我们将自定义它只显示前 3 个标签。
|
||||
|
||||
最后,我们还将添加一个 `examples` 参数,它允许我们使用一些预定义的示例预填充我们的接口。Gradio 的代码如下所示:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.Interface(fn=classify_image,
|
||||
inputs=gr.Image(shape=(224, 224)),
|
||||
outputs=gr.Label(num_top_classes=3),
|
||||
examples=["banana.jpg", "car.jpg"]).launch()
|
||||
```
|
||||
|
||||
这将生成以下界面,您可以在浏览器中立即尝试(尝试上传您自己的示例!):
|
||||
|
||||
<iframe src="https://abidlabs-keras-image-classifier.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
----------
|
||||
|
||||
完成!这就是构建图像分类器的 Web 演示所需的所有代码。如果您想与他人分享,请尝试在启动接口时设置 `share=True`!
|
||||
@ -0,0 +1,52 @@
|
||||
# Vision Transformers 图像分类
|
||||
|
||||
相关空间:https://huggingface.co/spaces/abidlabs/vision-transformer
|
||||
标签:VISION, TRANSFORMERS, HUB
|
||||
|
||||
## 简介
|
||||
|
||||
图像分类是计算机视觉中的重要任务。构建更好的分类器以确定图像中存在的对象是当前研究的热点领域,因为它在从人脸识别到制造质量控制等方面都有应用。
|
||||
|
||||
最先进的图像分类器基于 *transformers* 架构,该架构最初在自然语言处理任务中很受欢迎。这种架构通常被称为 vision transformers (ViT)。这些模型非常适合与 Gradio 的*图像*输入组件一起使用,因此在本教程中,我们将构建一个使用 Gradio 进行图像分类的 Web 演示。我们只需用**一行 Python 代码**即可构建整个 Web 应用程序,其效果如下(试用一下示例之一!):
|
||||
|
||||
<iframe src="https://abidlabs-vision-transformer.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 包。
|
||||
|
||||
## 步骤 1 - 选择 Vision 图像分类模型
|
||||
|
||||
首先,我们需要一个图像分类模型。在本教程中,我们将使用[Hugging Face Model Hub](https://huggingface.co/models?pipeline_tag=image-classification)上的一个模型。该 Hub 包含数千个模型,涵盖了多种不同的机器学习任务。
|
||||
|
||||
在左侧边栏中展开 Tasks 类别,并选择我们感兴趣的“Image Classification”作为我们的任务。然后,您将看到 Hub 上为图像分类设计的所有模型。
|
||||
|
||||
在撰写时,最受欢迎的模型是 `google/vit-base-patch16-224`,该模型在分辨率为 224x224 像素的 ImageNet 图像上进行了训练。我们将在演示中使用此模型。
|
||||
|
||||
## 步骤 2 - 使用 Gradio 加载 Vision Transformer 模型
|
||||
|
||||
当使用 Hugging Face Hub 上的模型时,我们无需为演示定义输入或输出组件。同样,我们不需要关心预处理或后处理的细节。所有这些都可以从模型标签中自动推断出来。
|
||||
|
||||
除了导入语句外,我们只需要一行代码即可加载并启动演示。
|
||||
|
||||
我们使用 `gr.Interface.load()` 方法,并传入包含 `huggingface/` 的模型路径,以指定它来自 Hugging Face Hub。
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.Interface.load(
|
||||
"huggingface/google/vit-base-patch16-224",
|
||||
examples=["alligator.jpg", "laptop.jpg"]).launch()
|
||||
```
|
||||
|
||||
请注意,我们添加了一个 `examples` 参数,允许我们使用一些预定义的示例预填充我们的界面。
|
||||
|
||||
这将生成以下接口,您可以直接在浏览器中尝试。当您输入图像时,它会自动进行预处理并发送到 Hugging Face Hub API,通过模型处理,并以人类可解释的预测结果返回。尝试上传您自己的图像!
|
||||
|
||||
<iframe src="https://abidlabs-vision-transformer.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
----------
|
||||
|
||||
完成!只需一行代码,您就建立了一个图像分类器的 Web 演示。如果您想与他人分享,请在 `launch()` 接口时设置 `share=True`。
|
||||
@ -0,0 +1,148 @@
|
||||
# 连接到数据库
|
||||
|
||||
相关空间:https://huggingface.co/spaces/gradio/chicago-bike-share-dashboard
|
||||
标签:TABULAR, PLOTS
|
||||
|
||||
## 介绍
|
||||
|
||||
本指南介绍如何使用 Gradio 连接您的应用程序到数据库。我们将会
|
||||
连接到在 AWS 上托管的 PostgreSQL 数据库,但 Gradio 对于您连接的数据库类型和托管位置没有任何限制。因此,只要您能编写 Python 代码来连接
|
||||
您的数据,您就可以使用 Gradio 在 Web 界面中显示它 💪
|
||||
|
||||
## 概述
|
||||
|
||||
我们将分析来自芝加哥的自行车共享数据。数据托管在 kaggle [这里](https://www.kaggle.com/datasets/evangower/cyclistic-bike-share?select=202203-divvy-tripdata.csv)。
|
||||
我们的目标是创建一个仪表盘,让我们的业务利益相关者能够回答以下问题:
|
||||
|
||||
1. 电动自行车是否比普通自行车更受欢迎?
|
||||
2. 哪些出发自行车站点最受欢迎?
|
||||
|
||||
在本指南结束时,我们将拥有一个如下所示的功能齐全的应用程序:
|
||||
|
||||
<gradio-app space="gradio/chicago-bike-share-dashboard"> </gradio-app>
|
||||
|
||||
## 步骤 1 - 创建数据库
|
||||
|
||||
我们将在 Amazon 的 RDS 服务上托管我们的数据。如果还没有 AWS 账号,请创建一个
|
||||
并在免费层级上创建一个 PostgreSQL 数据库。
|
||||
|
||||
**重要提示**:如果您计划在 HuggingFace Spaces 上托管此演示,请确保数据库在 **8080** 端口上。Spaces
|
||||
将阻止除端口 80、443 或 8080 之外的所有外部连接,如此[处所示](https://huggingface.co/docs/hub/spaces-overview#networking)。
|
||||
RDS 不允许您在 80 或 443 端口上创建 postgreSQL 实例。
|
||||
|
||||
创建完数据库后,从 Kaggle 下载数据集并将其上传到数据库中。
|
||||
为了演示的目的,我们只会上传 2022 年 3 月的数据。
|
||||
|
||||
## 步骤 2.a - 编写 ETL 代码
|
||||
我们将查询数据库,按自行车类型(电动、标准或有码)进行分组,并获取总骑行次数。
|
||||
我们还将查询每个站点的出发骑行次数,并获取前 5 个。
|
||||
|
||||
然后,我们将使用 matplotlib 将查询结果可视化。
|
||||
|
||||
我们将使用 pandas 的[read_sql](https://pandas.pydata.org/docs/reference/api/pandas.read_sql.html)
|
||||
方法来连接数据库。这需要安装 `psycopg2` 库。
|
||||
|
||||
为了连接到数据库,我们将指定数据库的用户名、密码和主机作为环境变量。
|
||||
这样可以通过避免将敏感信息以明文形式存储在应用程序文件中,使我们的应用程序更安全。
|
||||
|
||||
```python
|
||||
import os
|
||||
import pandas as pd
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
DB_USER = os.getenv("DB_USER")
|
||||
DB_PASSWORD = os.getenv("DB_PASSWORD")
|
||||
DB_HOST = os.getenv("DB_HOST")
|
||||
PORT = 8080
|
||||
DB_NAME = "bikeshare"
|
||||
|
||||
connection_string = f"postgresql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}?port={PORT}&dbname={DB_NAME}"
|
||||
|
||||
def get_count_ride_type():
|
||||
df = pd.read_sql(
|
||||
"""
|
||||
SELECT COUNT(ride_id) as n, rideable_type
|
||||
FROM rides
|
||||
GROUP BY rideable_type
|
||||
ORDER BY n DESC
|
||||
""",
|
||||
con=connection_string
|
||||
)
|
||||
fig_m, ax = plt.subplots()
|
||||
ax.bar(x=df['rideable_type'], height=df['n'])
|
||||
ax.set_title("Number of rides by bycycle type")
|
||||
ax.set_ylabel("Number of Rides")
|
||||
ax.set_xlabel("Bicycle Type")
|
||||
return fig_m
|
||||
|
||||
|
||||
def get_most_popular_stations():
|
||||
|
||||
df = pd.read_sql(
|
||||
"""
|
||||
SELECT COUNT(ride_id) as n, MAX(start_station_name) as station
|
||||
FROM RIDES
|
||||
WHERE start_station_name is NOT NULL
|
||||
GROUP BY start_station_id
|
||||
ORDER BY n DESC
|
||||
LIMIT 5
|
||||
""",
|
||||
con=connection_string
|
||||
)
|
||||
fig_m, ax = plt.subplots()
|
||||
ax.bar(x=df['station'], height=df['n'])
|
||||
ax.set_title("Most popular stations")
|
||||
ax.set_ylabel("Number of Rides")
|
||||
ax.set_xlabel("Station Name")
|
||||
ax.set_xticklabels(
|
||||
df['station'], rotation=45, ha="right", rotation_mode="anchor"
|
||||
)
|
||||
ax.tick_params(axis="x", labelsize=8)
|
||||
fig_m.tight_layout()
|
||||
return fig_m
|
||||
```
|
||||
|
||||
如果您在本地运行我们的脚本,可以像下面这样将凭据作为环境变量传递:
|
||||
|
||||
```bash
|
||||
DB_USER='username' DB_PASSWORD='password' DB_HOST='host' python app.py
|
||||
```
|
||||
|
||||
## 步骤 2.c - 编写您的 gradio 应用程序
|
||||
我们将使用两个单独的 `gr.Plot` 组件将我们的 matplotlib 图表并排显示在一起,使用 `gr.Row()`。
|
||||
因为我们已经在 `demo.load()` 事件触发器中封装了获取数据的函数,
|
||||
我们的演示将在每次网页加载时从数据库**动态**获取最新数据。🪄
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
bike_type = gr.Plot()
|
||||
station = gr.Plot()
|
||||
|
||||
demo.load(get_count_ride_type, inputs=None, outputs=bike_type)
|
||||
demo.load(get_most_popular_stations, inputs=None, outputs=station)
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
## 步骤 3 - 部署
|
||||
如果您运行上述代码,您的应用程序将在本地运行。
|
||||
您甚至可以通过将 `share=True` 参数传递给 `launch` 来获得一个临时共享链接。
|
||||
|
||||
但是如果您想要一个永久的部署解决方案呢?
|
||||
让我们将我们的 Gradio 应用程序部署到免费的 HuggingFace Spaces 平台上。
|
||||
|
||||
如果您之前没有使用过 Spaces,请按照之前的指南[这里](/using_hugging_face_integrations)进行操作。
|
||||
您将需要将 `DB_USER`、`DB_PASSWORD` 和 `DB_HOST` 变量添加为 "Repo Secrets"。您可以在 " 设置 " 选项卡中进行此操作。
|
||||
|
||||

|
||||
|
||||
## 结论
|
||||
恭喜你!您知道如何将您的 Gradio 应用程序连接到云端托管的数据库!☁️
|
||||
|
||||
我们的仪表板现在正在[Spaces](https://huggingface.co/spaces/gradio/chicago-bike-share-dashboard)上运行。
|
||||
完整代码在[这里](https://huggingface.co/spaces/gradio/chicago-bike-share-dashboard/blob/main/app.py)
|
||||
|
||||
正如您所见,Gradio 使您可以连接到您的数据并以您想要的方式显示!🔥
|
||||
@ -0,0 +1,122 @@
|
||||
# 从 BigQuery 数据创建实时仪表盘
|
||||
|
||||
Tags: 表格 , 仪表盘 , 绘图
|
||||
|
||||
[Google BigQuery](https://cloud.google.com/bigquery) 是一个基于云的用于处理大规模数据集的服务。它是一个无服务器且高度可扩展的数据仓库解决方案,使用户能够使用类似 SQL 的查询分析数据。
|
||||
|
||||
在本教程中,我们将向您展示如何使用 `gradio` 在 Python 中查询 BigQuery 数据集并在实时仪表盘中显示数据。仪表板将如下所示:
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/bigquery-dashboard.gif">
|
||||
|
||||
在本指南中,我们将介绍以下步骤:
|
||||
|
||||
1. 设置 BigQuery 凭据
|
||||
2. 使用 BigQuery 客户端
|
||||
3. 构建实时仪表盘(仅需 *7 行 Python 代码*)
|
||||
|
||||
我们将使用[纽约时报的 COVID 数据集](https://www.nytimes.com/interactive/2021/us/covid-cases.html),该数据集作为一个公共数据集可在 BigQuery 上使用。数据集名为 `covid19_nyt.us_counties`,其中包含有关美国各县 COVID 确诊病例和死亡人数的最新信息。
|
||||
|
||||
**先决条件**:本指南使用 [Gradio Blocks](../quickstart/#blocks-more-flexibility-and-control),因此请确保您熟悉 Blocks 类。
|
||||
|
||||
## 设置 BigQuery 凭据
|
||||
|
||||
要使用 Gradio 和 BigQuery,您需要获取您的 BigQuery 凭据,并将其与 [BigQuery Python 客户端](https://pypi.org/project/google-cloud-bigquery/) 一起使用。如果您已经拥有 BigQuery 凭据(作为 `.json` 文件),则可以跳过此部分。否则,您可以在几分钟内免费完成此操作。
|
||||
|
||||
1. 首先,登录到您的 Google Cloud 帐户,并转到 Google Cloud 控制台 (https://console.cloud.google.com/)
|
||||
|
||||
2. 在 Cloud 控制台中,单击左上角的汉堡菜单,然后从菜单中选择“API 与服务”。如果您没有现有项目,则需要创建一个项目。
|
||||
|
||||
3. 然后,单击“+ 启用的 API 与服务”按钮,该按钮允许您为项目启用特定服务。搜索“BigQuery API”,单击它,然后单击“启用”按钮。如果您看到“管理”按钮,则表示 BigQuery 已启用,您已准备就绪。
|
||||
|
||||
4. 在“API 与服务”菜单中,单击“凭据”选项卡,然后单击“创建凭据”按钮。
|
||||
|
||||
5. 在“创建凭据”对话框中,选择“服务帐号密钥”作为要创建的凭据类型,并为其命名。还可以通过为其授予角色(例如“BigQuery 用户”)为服务帐号授予权限,从而允许您运行查询。
|
||||
|
||||
6. 在选择服务帐号后,选择“JSON”密钥类型,然后单击“创建”按钮。这将下载包含您凭据的 JSON 密钥文件到您的计算机。它的外观类似于以下内容:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "service_account",
|
||||
"project_id": "your project",
|
||||
"private_key_id": "your private key id",
|
||||
"private_key": "private key",
|
||||
"client_email": "email",
|
||||
"client_id": "client id",
|
||||
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
|
||||
"token_uri": "https://accounts.google.com/o/oauth2/token",
|
||||
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
|
||||
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
|
||||
}
|
||||
```
|
||||
|
||||
## 使用 BigQuery 客户端
|
||||
|
||||
获得凭据后,您需要使用 BigQuery Python 客户端使用您的凭据进行身份验证。为此,您需要在终端中运行以下命令安装 BigQuery Python 客户端:
|
||||
|
||||
```bash
|
||||
pip install google-cloud-bigquery[pandas]
|
||||
```
|
||||
|
||||
您会注意到我们已安装了 pandas 插件,这对于将 BigQuery 数据集处理为 pandas 数据帧将非常有用。安装了客户端之后,您可以通过运行以下代码使用您的凭据进行身份验证:
|
||||
|
||||
```py
|
||||
from google.cloud import bigquery
|
||||
|
||||
client = bigquery.Client.from_service_account_json("path/to/key.json")
|
||||
```
|
||||
|
||||
完成凭据身份验证后,您现在可以使用 BigQuery Python 客户端与您的 BigQuery 数据集进行交互。
|
||||
|
||||
以下是一个示例函数,该函数在 BigQuery 中查询 `covid19_nyt.us_counties` 数据集,以显示截至当前日期的确诊人数最多的前 20 个县:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
QUERY = (
|
||||
'SELECT * FROM `bigquery-public-data.covid19_nyt.us_counties` '
|
||||
'ORDER BY date DESC,confirmed_cases DESC '
|
||||
'LIMIT 20')
|
||||
|
||||
def run_query():
|
||||
query_job = client.query(QUERY)
|
||||
query_result = query_job.result()
|
||||
df = query_result.to_dataframe()
|
||||
# Select a subset of columns
|
||||
df = df[["confirmed_cases", "deaths", "county", "state_name"]]
|
||||
# Convert numeric columns to standard numpy types
|
||||
df = df.astype({"deaths": np.int64, "confirmed_cases": np.int64})
|
||||
return df
|
||||
```
|
||||
|
||||
## 构建实时仪表盘
|
||||
|
||||
一旦您有了查询数据的函数,您可以使用 Gradio 库的 `gr.DataFrame` 组件以表格形式显示结果。这是一种检查数据并确保查询正确的有用方式。
|
||||
|
||||
以下是如何使用 `gr.DataFrame` 组件显示结果的示例。通过将 `run_query` 函数传递给 `gr.DataFrame`,我们指示 Gradio 在页面加载时立即运行该函数并显示结果。此外,您还可以传递关键字 `every`,以告知仪表板每小时刷新一次(60*60 秒)。
|
||||
|
||||
```py
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.DataFrame(run_query, every=60*60)
|
||||
|
||||
demo.queue().launch() # Run the demo using queuing
|
||||
```
|
||||
|
||||
也许您想在我们的仪表盘中添加一个可视化效果。您可以使用 `gr.ScatterPlot()` 组件将数据可视化为散点图。这可以让您查看数据中不同变量(例如病例数和死亡数)之间的关系,并可用于探索数据和获取见解。同样,我们可以实时完成这一操作
|
||||
通过传递 `every` 参数。
|
||||
|
||||
以下是一个完整示例,展示了如何在显示数据时使用 `gr.ScatterPlot` 来进行可视化。
|
||||
|
||||
```py
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.Markdown("# 💉 Covid Dashboard (Updated Hourly)")
|
||||
with gr.Row():
|
||||
gr.DataFrame(run_query, every=60*60)
|
||||
gr.ScatterPlot(run_query, every=60*60, x="confirmed_cases",
|
||||
y="deaths", tooltip="county", width=500, height=500)
|
||||
|
||||
demo.queue().launch() # Run the demo with queuing enabled
|
||||
```
|
||||
@ -0,0 +1,121 @@
|
||||
# 从 Supabase 数据创建仪表盘
|
||||
Tags: TABULAR, DASHBOARD, PLOTS
|
||||
|
||||
[Supabase](https://supabase.com/) 是一个基于云的开源后端,提供了 PostgreSQL 数据库、身份验证和其他有用的功能,用于构建 Web 和移动应用程序。在本教程中,您将学习如何从 Supabase 读取数据,并在 Gradio 仪表盘上以**实时**方式绘制数据。
|
||||
|
||||
**先决条件 :** 要开始,您需要一个免费的 Supabase 账户,您可以在此处注册:[https://app.supabase.com/](https://app.supabase.com/)
|
||||
|
||||
在这个端到端指南中,您将学习如何:
|
||||
|
||||
* 在 Supabase 中创建表
|
||||
* 使用 Supabase Python 客户端向 Supabase 写入数据
|
||||
* 使用 Gradio 在实时仪表盘中可视化数据
|
||||
|
||||
如果您已经在 Supabase 上有数据想要在仪表盘中可视化,您可以跳过前两个部分,直接到[可视化数据](#visualize-the-data-in-a-real-time-gradio-dashboard)!
|
||||
|
||||
## 在 Supabase 中创建表
|
||||
|
||||
首先,我们需要一些要可视化的数据。根据这个[出色的指南](https://supabase.com/blog/loading-data-supabase-python),我们将创建一些虚假的商务数据,并将其放入 Supabase 中。
|
||||
|
||||
1\. 在 Supabase 中创建一个新项目。一旦您登录,点击 "New Project" 按钮
|
||||
|
||||
2\. 给您的项目命名并设置数据库密码。您还可以选择定价计划(对于我们来说,免费计划已足够!)
|
||||
|
||||
3\. 在数据库启动时(可能需要多达 2 分钟),您将看到您的 API 密钥。
|
||||
|
||||
4\. 在左侧窗格中单击 "Table Editor"(表图标)以创建一个新表。我们将创建一个名为 `Product` 的单表,具有以下模式:
|
||||
|
||||
<center>
|
||||
<table>
|
||||
<tr><td>product_id</td><td>int8</td></tr>
|
||||
<tr><td>inventory_count</td><td>int8</td></tr>
|
||||
<tr><td>price</td><td>float8</td></tr>
|
||||
<tr><td>product_name</td><td>varchar</td></tr>
|
||||
</table>
|
||||
</center>
|
||||
|
||||
5\. 点击保存以保存表结构。
|
||||
|
||||
我们的表已经准备好了!
|
||||
|
||||
## 将数据写入 Supabase
|
||||
|
||||
下一步是向 Supabase 数据集中写入数据。我们将使用 Supabase Python 库来完成这个任务。
|
||||
|
||||
6\. 通过在终端中运行以下命令来安装 `supabase` 库:
|
||||
|
||||
```bash
|
||||
pip install supabase
|
||||
```
|
||||
|
||||
7\. 获取项目 URL 和 API 密钥。点击左侧窗格上的设置(齿轮图标),然后点击 'API'。URL 列在项目 URL 框中,API 密钥列在项目 API 密钥(带有 `service_role`、`secret` 标签)中
|
||||
|
||||
8\. 现在,运行以下 Python 脚本将一些虚假数据写入表中(注意您需要在步骤 7 中放入 `SUPABASE_URL` 和 `SUPABASE_SECRET_KEY` 的值):
|
||||
|
||||
```python
|
||||
import supabase
|
||||
|
||||
# 初始化Supabase客户端
|
||||
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
|
||||
|
||||
# 定义要写入的数据
|
||||
import random
|
||||
|
||||
main_list = []
|
||||
for i in range(10):
|
||||
value = {'product_id': i,
|
||||
'product_name': f"Item {i}",
|
||||
'inventory_count': random.randint(1, 100),
|
||||
'price': random.random()*100
|
||||
}
|
||||
main_list.append(value)
|
||||
|
||||
# 将数据写入表中
|
||||
data = client.table('Product').insert(main_list).execute()
|
||||
```
|
||||
|
||||
返回 Supabase 仪表板并刷新页面,您将看到 10 行数据填充到 `Product` 表中!
|
||||
|
||||
## 在实时 Gradio 仪表盘中可视化数据
|
||||
|
||||
最后,我们将使用相同的 `supabase` Python 库从 Supabase 数据集中读取数据,并使用 `gradio` 创建一个实时仪表盘。
|
||||
|
||||
注意:我们在本节中重复了某些步骤(比如创建 Supabase 客户端),以防您没有完成之前的部分。如第 7 步所述,您将需要数据库的项目 URL 和 API 密钥。
|
||||
|
||||
9\. 编写一个函数,从 `Product` 表加载数据并将其作为 pandas DataFrame 返回:
|
||||
|
||||
import supabase
|
||||
```python
|
||||
import supabase
|
||||
import pandas as pd
|
||||
|
||||
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
|
||||
|
||||
def read_data():
|
||||
response = client.table('Product').select("*").execute()
|
||||
df = pd.DataFrame(response.data)
|
||||
return df
|
||||
```
|
||||
|
||||
10\. 使用两个条形图创建一个小的 Gradio 仪表盘,每分钟绘制所有项目的价格和库存量,并实时更新:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as dashboard:
|
||||
with gr.Row():
|
||||
gr.BarPlot(read_data, x="product_id", y="price", title="价格", every=60)
|
||||
gr.BarPlot(read_data, x="product_id", y="inventory_count", title="库存", every=60)
|
||||
|
||||
dashboard.queue().launch()
|
||||
```
|
||||
|
||||
请注意,通过将函数传递给 `gr.BarPlot()`,我们可以在网络应用加载时查询数据库(然后每 60 秒查询一次,因为有 `every` 参数)。您的最终仪表盘应如下所示:
|
||||
|
||||
<gradio-app space="abidlabs/supabase"></gradio-app>
|
||||
|
||||
## 结论
|
||||
|
||||
就是这样!在本教程中,您学习了如何将数据写入 Supabase 数据集,然后读取该数据并将结果绘制为条形图。如果您更新 Supabase 数据库中的数据,您会注意到 Gradio 仪表盘将在一分钟内更新。
|
||||
|
||||
尝试在此示例中添加更多绘图和可视化(或使用不同的数据集),以构建一个更复杂的仪表盘!
|
||||
@ -0,0 +1,105 @@
|
||||
# 从 Google Sheets 创建实时仪表盘
|
||||
Tags: TABULAR, DASHBOARD, PLOTS
|
||||
[Google Sheets](https://www.google.com/sheets/about/) 是一种以电子表格形式存储表格数据的简便方法。借助 Gradio 和 pandas,可以轻松从公共或私有 Google Sheets 读取数据,然后显示数据或绘制数据。在本博文中,我们将构建一个小型 *real-time* 仪表盘,该仪表盘在 Google Sheets 中的数据更新时进行更新。
|
||||
构建仪表盘本身只需要使用 Gradio 的 9 行 Python 代码,我们的最终仪表盘如下所示:
|
||||
<gradio-app space="gradio/line-plot"></gradio-app>
|
||||
|
||||
**先决条件**:本指南使用[Gradio Blocks](../quickstart/#blocks-more-flexibility-and-control),因此请确保您熟悉 Blocks 类。
|
||||
具体步骤略有不同,具体取决于您是使用公开访问还是私有 Google Sheet。我们将分别介绍这两种情况,所以让我们开始吧!
|
||||
## Public Google Sheets
|
||||
由于[`pandas` 库](https://pandas.pydata.org/)的存在,从公共 Google Sheet 构建仪表盘非常简单:
|
||||
1. 获取要使用的 Google Sheets 的网址。为此,只需进入 Google Sheets,单击右上角的“共享”按钮,然后单击“获取可共享链接”按钮。这将给您一个类似于以下示例的网址:
|
||||
```html
|
||||
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
|
||||
```
|
||||
|
||||
2. 现在,修改此网址并使用它从 Google Sheets 读取数据到 Pandas DataFrame 中。 (在下面的代码中,用您的公开 Google Sheet 的网址替换 `URL` 变量):
|
||||
```python
|
||||
import pandas as pd
|
||||
URL = "https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0"csv_url = URL.replace('/edit#gid=', '/export?format=csv&gid=')
|
||||
def get_data():
|
||||
return pd.read_csv(csv_url)
|
||||
```
|
||||
|
||||
3. 数据查询是一个函数,这意味着可以使用 `gr.DataFrame` 组件实时显示或使用 `gr.LinePlot` 组件实时绘制数据(当然,根据数据的不同,可能需要不同的绘图方法)。只需将函数传递给相应的组件,并根据组件刷新的频率(以秒为单位)设置 `every` 参数。以下是 Gradio 代码:
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.Markdown("# 📈 Real-Time Line Plot")
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
gr.DataFrame(get_data, every=5)
|
||||
with gr.Column():
|
||||
gr.LinePlot(get_data, every=5, x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
|
||||
|
||||
demo.queue().launch() # Run the demo with queuing enabled
|
||||
```
|
||||
|
||||
到此为止!您现在拥有一个仪表盘,每 5 秒刷新一次,从 Google Sheets 中获取数据。
|
||||
## 私有 Google Sheets
|
||||
对于私有 Google Sheets,流程需要更多的工作量,但并不多!关键区别在于,现在您必须经过身份验证,以授权访问私有 Google Sheets。
|
||||
|
||||
### 身份验证
|
||||
要进行身份验证,需从 Google Cloud 获取凭据。以下是[如何设置 Google Cloud 凭据](https://developers.google.com/workspace/guides/create-credentials):
|
||||
1. 首先,登录您的 Google Cloud 帐户并转到 Google Cloud 控制台(https://console.cloud.google.com/)
|
||||
2. 在 Cloud 控制台中,单击左上角的汉堡菜单,然后从菜单中选择“API 和服务”。如果您没有现有项目,则需要创建一个。
|
||||
3. 然后,点击“+ 启用的 API 和服务”按钮,允许您为项目启用特定的服务。搜索“Google Sheets API”,点击它,然后单击“启用”按钮。如果看到“管理”按钮,则表示 Google Sheets 已启用,并且您已准备就绪。
|
||||
4. 在 API 和服务菜单中,点击“凭据”选项卡,然后点击“创建凭据”按钮。
|
||||
5. 在“创建凭据”对话框中,选择“服务帐号密钥”作为要创建的凭据类型,并为其命名。**记下服务帐号的电子邮件地址**
|
||||
6. 在选择服务帐号之后,选择“JSON”密钥类型,然后点击“创建”按钮。这将下载包含您凭据的 JSON 密钥文件到您的计算机。文件类似于以下示例:
|
||||
```json
|
||||
{
|
||||
"type": "service_account",
|
||||
"project_id": "your project",
|
||||
"private_key_id": "your private key id",
|
||||
"private_key": "private key",
|
||||
"client_email": "email",
|
||||
"client_id": "client id",
|
||||
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
|
||||
"token_uri": "https://accounts.google.com/o/oauth2/token",
|
||||
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
|
||||
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
|
||||
}
|
||||
```
|
||||
|
||||
### 查询
|
||||
在获得凭据的 `.json` 文件后,可以按照以下步骤查询您的 Google Sheet:
|
||||
1. 单击 Google Sheet 右上角的“共享”按钮。使用身份验证子部分第 5 步的服务的电子邮件地址共享 Google Sheets(此步骤很重要!)。然后单击“获取可共享链接”按钮。这将给您一个类似于以下示例的网址:
|
||||
```html
|
||||
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
|
||||
```
|
||||
|
||||
2. 安装 [`gspread` 库](https://docs.gspread.org/en/v5.7.0/),通过在终端运行以下命令使 Python 中使用 [Google Sheets API](https://developers.google.com/sheets/api/guides/concepts) 更加简单:`pip install gspread`
|
||||
3. 编写一个函数来从 Google Sheet 中加载数据,如下所示(用您的私有 Google Sheet 的 URL 替换 `URL` 变量):
|
||||
```python
|
||||
import gspreadimport pandas as pd
|
||||
# 与 Google 进行身份验证并获取表格URL = 'https://docs.google.com/spreadsheets/d/1_91Vps76SKOdDQ8cFxZQdgjTJiz23375sAT7vPvaj4k/edit#gid=0'
|
||||
gc = gspread.service_account("path/to/key.json")sh = gc.open_by_url(URL)worksheet = sh.sheet1
|
||||
def get_data():
|
||||
values = worksheet.get_all_values()
|
||||
df = pd.DataFrame(values[1:], columns=values[0])
|
||||
return df
|
||||
```
|
||||
|
||||
4\. 数据查询是一个函数,这意味着可以使用 `gr.DataFrame` 组件实时显示数据,或使用 `gr.LinePlot` 组件实时绘制数据(当然,根据数据的不同,可能需要使用不同的图表)。要实现这一点,只需将函数传递给相应的组件,并根据需要设置 `every` 参数来确定组件刷新的频率(以秒为单位)。以下是 Gradio 代码:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.Markdown("# 📈 实时折线图")
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
gr.DataFrame(get_data, every=5)
|
||||
with gr.Column():
|
||||
gr.LinePlot(get_data, every=5, x="日期", y="销售额", y_title="销售额(百万美元)", overlay_point=True, width=500, height=500)
|
||||
|
||||
demo.queue().launch() # 启动带有排队功能的演示
|
||||
```
|
||||
|
||||
现在你有一个每 5 秒刷新一次的仪表盘,可以从你的 Google 表格中获取数据。
|
||||
|
||||
## 结论
|
||||
|
||||
就是这样!只需几行代码,你就可以使用 `gradio` 和其他库从公共或私有的 Google 表格中读取数据,然后在实时仪表盘中显示和绘制数据。
|
||||
@ -0,0 +1,110 @@
|
||||
# 如何使用地图组件绘制图表
|
||||
Related spaces:
|
||||
Tags: PLOTS, MAPS
|
||||
|
||||
## 简介
|
||||
|
||||
本指南介绍如何使用 Gradio 的 `Plot` 组件在地图上绘制地理数据。Gradio 的 `Plot` 组件可以与 Matplotlib、Bokeh 和 Plotly 一起使用。在本指南中,我们将使用 Plotly 进行操作。Plotly 可以让开发人员轻松创建各种地图来展示他们的地理数据。点击[这里](https://plotly.com/python/maps/)查看一些示例。
|
||||
|
||||
## 概述
|
||||
|
||||
我们将使用纽约市的 Airbnb 数据集,该数据集托管在 kaggle 上,点击[这里](https://www.kaggle.com/datasets/dgomonov/new-york-city-airbnb-open-data)。我已经将其上传到 Hugging Face Hub 作为一个数据集,方便使用和下载,点击[这里](https://huggingface.co/datasets/gradio/NYC-Airbnb-Open-Data)。使用这些数据,我们将在地图上绘制 Airbnb 的位置,并允许基于价格和位置进行筛选。下面是我们将要构建的演示。 ⚡️
|
||||
|
||||
$demo_map_airbnb
|
||||
|
||||
## 步骤 1-加载 CSV 数据 💾
|
||||
|
||||
让我们首先从 Hugging Face Hub 加载纽约市的 Airbnb 数据。
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
dataset = load_dataset("gradio/NYC-Airbnb-Open-Data", split="train")
|
||||
df = dataset.to_pandas()
|
||||
|
||||
def filter_map(min_price, max_price, boroughs):
|
||||
new_df = df[(df['neighbourhood_group'].isin(boroughs)) &
|
||||
(df['price'] > min_price) & (df['price'] < max_price)]
|
||||
names = new_df["name"].tolist()
|
||||
prices = new_df["price"].tolist()
|
||||
text_list = [(names[i], prices[i]) for i in range(0, len(names))]
|
||||
```
|
||||
|
||||
在上面的代码中,我们先将 CSV 数据加载到一个 pandas dataframe 中。让我们首先定义一个函数,这将作为 gradio 应用程序的预测函数。该函数将接受最低价格、最高价格范围和筛选结果地区的列表作为参数。我们可以使用传入的值 (`min_price`、`max_price` 和地区列表) 来筛选数据框并创建 `new_df`。接下来,我们将创建包含每个 Airbnb 的名称和价格的 `text_list`,以便在地图上使用作为标签。
|
||||
|
||||
## 步骤 2-地图图表 🌐
|
||||
|
||||
Plotly 使得处理地图变得很容易。让我们看一下下面的代码,了解如何创建地图图表。
|
||||
|
||||
```python
|
||||
import plotly.graph_objects as go
|
||||
|
||||
fig = go.Figure(go.Scattermapbox(
|
||||
customdata=text_list,
|
||||
lat=new_df['latitude'].tolist(),
|
||||
lon=new_df['longitude'].tolist(),
|
||||
mode='markers',
|
||||
marker=go.scattermapbox.Marker(
|
||||
size=6
|
||||
),
|
||||
hoverinfo="text",
|
||||
hovertemplate='<b>Name</b>: %{customdata[0]}<br><b>Price</b>: $%{customdata[1]}'
|
||||
))
|
||||
|
||||
fig.update_layout(
|
||||
mapbox_style="open-street-map",
|
||||
hovermode='closest',
|
||||
mapbox=dict(
|
||||
bearing=0,
|
||||
center=go.layout.mapbox.Center(
|
||||
lat=40.67,
|
||||
lon=-73.90
|
||||
),
|
||||
pitch=0,
|
||||
zoom=9
|
||||
),
|
||||
)
|
||||
```
|
||||
|
||||
上面的代码中,我们通过传入经纬度列表来创建一个散点图。我们还传入了名称和价格的自定义数据,以便在鼠标悬停在每个标记上时显示额外的信息。接下来,我们使用 `update_layout` 来指定其他地图设置,例如缩放和居中。
|
||||
|
||||
有关使用 Mapbox 和 Plotly 创建散点图的更多信息,请点击[这里](https://plotly.com/python/scattermapbox/)。
|
||||
|
||||
## 步骤 3-Gradio 应用程序 ⚡️
|
||||
|
||||
我们将使用两个 `gr.Number` 组件和一个 `gr.CheckboxGroup` 组件,允许用户指定价格范围和地区位置。然后,我们将使用 `gr.Plot` 组件作为我们之前创建的 Plotly + Mapbox 地图的输出。
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
min_price = gr.Number(value=250, label="Minimum Price")
|
||||
max_price = gr.Number(value=1000, label="Maximum Price")
|
||||
boroughs = gr.CheckboxGroup(choices=["Queens", "Brooklyn", "Manhattan", "Bronx", "Staten Island"], value=["Queens", "Brooklyn"], label="Select Boroughs:")
|
||||
btn = gr.Button(value="Update Filter")
|
||||
map = gr.Plot()
|
||||
demo.load(filter_map, [min_price, max_price, boroughs], map)
|
||||
btn.click(filter_map, [min_price, max_price, boroughs], map)
|
||||
```
|
||||
|
||||
我们使用 `gr.Column` 和 `gr.Row` 布局这些组件,并为演示加载时和点击 " 更新筛选 " 按钮时添加了事件触发器,以触发地图更新新的筛选条件。
|
||||
|
||||
以下是完整演示代码:
|
||||
|
||||
$code_map_airbnb
|
||||
|
||||
## 步骤 4-部署 Deployment 🤗
|
||||
|
||||
如果你运行上面的代码,你的应用程序将在本地运行。
|
||||
如果要获取临时共享链接,可以将 `share=True` 参数传递给 `launch`。
|
||||
|
||||
但如果你想要一个永久的部署解决方案呢?
|
||||
让我们将我们的 Gradio 应用程序部署到免费的 HuggingFace Spaces 平台。
|
||||
|
||||
如果你以前没有使用过 Spaces,请按照之前的指南[这里](/using_hugging_face_integrations)。
|
||||
|
||||
## 结论 🎉
|
||||
|
||||
你已经完成了!这是构建地图演示所需的所有代码。
|
||||
|
||||
链接到演示:[地图演示](https://huggingface.co/spaces/gradio/map_airbnb)和[完整代码](https://huggingface.co/spaces/gradio/map_airbnb/blob/main/run.py)(在 Hugging Face Spaces)
|
||||
@ -0,0 +1,103 @@
|
||||
## 使用 Gradio 进行表格数据科学工作流
|
||||
|
||||
Related spaces: https://huggingface.co/spaces/scikit-learn/gradio-skops-integration,https://huggingface.co/spaces/scikit-learn/tabular-playground,https://huggingface.co/spaces/merve/gradio-analysis-dashboard
|
||||
|
||||
## 介绍
|
||||
|
||||
表格数据科学是机器学习中应用最广泛的领域,涉及的问题从客户分割到流失预测不等。在表格数据科学工作流的各个阶段中,将工作内容传达给利益相关者或客户可能很麻烦,这会阻碍数据科学家专注于重要事项,如数据分析和模型构建。数据科学家可能会花费数小时构建一个接受 DataFrame 并返回图表、预测或数据集中的聚类图的仪表板。在本指南中,我们将介绍如何使用 `gradio` 改进您的数据科学工作流程。我们还将讨论如何使用 `gradio` 和[skops](https://skops.readthedocs.io/en/stable/)一行代码即可构建界面!
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 软件包。
|
||||
|
||||
## 让我们创建一个简单的界面!
|
||||
|
||||
我们将看一下如何创建一个简单的界面,该界面根据产品信息预测故障。
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
import pandas as pd
|
||||
import joblib
|
||||
import datasets
|
||||
|
||||
|
||||
inputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(4,"dynamic"), label="Input Data", interactive=1)]
|
||||
|
||||
outputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(1, "fixed"), label="Predictions", headers=["Failures"])]
|
||||
|
||||
model = joblib.load("model.pkl")
|
||||
|
||||
# we will give our dataframe as example
|
||||
df = datasets.load_dataset("merve/supersoaker-failures")
|
||||
df = df["train"].to_pandas()
|
||||
|
||||
def infer(input_dataframe):
|
||||
return pd.DataFrame(model.predict(input_dataframe))
|
||||
|
||||
gr.Interface(fn = infer, inputs = inputs, outputs = outputs, examples = [[df.head(2)]]).launch()
|
||||
```
|
||||
|
||||
让我们来解析上述代码。
|
||||
|
||||
* `fn`:推理函数,接受输入数据帧并返回预测结果。
|
||||
* `inputs`:我们使用 `Dataframe` 组件作为输入。我们将输入定义为具有 2 行 4 列的数据帧,最初的数据帧将呈现出上述形状的空数据帧。当将 `row_count` 设置为 `dynamic` 时,不必依赖于正在输入的数据集来预定义组件。
|
||||
* `outputs`:用于存储输出的数据帧组件。该界面可以接受单个或多个样本进行推断,并在一列中为每个样本返回 0 或 1,因此我们将 `row_count` 设置为 2,`col_count` 设置为 1。`headers` 是由数据帧的列名组成的列表。
|
||||
* `examples`:您可以通过拖放 CSV 文件或通过示例传递 pandas DataFrame,界面会自动获取其标题。
|
||||
|
||||
现在我们将为简化版数据可视化仪表板创建一个示例。您可以在相关空间中找到更全面的版本。
|
||||
|
||||
<gradio-app space="gradio/tabular-playground"></gradio-app>
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
import pandas as pd
|
||||
import datasets
|
||||
import seaborn as sns
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
df = datasets.load_dataset("merve/supersoaker-failures")
|
||||
df = df["train"].to_pandas()
|
||||
df.dropna(axis=0, inplace=True)
|
||||
|
||||
def plot(df):
|
||||
plt.scatter(df.measurement_13, df.measurement_15, c = df.loading,alpha=0.5)
|
||||
plt.savefig("scatter.png")
|
||||
df['failure'].value_counts().plot(kind='bar')
|
||||
plt.savefig("bar.png")
|
||||
sns.heatmap(df.select_dtypes(include="number").corr())
|
||||
plt.savefig("corr.png")
|
||||
plots = ["corr.png","scatter.png", "bar.png"]
|
||||
return plots
|
||||
|
||||
inputs = [gr.Dataframe(label="Supersoaker Production Data")]
|
||||
outputs = [gr.Gallery(label="Profiling Dashboard").style(grid=(1,3))]
|
||||
|
||||
gr.Interface(plot, inputs=inputs, outputs=outputs, examples=[df.head(100)], title="Supersoaker Failures Analysis Dashboard").launch()
|
||||
```
|
||||
|
||||
<gradio-app space="gradio/gradio-analysis-dashboard-minimal"></gradio-app>
|
||||
|
||||
我们将使用与训练模型相同的数据集,但这次我们将创建一个可视化仪表板以展示它。
|
||||
|
||||
* `fn`:根据数据创建图表的函数。
|
||||
* `inputs`:我们使用了与上述相同的 `Dataframe` 组件。
|
||||
* `outputs`:我们使用 `Gallery` 组件来存放我们的可视化结果。
|
||||
* `examples`:我们将数据集本身作为示例。
|
||||
|
||||
## 使用 skops 一行代码轻松加载表格数据界面
|
||||
|
||||
`skops` 是一个构建在 `huggingface_hub` 和 `sklearn` 之上的库。通过最新的 `gradio` 集成,您可以使用一行代码构建表格数据界面!
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
# 标题和描述是可选的
|
||||
title = "Supersoaker产品缺陷预测"
|
||||
description = "该模型预测Supersoaker生产线故障。在下面的数据帧组件中,您可以拖放数据集的任意切片或自行编辑值。"
|
||||
|
||||
gr.Interface.load("huggingface/scikit-learn/tabular-playground", title=title, description=description).launch()
|
||||
```
|
||||
|
||||
<gradio-app space="gradio/gradio-skops-integration"></gradio-app>
|
||||
|
||||
使用 `skops` 将 `sklearn` 模型推送到 Hugging Face Hub 时,会包含一个包含示例输入和列名的 `config.json` 文件,解决的任务类型是 `tabular-classification` 或 `tabular-regression`。根据任务类型,`gradio` 构建界面并使用列名和示例输入来构建它。您可以[参考 skops 在 Hub 上托管模型的文档](https://skops.readthedocs.io/en/latest/auto_examples/plot_hf_hub.html#sphx-glr-auto-examples-plot-hf-hub-py)来了解如何使用 `skops` 将模型推送到 Hub。
|
||||
@ -0,0 +1,260 @@
|
||||
# 使用 Gradio Python 客户端入门
|
||||
|
||||
Tags: CLIENT, API, SPACES
|
||||
|
||||
Gradio Python 客户端使得将任何 Gradio 应用程序作为 API 使用变得非常容易。例如,考虑一下从麦克风录制的[Whisper 音频文件](https://huggingface.co/spaces/abidlabs/whisper)的转录。
|
||||
|
||||
|
||||
|
||||
使用 `gradio_client` 库,我们可以轻松地将 Gradio 用作 API,以编程方式转录音频文件。
|
||||
|
||||
下面是完成此操作的整个代码:
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("abidlabs/whisper")
|
||||
client.predict("audio_sample.wav")
|
||||
|
||||
>> "这是Whisper语音识别模型的测试。"
|
||||
```
|
||||
|
||||
Gradio 客户端适用于任何托管在 Hugging Face Spaces 上的 Gradio 应用程序,无论是图像生成器、文本摘要生成器、有状态聊天机器人、税金计算器还是其他任何应用程序!Gradio 客户端主要用于托管在[Hugging Face Spaces](https://hf.space)上的应用程序,但你的应用程序可以托管在任何地方,比如你自己的服务器。
|
||||
|
||||
**先决条件**:要使用 Gradio 客户端,你不需要详细了解 `gradio` 库。但是,了解 Gradio 的输入和输出组件的概念会有所帮助。
|
||||
|
||||
## 安装
|
||||
|
||||
如果你已经安装了最新版本的 `gradio`,那么 `gradio_client` 就作为依赖项包含在其中。
|
||||
|
||||
否则,可以使用 pip(或 pip3)安装轻量级的 `gradio_client` 包,并且已经测试可以在 Python 3.9 或更高版本上运行:
|
||||
|
||||
```bash
|
||||
$ pip install gradio_client
|
||||
```
|
||||
|
||||
## 连接到运行中的 Gradio 应用程序
|
||||
|
||||
首先创建一个 `Client` 对象,并将其连接到运行在 Hugging Face Spaces 上或其他任何地方的 Gradio 应用程序。
|
||||
|
||||
## 连接到 Hugging Face 空间
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("abidlabs/en2fr") # 一个将英文翻译为法文的Space
|
||||
```
|
||||
|
||||
你还可以通过在 `hf_token` 参数中传递你的 HF 令牌来连接到私有空间。你可以在这里获取你的 HF 令牌:https://huggingface.co/settings/tokens
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("abidlabs/my-private-space", hf_token="...")
|
||||
```
|
||||
|
||||
## 复制空间以供私人使用
|
||||
|
||||
虽然你可以将任何公共空间用作 API,但如果你发出太多请求,你可能会受到 Hugging Face 的频率限制。要无限制地使用一个空间,只需将其复制以创建一个私有空间,然后可以根据需要进行多个请求!
|
||||
|
||||
`gradio_client` 包括一个类方法:`Client.duplicate()`,使这个过程变得简单(你需要传递你的[Hugging Face 令牌](https://huggingface.co/settings/tokens)或使用 Hugging Face CLI 登录):
|
||||
|
||||
```python
|
||||
import os
|
||||
from gradio_client import Client
|
||||
|
||||
HF_TOKEN = os.environ.get("HF_TOKEN")
|
||||
|
||||
client = Client.duplicate("abidlabs/whisper", hf_token=HF_TOKEN)
|
||||
client.predict("audio_sample.wav")
|
||||
|
||||
>> "This is a test of the whisper speech recognition model."
|
||||
```
|
||||
|
||||
>> " 这是 Whisper 语音识别模型的测试。"
|
||||
|
||||
如果之前已复制了一个空间,重新运行 `duplicate()` 将*不会*创建一个新的空间。相反,客户端将连接到之前创建的空间。因此,多次运行 `Client.duplicate()` 方法是安全的。
|
||||
|
||||
**注意:** 如果原始空间使用了 GPU,你的私有空间也将使用 GPU,并且你的 Hugging Face 账户将根据 GPU 的价格计费。为了降低费用,在 1 小时没有活动后,你的空间将自动休眠。你还可以使用 `duplicate()` 的 `hardware` 参数来设置硬件。
|
||||
|
||||
## 连接到通用 Gradio 应用程序
|
||||
|
||||
如果你的应用程序运行在其他地方,只需提供完整的 URL,包括 "http://" 或 "https://"。下面是一个在共享 URL 上运行的 Gradio 应用程序进行预测的示例:
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("https://bec81a83-5b5c-471e.gradio.live")
|
||||
```
|
||||
|
||||
## 检查 API 端点
|
||||
|
||||
一旦连接到 Gradio 应用程序,可以通过调用 `Client.view_api()` 方法查看可用的 API 端点。对于 Whisper 空间,我们可以看到以下信息:
|
||||
```bash
|
||||
Client.predict() Usage Info
|
||||
---------------------------
|
||||
Named API endpoints: 1
|
||||
|
||||
- predict(input_audio, api_name="/predict") -> value_0
|
||||
Parameters:
|
||||
- [Audio] input_audio: str (filepath or URL)
|
||||
Returns:
|
||||
- [Textbox] value_0: str (value)
|
||||
```
|
||||
这显示了在此空间中有 1 个 API 端点,并显示了如何使用 API 端点进行预测:我们应该调用 `.predict()` 方法(我们将在下面探讨),提供类型为 `str` 的参数 `input_audio`,它是一个`文件路径或 URL`。
|
||||
|
||||
我们还应该提供 `api_name='/predict'` 参数给 `predict()` 方法。虽然如果一个 Gradio 应用程序只有一个命名的端点,这不是必需的,但它允许我们在单个应用程序中调用不同的端点(如果它们可用)。如果一个应用程序有无名的 API 端点,可以通过运行 `.view_api(all_endpoints=True)` 来显示它们。
|
||||
|
||||
## 进行预测
|
||||
|
||||
进行预测的最简单方法是只需使用相应的参数调用 `.predict()` 函数:
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("abidlabs/en2fr", api_name='/predict')
|
||||
client.predict("Hello")
|
||||
|
||||
>> Bonjour
|
||||
```
|
||||
如果有多个参数,那么你应该将它们作为单独的参数传递给 `.predict()`,就像这样:
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("gradio/calculator")
|
||||
client.predict(4, "add", 5)
|
||||
|
||||
>> 9.0
|
||||
|
||||
|
||||
对于某些输入,例如图像,你应该传递文件的文件路径或URL。同样,对应的输出类型,你将获得一个文件路径或URL。
|
||||
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("abidlabs/whisper")
|
||||
client.predict("https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3")
|
||||
|
||||
>> "My thought I have nobody by a beauty and will as you poured. Mr. Rochester is serve in that so don't find simpus, and devoted abode, to at might in a r—"
|
||||
|
||||
```
|
||||
|
||||
## 异步运行任务(Running jobs asynchronously)
|
||||
|
||||
应注意`.predict()`是一个*阻塞*操作,因为它在返回预测之前等待操作完成。
|
||||
|
||||
|
||||
在许多情况下,直到你需要预测结果之前,你最好让作业在后台运行。你可以通过使用`.submit()`方法创建一个`Job`实例,然后稍后调用`.result()`在作业上获取结果。例如:
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client(space="abidlabs/en2fr")
|
||||
job = client.submit("Hello", api_name="/predict") # 这不是阻塞的
|
||||
|
||||
# 做其他事情
|
||||
|
||||
job.result() # 这是阻塞的
|
||||
|
||||
>> Bonjour
|
||||
```
|
||||
|
||||
## 添加回调 (Adding callbacks)
|
||||
|
||||
或者,可以添加一个或多个回调来在作业完成后执行操作,像这样:
|
||||
|
||||
```python
|
||||
from gradio_client import Client
|
||||
|
||||
def print_result(x):
|
||||
print(" 翻译的结果是:{x}")
|
||||
|
||||
client = Client(space="abidlabs/en2fr")
|
||||
|
||||
job = client.submit("Hello", api_name="/predict", result_callbacks=[print_result])
|
||||
|
||||
# 做其他事情
|
||||
|
||||
>> 翻译的结果是:Bonjour
|
||||
|
||||
```
|
||||
|
||||
## 状态 (Status)
|
||||
|
||||
`Job`对象还允许您通过调用`.status()`方法获取运行作业的状态。这将返回一个`StatusUpdate`对象,具有以下属性:`code`(状态代码,其中之一表示状态的一组定义的字符串。参见`utils.Status`类)、`rank`(此作业在队列中的当前位置)、`queue_size`(总队列大小)、`eta`(此作业将完成的预计时间)、`success`(表示作业是否成功完成的布尔值)和`time`(生成状态的时间)。
|
||||
|
||||
```py
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client(src="gradio/calculator")
|
||||
job = client.submit(5, "add", 4, api_name="/predict")
|
||||
job.status()
|
||||
|
||||
>> <Status.STARTING: 'STARTING'>
|
||||
```
|
||||
|
||||
*注意*:`Job`类还有一个`.done()`实例方法,返回一个布尔值,指示作业是否已完成。
|
||||
|
||||
## 取消作业 (Cancelling Jobs)
|
||||
|
||||
`Job`类还有一个`.cancel()`实例方法,取消已排队但尚未开始的作业。例如,如果你运行:
|
||||
|
||||
```py
|
||||
client = Client("abidlabs/whisper")
|
||||
job1 = client.submit("audio_sample1.wav")
|
||||
job2 = client.submit("audio_sample2.wav")
|
||||
job1.cancel() # 将返回 False,假设作业已开始
|
||||
job2.cancel() # 将返回 True,表示作业已取消
|
||||
```
|
||||
|
||||
如果第一个作业已开始处理,则它将不会被取消。如果第二个作业尚未开始,则它将成功取消并从队列中删除。
|
||||
|
||||
|
||||
|
||||
## 生成器端点 (Generator Endpoints)
|
||||
|
||||
某些Gradio API端点不返回单个值,而是返回一系列值。你可以随时从这样的生成器端点获取返回的一系列值,方法是运行`job.outputs()`:
|
||||
|
||||
```py
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client(src="gradio/count_generator")
|
||||
job = client.submit(3, api_name="/count")
|
||||
while not job.done():
|
||||
time.sleep(0.1)
|
||||
job.outputs()
|
||||
|
||||
>> ['0', '1', '2']
|
||||
```
|
||||
|
||||
请注意,在生成器端点上运行`job.result()`只会获得端点返回的*第一个*值。
|
||||
|
||||
`Job`对象还是可迭代的,这意味着您可以使用它按照从端点返回的结果逐个显示生成器函数的结果。以下是使用`Job`作为生成器的等效示例:
|
||||
|
||||
```py
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client(src="gradio/count_generator")
|
||||
job = client.submit(3, api_name="/count")
|
||||
|
||||
for o in job:
|
||||
print(o)
|
||||
|
||||
>> 0
|
||||
>> 1
|
||||
>> 2
|
||||
```
|
||||
|
||||
你还可以取消具有迭代输出的作业,在这种情况下,作业将在当前迭代完成运行后完成。
|
||||
|
||||
```py
|
||||
from gradio_client import Client
|
||||
import time
|
||||
|
||||
client = Client("abidlabs/test-yield")
|
||||
job = client.submit("abcdef")
|
||||
time.sleep(3)
|
||||
job.cancel() # 作业在运行 2 个迭代后取消
|
||||
```
|
||||
@ -0,0 +1,269 @@
|
||||
# 使用Gradio JavaScript客户端快速入门
|
||||
|
||||
Tags: CLIENT, API, SPACES
|
||||
|
||||
Gradio JavaScript客户端使得使用任何Gradio应用作为API非常简单。例如,考虑一下这个[从麦克风录音的Hugging Face Space,用于转录音频文件](https://huggingface.co/spaces/abidlabs/whisper)。
|
||||
|
||||

|
||||
|
||||
使用`@gradio/client`库,我们可以轻松地以编程方式使用Gradio作为API来转录音频文件。
|
||||
|
||||
以下是完成此操作的完整代码:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const response = await fetch(
|
||||
"https://github.com/audio-samples/audio-samples.github.io/raw/master/samples/wav/ted_speakers/SalmanKhan/sample-1.wav"
|
||||
);
|
||||
const audio_file = await response.blob();
|
||||
|
||||
const app = await client("abidlabs/whisper");
|
||||
const transcription = await app.predict("/predict", [audio_file]);
|
||||
|
||||
console.log(transcription.data);
|
||||
// [ "I said the same phrase 30 times." ]
|
||||
```
|
||||
|
||||
Gradio客户端适用于任何托管的Gradio应用,无论是图像生成器、文本摘要生成器、有状态的聊天机器人、税收计算器还是其他任何应用!Gradio客户端通常与托管在[Hugging Face Spaces](https://hf.space)上的应用一起使用,但您的应用可以托管在任何地方,比如您自己的服务器。
|
||||
|
||||
**先决条件**:要使用Gradio客户端,您不需要深入了解`gradio`库的细节。但是,熟悉Gradio的输入和输出组件的概念会有所帮助。
|
||||
|
||||
## 安装
|
||||
|
||||
可以使用您选择的软件包管理器从npm注册表安装轻量级的`@gradio/client`包,并支持18及以上的Node版本:
|
||||
|
||||
```bash
|
||||
npm i @gradio/client
|
||||
```
|
||||
|
||||
## 连接到正在运行的Gradio应用
|
||||
|
||||
首先,通过实例化`client`对象并将其连接到在Hugging Face Spaces或任何其他位置运行的Gradio应用来建立连接。
|
||||
|
||||
## 连接到Hugging Face Space
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = client("abidlabs/en2fr"); // 一个从英语翻译为法语的 Space
|
||||
```
|
||||
|
||||
您还可以通过在options参数的`hf_token`属性中传入您的HF token来连接到私有Spaces。您可以在此处获取您的HF token:https://huggingface.co/settings/tokens
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = client("abidlabs/my-private-space", { hf_token="hf_..." })
|
||||
```
|
||||
|
||||
## 为私人使用复制一个Space
|
||||
|
||||
虽然您可以将任何公共Space用作API,但是如果您发出的请求过多,Hugging Face可能会对您进行速率限制。为了无限制使用Space,只需复制Space以创建私有Space,然后使用它来进行任意数量的请求!
|
||||
|
||||
`@gradio/client`还导出了另一个函数`duplicate`,以使此过程变得简单(您将需要传入您的[Hugging Face token](https://huggingface.co/settings/tokens))。
|
||||
|
||||
`duplicate`与`client`几乎相同,唯一的区别在于底层实现:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const response = await fetch(
|
||||
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
|
||||
);
|
||||
const audio_file = await response.blob();
|
||||
|
||||
const app = await duplicate("abidlabs/whisper", { hf_token: "hf_..." });
|
||||
const transcription = app.predict("/predict", [audio_file]);
|
||||
```
|
||||
|
||||
如果您之前复制过一个Space,则重新运行`duplicate`不会创建一个新的Space。而是客户端将连接到先前创建的Space。因此,可以安全地多次使用相同的Space重新运行`duplicate`方法。
|
||||
|
||||
**注意:**如果原始Space使用了GPU,您的私有Space也将使用GPU,并且将根据GPU的价格向您的Hugging Face账户计费。为了最大程度地减少费用,在5分钟不活动后,您的Space将自动进入休眠状态。您还可以使用`duplicate`的options对象的`hardware`和`timeout`属性来设置硬件,例如:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await duplicate("abidlabs/whisper", {
|
||||
hf_token: "hf_...",
|
||||
timeout: 60,
|
||||
hardware: "a10g-small",
|
||||
});
|
||||
```
|
||||
|
||||
## 连接到通用的Gradio应用
|
||||
|
||||
如果您的应用程序在其他地方运行,只需提供完整的URL,包括"http://"或"https://"。以下是向运行在共享URL上的Gradio应用进行预测的示例:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = client("https://bec81a83-5b5c-471e.gradio.live");
|
||||
```
|
||||
|
||||
## 检查API端点
|
||||
|
||||
一旦连接到Gradio应用程序,可以通过调用`client`的`view_api`方法来查看可用的API端点。
|
||||
|
||||
对于Whisper Space,我们可以这样做:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await client("abidlabs/whisper");
|
||||
|
||||
const app_info = await app.view_info();
|
||||
|
||||
console.log(app_info);
|
||||
```
|
||||
|
||||
然后我们会看到以下内容:
|
||||
|
||||
```json
|
||||
{
|
||||
"named_endpoints": {
|
||||
"/predict": {
|
||||
"parameters": [
|
||||
{
|
||||
"label": "text",
|
||||
"component": "Textbox",
|
||||
"type": "string"
|
||||
}
|
||||
],
|
||||
"returns": [
|
||||
{
|
||||
"label": "output",
|
||||
"component": "Textbox",
|
||||
"type": "string"
|
||||
}
|
||||
]
|
||||
}
|
||||
},
|
||||
"unnamed_endpoints": {}
|
||||
}
|
||||
```
|
||||
|
||||
这告诉我们该Space中有1个API端点,并显示了如何使用API端点进行预测:我们应该调用`.predict()`方法(下面将进行更多探索),并提供类型为`string`的参数`input_audio`,它是指向文件的URL。
|
||||
|
||||
我们还应该提供`api_name='/predict'`参数给`predict()`方法。虽然如果一个Gradio应用只有1个命名的端点,这不是必需的,但它可以允许我们在单个应用中调用不同的端点。如果应用有未命名的API端点,可以通过运行`.view_api(all_endpoints=True)`来显示它们。
|
||||
|
||||
## 进行预测
|
||||
|
||||
进行预测的最简单方法就是使用适当的参数调用`.predict()`方法:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await client("abidlabs/en2fr");
|
||||
const result = await app.predict("/predict", ["Hello"]);
|
||||
```
|
||||
|
||||
如果有多个参数,您应该将它们作为一个数组传递给`.predict()`,像这样:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await client("gradio/calculator");
|
||||
const result = await app.predict("/predict", [4, "add", 5]);
|
||||
```
|
||||
|
||||
对于某些输入,例如图像,您应该根据所需要的方便程度传入`Buffer`、`Blob`或`File`。在Node.js中,可以使用`Buffer`或`Blob`;在浏览器环境中,可以使用`Blob`或`File`。
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const response = await fetch(
|
||||
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
|
||||
);
|
||||
const audio_file = await response.blob();
|
||||
|
||||
const app = await client("abidlabs/whisper");
|
||||
const result = await client.predict("/predict", [audio_file]);
|
||||
```
|
||||
|
||||
## 使用事件
|
||||
|
||||
如果您使用的API可以随时间返回结果,或者您希望访问有关作业状态的信息,您可以使用事件接口获取更大的灵活性。这对于迭代的或生成器的端点特别有用,因为它们会生成一系列离散的响应值。
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
function log_result(payload) {
|
||||
const {
|
||||
data: [translation],
|
||||
} = payload;
|
||||
|
||||
console.log(`翻译结果为:${translation}`);
|
||||
}
|
||||
|
||||
const app = await client("abidlabs/en2fr");
|
||||
const job = app.submit("/predict", ["Hello"]);
|
||||
|
||||
job.on("data", log_result);
|
||||
```
|
||||
|
||||
## 状态
|
||||
|
||||
事件接口还可以通过监听`"status"`事件来获取运行作业的状态。这将返回一个对象,其中包含以下属性:`status`(当前作业的人类可读状态,`"pending" | "generating" | "complete" | "error"`),`code`(作业的详细gradio code),`position`(此作业在队列中的当前位置),`queue_size`(总队列大小),`eta`(作业完成的预计时间),`success`(表示作业是否成功完成的布尔值)和`time`(作业状态生成的时间,是一个`Date`对象)。
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
function log_status(status) {
|
||||
console.log(
|
||||
`此作业的当前状态为:${JSON.stringify(status, null, 2)}`
|
||||
);
|
||||
}
|
||||
|
||||
const app = await client("abidlabs/en2fr");
|
||||
const job = app.submit("/predict", ["Hello"]);
|
||||
|
||||
job.on("status", log_status);
|
||||
```
|
||||
|
||||
## 取消作业
|
||||
|
||||
作业实例还具有`.cancel()`方法,用于取消已排队但尚未启动的作业。例如,如果您运行以下命令:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await client("abidlabs/en2fr");
|
||||
const job_one = app.submit("/predict", ["Hello"]);
|
||||
const job_two = app.submit("/predict", ["Friends"]);
|
||||
|
||||
job_one.cancel();
|
||||
job_two.cancel();
|
||||
```
|
||||
|
||||
如果第一个作业已经开始处理,那么它将不会被取消,但客户端将不再监听更新(丢弃该作业)。如果第二个作业尚未启动,它将被成功取消并从队列中移除。
|
||||
|
||||
## 生成器端点
|
||||
|
||||
某些Gradio API端点不返回单个值,而是返回一系列值。您可以使用事件接口实时侦听这些值:
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await client("gradio/count_generator");
|
||||
const job = app.submit(0, [9]);
|
||||
|
||||
job.on("data", (data) => console.log(data));
|
||||
```
|
||||
|
||||
这将按生成端点生成的值进行日志记录。
|
||||
|
||||
您还可以取消具有迭代输出的作业,在这种情况下,作业将立即完成。
|
||||
|
||||
```js
|
||||
import { client } from "@gradio/client";
|
||||
|
||||
const app = await client("gradio/count_generator");
|
||||
const job = app.submit(0, [9]);
|
||||
|
||||
job.on("data", (data) => console.log(data));
|
||||
|
||||
setTimeout(() => {
|
||||
job.cancel();
|
||||
}, 3000);
|
||||
```
|
||||
@ -0,0 +1,266 @@
|
||||
# 使用Gradio Python客户端构建FastAPI应用
|
||||
|
||||
Tags: CLIENT, API, WEB APP
|
||||
|
||||
在本博客文章中,我们将演示如何使用 `gradio_client` [Python库](getting-started-with-the-python-client/) 来以编程方式创建Gradio应用的请求,通过创建一个示例FastAPI Web应用。我们将构建的 Web 应用名为“Acappellify”,它允许用户上传视频文件作为输入,并返回一个没有伴奏音乐的视频版本。它还会显示生成的视频库。
|
||||
|
||||
|
||||
**先决条件**
|
||||
|
||||
在开始之前,请确保您正在运行Python 3.9或更高版本,并已安装以下库:
|
||||
|
||||
* `gradio_client`
|
||||
* `fastapi`
|
||||
* `uvicorn`
|
||||
|
||||
您可以使用`pip`安装这些库:
|
||||
|
||||
```bash
|
||||
$ pip install gradio_client fastapi uvicorn
|
||||
```
|
||||
|
||||
您还需要安装ffmpeg。您可以通过在终端中运行以下命令来检查您是否已安装ffmpeg:
|
||||
|
||||
```bash
|
||||
$ ffmpeg version
|
||||
```
|
||||
|
||||
否则,通过按照这些说明安装ffmpeg [链接](https://www.hostinger.com/tutorials/how-to-install-ffmpeg)。
|
||||
|
||||
## 步骤1:编写视频处理函数
|
||||
|
||||
让我们从似乎最复杂的部分开始--使用机器学习从视频中去除音乐。
|
||||
|
||||
幸运的是,我们有一个现有的Space可以简化这个过程:[https://huggingface.co/spaces/abidlabs/music-separation](https://huggingface.co/spaces/abidlabs/music-separation)。该空间接受一个音频文件,并生成两个独立的音频文件:一个带有伴奏音乐,一个带有原始剪辑中的其他所有声音。非常适合我们的客户端使用!
|
||||
|
||||
打开一个新的Python文件,比如`main.py`,并通过从`gradio_client`导入 `Client` 类,并将其连接到该Space:
|
||||
|
||||
```py
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client("abidlabs/music-separation")
|
||||
|
||||
def acapellify(audio_path):
|
||||
result = client.predict(audio_path, api_name="/predict")
|
||||
return result[0]
|
||||
```
|
||||
|
||||
所需的代码仅如上所示--请注意,API端点返回一个包含两个音频文件(一个没有音乐,一个只有音乐)的列表,因此我们只返回列表的第一个元素。
|
||||
|
||||
---
|
||||
|
||||
**注意**:由于这是一个公共Space,可能会有其他用户同时使用该Space,这可能导致速度较慢。您可以使用自己的[Hugging Face token](https://huggingface.co/settings/tokens)复制此Space,创建一个只有您自己访问权限的私有Space,并绕过排队。要做到这一点,只需用下面的代码替换上面的前两行:
|
||||
|
||||
```py
|
||||
from gradio_client import Client
|
||||
|
||||
client = Client.duplicate("abidlabs/music-separation", hf_token=YOUR_HF_TOKEN)
|
||||
```
|
||||
|
||||
其他的代码保持不变!
|
||||
|
||||
---
|
||||
|
||||
现在,当然,我们正在处理视频文件,所以我们首先需要从视频文件中提取音频。为此,我们将使用`ffmpeg`库,它在处理音频和视频文件时做了很多艰巨的工作。使用`ffmpeg`的最常见方法是通过命令行,在Python的`subprocess`模块中调用它:
|
||||
|
||||
我们的视频处理工作流包含三个步骤:
|
||||
|
||||
1. 首先,我们从视频文件路径开始,并使用`ffmpeg`提取音频。
|
||||
2. 然后,我们通过上面的`acapellify()`函数传入音频文件。
|
||||
3. 最后,我们将新音频与原始视频合并,生成最终的Acapellify视频。
|
||||
|
||||
以下是Python中的完整代码,您可以将其添加到`main.py`文件中:
|
||||
|
||||
```python
|
||||
import subprocess
|
||||
|
||||
def process_video(video_path):
|
||||
old_audio = os.path.basename(video_path).split(".")[0] + ".m4a"
|
||||
subprocess.run(['ffmpeg', '-y', '-i', video_path, '-vn', '-acodec', 'copy', old_audio])
|
||||
|
||||
new_audio = acapellify(old_audio)
|
||||
|
||||
new_video = f"acap_{video_path}"
|
||||
subprocess.call(['ffmpeg', '-y', '-i', video_path, '-i', new_audio, '-map', '0:v', '-map', '1:a', '-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental', f"static/{new_video}"])
|
||||
return new_video
|
||||
```
|
||||
|
||||
如果您想了解所有命令行参数的详细信息,请阅读[ffmpeg文档](https://ffmpeg.org/ffmpeg.html),因为它们超出了本教程的范围。
|
||||
|
||||
## 步骤2: 创建一个FastAPI应用(后端路由)
|
||||
|
||||
接下来,我们将创建一个简单的FastAPI应用程序。如果您以前没有使用过FastAPI,请查看[优秀的FastAPI文档](https://fastapi.tiangolo.com/)。否则,下面的基本模板将看起来很熟悉,我们将其添加到`main.py`中:
|
||||
|
||||
```python
|
||||
import os
|
||||
from fastapi import FastAPI, File, UploadFile, Request
|
||||
from fastapi.responses import HTMLResponse, RedirectResponse
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
from fastapi.templating import Jinja2Templates
|
||||
|
||||
app = FastAPI()
|
||||
os.makedirs("static", exist_ok=True)
|
||||
app.mount("/static", StaticFiles(directory="static"), name="static")
|
||||
templates = Jinja2Templates(directory="templates")
|
||||
|
||||
videos = []
|
||||
|
||||
@app.get("/", response_class=HTMLResponse)
|
||||
async def home(request: Request):
|
||||
return templates.TemplateResponse(
|
||||
"home.html", {"request": request, "videos": videos})
|
||||
|
||||
@app.post("/uploadvideo/")
|
||||
async def upload_video(video: UploadFile = File(...)):
|
||||
new_video = process_video(video.filename)
|
||||
videos.append(new_video)
|
||||
return RedirectResponse(url='/', status_code=303)
|
||||
```
|
||||
|
||||
在这个示例中,FastAPI应用程序有两个路由:`/` 和 `/uploadvideo/`。
|
||||
|
||||
`/` 路由返回一个显示所有上传视频的画廊的HTML模板。
|
||||
|
||||
`/uploadvideo/` 路由接受一个带有`UploadFile`对象的 `POST` 请求,表示上传的视频文件。视频文件通过`process_video()`方法进行 "acapellify",并将输出视频存储在一个列表中,该列表在内存中存储了所有上传的视频。
|
||||
|
||||
请注意,这只是一个非常基本的示例,如果这是一个发布应用程序,则需要添加更多逻辑来处理文件存储、用户身份验证和安全性考虑等。
|
||||
|
||||
## 步骤3:创建一个FastAPI应用(前端模板)
|
||||
|
||||
最后,我们创建Web应用的前端。首先,在与`main.py`相同的目录下创建一个名为`templates`的文件夹。然后,在`templates`文件夹中创建一个名为`home.html`的模板。下面是最终的文件结构:
|
||||
|
||||
```csv
|
||||
├── main.py
|
||||
├── templates
|
||||
│ └── home.html
|
||||
```
|
||||
|
||||
将以下内容写入`home.html`文件中:
|
||||
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title> 视频库 </title>
|
||||
<style>
|
||||
body {
|
||||
font-family: sans-serif;
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
background-color: #f5f5f5;
|
||||
}
|
||||
h1 {
|
||||
text-align: center;
|
||||
margin-top: 30px;
|
||||
margin-bottom: 20px;
|
||||
}
|
||||
.gallery {
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
justify-content: center;
|
||||
gap: 20px;
|
||||
padding: 20px;
|
||||
}
|
||||
.video {
|
||||
border: 2px solid #ccc;
|
||||
box-shadow: 0px 0px 10px rgba(0, 0, 0, 0.2);
|
||||
border-radius: 5px;
|
||||
overflow: hidden;
|
||||
width: 300px;
|
||||
margin-bottom: 20px;
|
||||
}
|
||||
.video video {
|
||||
width: 100%;
|
||||
height: 200px;
|
||||
}
|
||||
.video p {
|
||||
text-align: center;
|
||||
margin: 10px 0;
|
||||
}
|
||||
form {
|
||||
margin-top: 20px;
|
||||
text-align: center;
|
||||
}
|
||||
input[type="file"] {
|
||||
display: none;
|
||||
}
|
||||
.upload-btn {
|
||||
display: inline-block;
|
||||
background-color: #3498db;
|
||||
color: #fff;
|
||||
padding: 10px 20px;
|
||||
font-size: 16px;
|
||||
border: none;
|
||||
border-radius: 5px;
|
||||
cursor: pointer;
|
||||
}
|
||||
.upload-btn:hover {
|
||||
background-color: #2980b9;
|
||||
}
|
||||
.file-name {
|
||||
margin-left: 10px;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<h1> 视频库 </h1>
|
||||
{% if videos %}
|
||||
<div class="gallery">
|
||||
{% for video in videos %}
|
||||
<div class="video">
|
||||
<video controls>
|
||||
<source src="{{ url_for('static', path=video) }}" type="video/mp4">
|
||||
您的浏览器不支持视频标签。
|
||||
</video>
|
||||
<p>{{ video }}</p>
|
||||
</div>
|
||||
{% endfor %}
|
||||
</div>
|
||||
{% else %}
|
||||
<p> 尚未上传任何视频。</p>
|
||||
{% endif %}
|
||||
<form action="/uploadvideo/" method="post" enctype="multipart/form-data">
|
||||
<label for="video-upload" class="upload-btn"> 选择视频文件 </label>
|
||||
<input type="file" name="video" id="video-upload">
|
||||
<span class="file-name"></span>
|
||||
<button type="submit" class="upload-btn"> 上传 </button>
|
||||
</form>
|
||||
<script>
|
||||
// 在表单中显示所选文件名
|
||||
const fileUpload = document.getElementById("video-upload");
|
||||
const fileName = document.querySelector(".file-name");
|
||||
|
||||
fileUpload.addEventListener("change", (e) => {
|
||||
fileName.textContent = e.target.files[0].name;
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
## 第4步:运行 FastAPI 应用
|
||||
|
||||
最后,我们准备好运行由 Gradio Python 客户端提供支持的 FastAPI 应用程序。
|
||||
|
||||
打开终端并导航到包含 `main.py` 文件的目录,然后在终端中运行以下命令:
|
||||
|
||||
```bash
|
||||
$ uvicorn main:app
|
||||
```
|
||||
|
||||
您应该会看到如下输出:
|
||||
|
||||
```csv
|
||||
Loaded as API: https://abidlabs-music-separation.hf.space ✔
|
||||
INFO: Started server process [1360]
|
||||
INFO: Waiting for application startup.
|
||||
INFO: Application startup complete.
|
||||
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
就是这样!开始上传视频,您将在响应中得到一些“acapellified”视频(处理时间根据您的视频长度可能需要几秒钟到几分钟)。以下是上传两个视频后 UI 的外观:
|
||||
|
||||
|
||||
|
||||
如果您想了解如何在项目中使用 Gradio Python 客户端的更多信息,请[阅读专门的指南](/getting-started-with-the-python-client/)。
|
||||
|
||||
130
guides/cn/06_client-libraries/gradio-and-llm-agents.md
Normal file
@ -0,0 +1,130 @@
|
||||
# Gradio & LLM Agents 🤝
|
||||
|
||||
非常强大的大型语言模型(LLM),如果我们能赋予它们完成专门任务的技能,它们将变得更加强大。
|
||||
|
||||
[gradio_tools](https://github.com/freddyaboulton/gradio-tools)库可以将任何[Gradio](https://github.com/gradio-app/gradio)应用程序转化为[工具](https://python.langchain.com/en/latest/modules/agents/tools.html),供[代理](https://docs.langchain.com/docs/components/agents/agent)使用以完成任务。例如,一个LLM可以使用Gradio工具转录在网上找到的语音记录,然后为您summarize它。或者它可以使用不同的Gradio工具对您的Google Drive上的文档应用OCR,然后回答相关问题。
|
||||
|
||||
本指南将展示如何使用`gradio_tools`让您的LLM代理访问全球托管的最先进的Gradio应用程序。尽管`gradio_tools`与不止一个代理框架兼容,但本指南将重点介绍[Langchain代理](https://docs.langchain.com/docs/components/agents/)。
|
||||
|
||||
## 一些背景信息
|
||||
|
||||
### 代理是什么?
|
||||
|
||||
[LangChain代理](https://docs.langchain.com/docs/components/agents/agent)是一个大型语言模型(LLM),它根据使用其众多工具之一的输入来生成输出。
|
||||
|
||||
### Gradio是什么?
|
||||
[Gradio](https://github.com/gradio-app/gradio)是用于构建机器学习Web应用程序并与全球共享的事实上的标准框架-完全由Python驱动!🐍
|
||||
|
||||
## gradio_tools - 一个端到端的示例
|
||||
|
||||
要开始使用`gradio_tools`,您只需要导入和初始化工具,然后将其传递给langchain代理!
|
||||
|
||||
在下面的示例中,我们导入`StableDiffusionPromptGeneratorTool`以创建一个良好的稳定扩散提示,
|
||||
`StableDiffusionTool`以使用我们改进的提示创建一张图片,`ImageCaptioningTool`以为生成的图片加上标题,以及
|
||||
`TextToVideoTool`以根据提示创建一个视频。
|
||||
|
||||
然后,我们告诉我们的代理创建一张狗正在滑板的图片,但在使用图像生成器之前请先改进我们的提示。我们还要求
|
||||
它为生成的图片添加标题并创建一个视频。代理可以根据需要决定使用哪个工具,而不需要我们明确告知。
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
if not os.getenv("OPENAI_API_KEY"):
|
||||
raise ValueError("OPENAI_API_KEY 必须设置 ")
|
||||
|
||||
from langchain.agents import initialize_agent
|
||||
from langchain.llms import OpenAI
|
||||
from gradio_tools import (StableDiffusionTool, ImageCaptioningTool, StableDiffusionPromptGeneratorTool,
|
||||
TextToVideoTool)
|
||||
|
||||
from langchain.memory import ConversationBufferMemory
|
||||
|
||||
llm = OpenAI(temperature=0)
|
||||
memory = ConversationBufferMemory(memory_key="chat_history")
|
||||
tools = [StableDiffusionTool().langchain, ImageCaptioningTool().langchain,
|
||||
StableDiffusionPromptGeneratorTool().langchain, TextToVideoTool().langchain]
|
||||
|
||||
agent = initialize_agent(tools, llm, memory=memory, agent="conversational-react-description", verbose=True)
|
||||
output = agent.run(input=("Please create a photo of a dog riding a skateboard "
|
||||
"but improve my prompt prior to using an image generator."
|
||||
"Please caption the generated image and create a video for it using the improved prompt."))
|
||||
```
|
||||
|
||||
您会注意到我们正在使用一些与`gradio_tools`一起提供的预构建工具。请参阅此[文档](https://github.com/freddyaboulton/gradio-tools#gradio-tools-gradio--llm-agents)以获取完整的`gradio_tools`工具列表。
|
||||
如果您想使用当前不在`gradio_tools`中的工具,很容易添加您自己的工具。下一节将介绍如何添加自己的工具。
|
||||
|
||||
## gradio_tools - 创建自己的工具
|
||||
|
||||
核心抽象是`GradioTool`,它允许您为LLM定义一个新的工具,只要您实现标准接口:
|
||||
|
||||
```python
|
||||
class GradioTool(BaseTool):
|
||||
|
||||
def __init__(self, name: str, description: str, src: str) -> None:
|
||||
|
||||
@abstractmethod
|
||||
def create_job(self, query: str) -> Job:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def postprocess(self, output: Tuple[Any] | Any) -> str:
|
||||
pass
|
||||
```
|
||||
需要满足的要求是:
|
||||
1. 工具的名称
|
||||
2. 工具的描述。这非常关键!代理根据其描述决定使用哪个工具。请确切描述输入和输出应该是什么样的,最好包括示例。
|
||||
3. Gradio应用程序的url或space id,例如`freddyaboulton/calculator`。基于该值,`gradio_tool`将通过API创建一个[gradio客户端](https://github.com/gradio-app/gradio/blob/main/client/python/README.md)实例来查询上游应用程序。如果您不熟悉gradio客户端库,请确保点击链接了解更多信息。
|
||||
4. create_job - 给定一个字符串,该方法应该解析该字符串并从客户端返回一个job。大多数情况下,这只需将字符串传递给客户端的`submit`函数即可。有关创建job的更多信息,请参阅[这里](https://github.com/gradio-app/gradio/blob/main/client/python/README.md#making-a-prediction)
|
||||
5. postprocess - 给定作业的结果,将其转换为LLM可以向用户显示的字符串。
|
||||
6. *Optional可选* - 某些库,例如[MiniChain](https://github.com/srush/MiniChain/tree/main),可能需要一些关于工具使用的底层gradio输入和输出类型的信息。默认情况下,这将返回gr.Textbox(),但如果您想提供更准确的信息,请实现工具的`_block_input(self, gr)`和`_block_output(self, gr)`方法。`gr`变量是gradio模块(通过`import gradio as gr`获得的结果)。`GradiTool`父类将自动引入`gr`并将其传递给`_block_input`和`_block_output`方法。
|
||||
|
||||
就是这样!
|
||||
|
||||
一旦您创建了自己的工具,请在`gradio_tools`存储库上发起拉取请求!我们欢迎所有贡献。
|
||||
|
||||
## 示例工具 - 稳定扩散
|
||||
|
||||
以下是作为示例的稳定扩散工具代码:
|
||||
|
||||
from gradio_tool import GradioTool
|
||||
import os
|
||||
|
||||
class StableDiffusionTool(GradioTool):
|
||||
"""Tool for calling stable diffusion from llm"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
name="StableDiffusion",
|
||||
description=(
|
||||
"An image generator. Use this to generate images based on "
|
||||
"text input. Input should be a description of what the image should "
|
||||
"look like. The output will be a path to an image file."
|
||||
),
|
||||
src="gradio-client-demos/stable-diffusion",
|
||||
hf_token=None,
|
||||
) -> None:
|
||||
super().__init__(name, description, src, hf_token)
|
||||
|
||||
def create_job(self, query: str) -> Job:
|
||||
return self.client.submit(query, "", 9, fn_index=1)
|
||||
|
||||
def postprocess(self, output: str) -> str:
|
||||
return [os.path.join(output, i) for i in os.listdir(output) if not i.endswith("json")][0]
|
||||
|
||||
def _block_input(self, gr) -> "gr.components.Component":
|
||||
return gr.Textbox()
|
||||
|
||||
def _block_output(self, gr) -> "gr.components.Component":
|
||||
return gr.Image()
|
||||
```
|
||||
关于此实现的一些注意事项:
|
||||
1. 所有的 `GradioTool` 实例都有一个名为 `client` 的属性,它指向底层的 [gradio 客户端](https://github.com/gradio-app/gradio/tree/main/client/python#gradio_client-use-a-gradio-app-as-an-api----in-3-lines-of-python),这就是您在 `create_job` 方法中应该使用的内容。
|
||||
|
||||
2. `create_job` 方法只是将查询字符串传递给客户端的 `submit` 函数,并硬编码了一些其他参数,即负面提示字符串和指南缩放。我们可以在后续版本中修改我们的工具,以便从输入字符串中接受这些值。
|
||||
|
||||
3. `postprocess` 方法只是返回由稳定扩散空间创建的图库中的第一个图像。我们使用 `os` 模块获取图像的完整路径。
|
||||
|
||||
## Conclusion
|
||||
|
||||
现在,您已经知道如何通过数千个运行在野外的 gradio 空间来扩展您的 LLM 的能力了!
|
||||
同样,我们欢迎对 [gradio_tools](https://github.com/freddyaboulton/gradio-tools) 库的任何贡献。我们很兴奋看到大家构建的工具!
|
||||
108
guides/cn/07_other-tutorials/building-a-pictionary-app.md
Normal file
@ -0,0 +1,108 @@
|
||||
# 构建一个 Pictionary 应用程序
|
||||
|
||||
相关空间:https://huggingface.co/spaces/nateraw/quickdraw
|
||||
标签:SKETCHPAD,LABELS,LIVE
|
||||
|
||||
## 简介
|
||||
|
||||
一个算法能够有多好地猜出你在画什么?几年前,Google 发布了 **Quick Draw** 数据集,其中包含人类绘制的各种物体的图画。研究人员使用这个数据集训练模型来猜测 Pictionary 风格的图画。
|
||||
|
||||
这样的模型非常适合与 Gradio 的 *sketchpad* 输入一起使用,因此在本教程中,我们将使用 Gradio 构建一个 Pictionary 网络应用程序。我们将能够完全使用 Python 构建整个网络应用程序,并且将如下所示(尝试画点什么!):
|
||||
|
||||
<iframe src="https://abidlabs-draw2.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
让我们开始吧!本指南介绍了如何构建一个 pictionary 应用程序(逐步):
|
||||
|
||||
1. [设置 Sketch Recognition 模型](#1-set-up-the-sketch-recognition-model)
|
||||
2. [定义 `predict` 函数](#2-define-a-predict-function)
|
||||
3. [创建 Gradio 界面](#3-create-a-gradio-interface)
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 包。要使用预训练的草图模型,还需要安装 `torch`。
|
||||
|
||||
## 1. 设置 Sketch Recognition 模型
|
||||
|
||||
首先,您将需要一个草图识别模型。由于许多研究人员已经在 Quick Draw 数据集上训练了自己的模型,在本教程中,我们将使用一个预训练模型。我们的模型是一个由 Nate Raw 训练的轻量级 1.5MB 模型,您可以在此处[下载](https://huggingface.co/spaces/nateraw/quickdraw/blob/main/pytorch_model.bin)。
|
||||
|
||||
如果您感兴趣,这是用于训练模型的[代码](https://github.com/nateraw/quickdraw-pytorch)。我们将简单地使用 PyTorch 加载预训练的模型,如下所示:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
model = nn.Sequential(
|
||||
nn.Conv2d(1, 32, 3, padding='same'),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(2),
|
||||
nn.Conv2d(32, 64, 3, padding='same'),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(2),
|
||||
nn.Conv2d(64, 128, 3, padding='same'),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(2),
|
||||
nn.Flatten(),
|
||||
nn.Linear(1152, 256),
|
||||
nn.ReLU(),
|
||||
nn.Linear(256, len(LABELS)),
|
||||
)
|
||||
state_dict = torch.load('pytorch_model.bin', map_location='cpu')
|
||||
model.load_state_dict(state_dict, strict=False)
|
||||
model.eval()
|
||||
```
|
||||
|
||||
## 2. 定义 `predict` 函数
|
||||
|
||||
接下来,您需要定义一个函数,该函数接受*用户输入*(在本例中是一个涂鸦图像)并返回预测结果。预测结果应该作为一个字典返回,其中键是类名,值是置信度概率。我们将从这个[文本文件](https://huggingface.co/spaces/nateraw/quickdraw/blob/main/class_names.txt)加载类名。
|
||||
|
||||
对于我们的预训练模型,代码如下所示:
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
||||
LABELS = Path('class_names.txt').read_text().splitlines()
|
||||
|
||||
def predict(img):
|
||||
x = torch.tensor(img, dtype=torch.float32).unsqueeze(0).unsqueeze(0) / 255.
|
||||
with torch.no_grad():
|
||||
out = model(x)
|
||||
probabilities = torch.nn.functional.softmax(out[0], dim=0)
|
||||
values, indices = torch.topk(probabilities, 5)
|
||||
confidences = {LABELS[i]: v.item() for i, v in zip(indices, values)}
|
||||
return confidences
|
||||
```
|
||||
|
||||
让我们分解一下。该函数接受一个参数:
|
||||
|
||||
* `img`:输入图像,作为一个 `numpy` 数组
|
||||
|
||||
然后,函数将图像转换为 PyTorch 的 `tensor`,将其通过模型,并返回:
|
||||
|
||||
* `confidences`:前五个预测的字典,其中键是类别标签,值是置信度概率
|
||||
|
||||
## 3. 创建一个 Gradio 界面
|
||||
|
||||
现在我们已经设置好预测函数,我们可以在其周围创建一个 Gradio 界面。
|
||||
|
||||
在本例中,输入组件是一个 `sketchpad`,使用方便的字符串快捷方式 `"sketchpad"` 创建一个用户可以在其上绘制的画布,并处理将其转换为 numpy 数组的预处理。
|
||||
|
||||
输出组件将是一个 `"label"`,以良好的形式显示前几个标签。
|
||||
|
||||
最后,我们将添加一个额外的参数,设置 `live=True`,允许我们的界面实时运行,每当用户在涂鸦板上绘制时,就会调整其预测结果。Gradio 的代码如下所示:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.Interface(fn=predict,
|
||||
inputs="sketchpad",
|
||||
outputs="label",
|
||||
live=True).launch()
|
||||
```
|
||||
|
||||
这将产生以下界面,您可以在浏览器中尝试(尝试画一些东西,比如 "snake" 或 "laptop"):
|
||||
|
||||
<iframe src="https://abidlabs-draw2.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
----------
|
||||
|
||||
完成!这就是构建一个 Pictionary 风格的猜词游戏所需的所有代码。玩得开心,并尝试找到一些边缘情况🧐
|
||||
@ -0,0 +1,225 @@
|
||||
# 使用 GAN 创建您自己的朋友
|
||||
|
||||
spaces/NimaBoscarino/cryptopunks, https://huggingface.co/spaces/nateraw/cryptopunks-generator
|
||||
Tags: GAN, IMAGE, HUB
|
||||
|
||||
由 <a href="https://huggingface.co/NimaBoscarino">Nima Boscarino</a> 和 <a href="https://huggingface.co/nateraw">Nate Raw</a> 贡献
|
||||
|
||||
## 简介
|
||||
|
||||
最近,加密货币、NFTs 和 Web3 运动似乎都非常流行!数字资产以惊人的金额在市场上上市,几乎每个名人都推出了自己的 NFT 收藏。虽然您的加密资产可能是应税的,例如在加拿大(https://www.canada.ca/en/revenue-agency/programs/about-canada-revenue-agency-cra/compliance/digital-currency/cryptocurrency-guide.html),但今天我们将探索一些有趣且无税的方法来生成自己的一系列过程生成的 CryptoPunks(https://www.larvalabs.com/cryptopunks)。
|
||||
|
||||
生成对抗网络(GANs),通常称为 GANs,是一类特定的深度学习模型,旨在通过学习输入数据集来创建(生成!)与原始训练集中的元素具有令人信服的相似性的新材料。众所周知,网站[thispersondoesnotexist.com](https://thispersondoesnotexist.com/)通过名为 StyleGAN2 的模型生成了栩栩如生但是合成的人物图像而迅速走红。GANs 在机器学习领域获得了人们的关注,现在被用于生成各种图像、文本甚至音乐!
|
||||
|
||||
今天我们将简要介绍 GAN 的高级直觉,然后我们将围绕一个预训练的 GAN 构建一个小型演示,看看这一切都是怎么回事。下面是我们将要组合的东西的一瞥:
|
||||
|
||||
<iframe src="https://nimaboscarino-cryptopunks.hf.space" frameBorder="0" height="855" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保已经[安装](/getting_started)了 `gradio` Python 包。要使用预训练模型,请还安装 `torch` 和 `torchvision`。
|
||||
|
||||
## GANs:简介
|
||||
|
||||
最初在[Goodfellow 等人 2014 年的论文](https://arxiv.org/abs/1406.2661)中提出,GANs 由互相竞争的神经网络组成,旨在相互智能地欺骗对方。一种网络,称为“生成器”,负责生成图像。另一个网络,称为“鉴别器”,从生成器一次接收一张图像,以及来自训练数据集的 **real 真实**图像。然后,鉴别器必须猜测:哪张图像是假的?
|
||||
|
||||
生成器不断训练以创建对鉴别器更难以识别的图像,而鉴别器每次正确检测到伪造图像时,都会为生成器设置更高的门槛。随着网络之间的这种竞争(**adversarial 对抗性!**),生成的图像改善到了对人眼来说无法区分的地步!
|
||||
|
||||
如果您想更深入地了解 GANs,可以参考[Analytics Vidhya 上的这篇优秀文章](https://www.analyticsvidhya.com/blog/2021/06/a-detailed-explanation-of-gan-with-implementation-using-tensorflow-and-keras/)或这个[PyTorch 教程](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html)。不过,现在我们将深入看一下演示!
|
||||
|
||||
## 步骤 1 - 创建生成器模型
|
||||
|
||||
要使用 GAN 生成新图像,只需要生成器模型。生成器可以使用许多不同的架构,但是对于这个演示,我们将使用一个预训练的 GAN 生成器模型,其架构如下:
|
||||
|
||||
```python
|
||||
from torch import nn
|
||||
|
||||
class Generator(nn.Module):
|
||||
# 有关nc,nz和ngf的解释,请参见下面的链接
|
||||
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
|
||||
def __init__(self, nc=4, nz=100, ngf=64):
|
||||
super(Generator, self).__init__()
|
||||
self.network = nn.Sequential(
|
||||
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
|
||||
nn.BatchNorm2d(ngf * 4),
|
||||
nn.ReLU(True),
|
||||
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
|
||||
nn.BatchNorm2d(ngf * 2),
|
||||
nn.ReLU(True),
|
||||
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
|
||||
nn.BatchNorm2d(ngf),
|
||||
nn.ReLU(True),
|
||||
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
|
||||
nn.Tanh(),
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
output = self.network(input)
|
||||
return output
|
||||
```
|
||||
|
||||
我们正在使用来自[此 repo 的 @teddykoker](https://github.com/teddykoker/cryptopunks-gan/blob/main/train.py#L90)的生成器模型,您还可以在那里看到原始的鉴别器模型结构。
|
||||
|
||||
在实例化模型之后,我们将加载来自 Hugging Face Hub 的权重,存储在[nateraw/cryptopunks-gan](https://huggingface.co/nateraw/cryptopunks-gan)中:
|
||||
|
||||
```python
|
||||
from huggingface_hub import hf_hub_download
|
||||
import torch
|
||||
|
||||
model = Generator()
|
||||
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
|
||||
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # 如果有可用的GPU,请使用'cuda'
|
||||
```
|
||||
|
||||
## 步骤 2 - 定义“predict”函数
|
||||
|
||||
`predict` 函数是使 Gradio 工作的关键!我们通过 Gradio 界面选择的任何输入都将通过我们的 `predict` 函数传递,该函数应对输入进行操作并生成我们可以通过 Gradio 输出组件显示的输出。对于 GANs,常见的做法是将随机噪声传入我们的模型作为输入,因此我们将生成一张随机数的张量并将其传递给模型。然后,我们可以使用 `torchvision` 的 `save_image` 函数将模型的输出保存为 `png` 文件,并返回文件名:
|
||||
|
||||
```python
|
||||
from torchvision.utils import save_image
|
||||
|
||||
def predict(seed):
|
||||
num_punks = 4
|
||||
torch.manual_seed(seed)
|
||||
z = torch.randn(num_punks, 100, 1, 1)
|
||||
punks = model(z)
|
||||
save_image(punks, "punks.png", normalize=True)
|
||||
return 'punks.png'
|
||||
```
|
||||
|
||||
我们给 `predict` 函数一个 `seed` 参数,这样我们就可以使用一个种子固定随机张量生成。然后,我们可以通过传入相同的种子再次查看生成的 punks。
|
||||
|
||||
*注意!* 我们的模型需要一个 100x1x1 的输入张量进行单次推理,或者 (BatchSize)x100x1x1 来生成一批图像。在这个演示中,我们每次生成 4 个 punk。
|
||||
|
||||
## 第三步—创建一个 Gradio 接口
|
||||
|
||||
此时,您甚至可以运行您拥有的代码 `predict(<SOME_NUMBER>)`,并在您的文件系统中找到新生成的 punk 在 `./punks.png`。然而,为了制作一个真正的交互演示,我们将用 Gradio 构建一个简单的界面。我们的目标是:
|
||||
|
||||
* 设置一个滑块输入,以便用户可以选择“seed”值
|
||||
* 使用图像组件作为输出,展示生成的 punk
|
||||
* 使用我们的 `predict()` 函数来接受种子并生成图像
|
||||
|
||||
通过使用 `gr.Interface()`,我们可以使用一个函数调用来定义所有这些 :
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.Interface(
|
||||
predict,
|
||||
inputs=[
|
||||
gr.Slider(0, 1000, label='Seed', default=42),
|
||||
],
|
||||
outputs="image",
|
||||
).launch()
|
||||
```
|
||||
|
||||
启动界面后,您应该会看到像这样的东西 :
|
||||
|
||||
<iframe src="https://nimaboscarino-cryptopunks-1.hf.space" frameBorder="0" height="365" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
## 第四步—更多 punk!
|
||||
|
||||
每次生成 4 个 punk 是一个好的开始,但是也许我们想控制每次想生成多少。通过简单地向我们传递给 `gr.Interface` 的 `inputs` 列表添加另一项即可向我们的 Gradio 界面添加更多输入 :
|
||||
|
||||
```python
|
||||
gr.Interface(
|
||||
predict,
|
||||
inputs=[
|
||||
gr.Slider(0, 1000, label='Seed', default=42),
|
||||
gr.Slider(4, 64, label='Number of Punks', step=1, default=10), # 添加另一个滑块!
|
||||
],
|
||||
outputs="image",
|
||||
).launch()
|
||||
```
|
||||
|
||||
新的输入将传递给我们的 `predict()` 函数,所以我们必须对该函数进行一些更改,以接受一个新的参数 :
|
||||
|
||||
```python
|
||||
def predict(seed, num_punks):
|
||||
torch.manual_seed(seed)
|
||||
z = torch.randn(num_punks, 100, 1, 1)
|
||||
punks = model(z)
|
||||
save_image(punks, "punks.png", normalize=True)
|
||||
return 'punks.png'
|
||||
```
|
||||
|
||||
当您重新启动界面时,您应该会看到一个第二个滑块,它可以让您控制 punk 的数量!
|
||||
|
||||
## 第五步-完善它
|
||||
|
||||
您的 Gradio 应用已经准备好运行了,但是您可以添加一些额外的功能来使其真正准备好发光 ✨
|
||||
|
||||
我们可以添加一些用户可以轻松尝试的示例,通过将其添加到 `gr.Interface` 中实现 :
|
||||
|
||||
```python
|
||||
gr.Interface(
|
||||
# ...
|
||||
# 将所有内容保持不变,然后添加
|
||||
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
|
||||
).launch(cache_examples=True) # cache_examples是可选的
|
||||
```
|
||||
|
||||
`examples` 参数接受一个列表的列表,其中子列表中的每个项目的顺序与我们列出的 `inputs` 的顺序相同。所以在我们的例子中,`[seed, num_punks]`。试一试吧!
|
||||
|
||||
您还可以尝试在 `gr.Interface` 中添加 `title`、`description` 和 `article`。每个参数都接受一个字符串,所以试试看发生了什么👀 `article` 也接受 HTML,如[前面的指南](./key_features/#descriptive-content)所述!
|
||||
|
||||
当您完成所有操作后,您可能会得到类似于这样的结果 :
|
||||
|
||||
<iframe src="https://nimaboscarino-cryptopunks.hf.space" frameBorder="0" height="855" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
供参考,这是我们的完整代码 :
|
||||
|
||||
```python
|
||||
import torch
|
||||
from torch import nn
|
||||
from huggingface_hub import hf_hub_download
|
||||
from torchvision.utils import save_image
|
||||
import gradio as gr
|
||||
|
||||
class Generator(nn.Module):
|
||||
# 关于nc、nz和ngf的解释,请参见下面的链接
|
||||
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
|
||||
def __init__(self, nc=4, nz=100, ngf=64):
|
||||
super(Generator, self).__init__()
|
||||
self.network = nn.Sequential(
|
||||
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
|
||||
nn.BatchNorm2d(ngf * 4),
|
||||
nn.ReLU(True),
|
||||
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
|
||||
nn.BatchNorm2d(ngf * 2),
|
||||
nn.ReLU(True),
|
||||
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
|
||||
nn.BatchNorm2d(ngf),
|
||||
nn.ReLU(True),
|
||||
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
|
||||
nn.Tanh(),
|
||||
)
|
||||
|
||||
def forward(self, input):
|
||||
output = self.network(input)
|
||||
return output
|
||||
|
||||
model = Generator()
|
||||
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
|
||||
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # 如果您有可用的GPU,使用'cuda'
|
||||
|
||||
def predict(seed, num_punks):
|
||||
torch.manual_seed(seed)
|
||||
z = torch.randn(num_punks, 100, 1, 1)
|
||||
punks = model(z)
|
||||
save_image(punks, "punks.png", normalize=True)
|
||||
return 'punks.png'
|
||||
|
||||
gr.Interface(
|
||||
predict,
|
||||
inputs=[
|
||||
gr.Slider(0, 1000, label='Seed', default=42),
|
||||
gr.Slider(4, 64, label='Number of Punks', step=1, default=10),
|
||||
],
|
||||
outputs="image",
|
||||
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
|
||||
).launch(cache_examples=True)
|
||||
```
|
||||
----------
|
||||
|
||||
恭喜!你已经成功构建了自己的基于 GAN 的 CryptoPunks 生成器,配备了一个时尚的 Gradio 界面,使任何人都能轻松使用。现在你可以在 Hub 上[寻找更多的 GANs](https://huggingface.co/models?other=gan)(或者自己训练)并继续制作更多令人赞叹的演示项目。🤗
|
||||
81
guides/cn/07_other-tutorials/creating-a-chatbot.md
Normal file
@ -0,0 +1,81 @@
|
||||
# 如何创建一个聊天机器人
|
||||
|
||||
Tags: NLP, TEXT, CHAT
|
||||
Related spaces: https://huggingface.co/spaces/gradio/chatbot_streaming, https://huggingface.co/spaces/project-baize/Baize-7B,
|
||||
## 简介
|
||||
|
||||
聊天机器人在自然语言处理 (NLP) 研究和工业界被广泛使用。由于聊天机器人是直接由客户和最终用户使用的,因此验证聊天机器人在面对各种输入提示时的行为是否符合预期至关重要。
|
||||
|
||||
通过使用 `gradio`,您可以轻松构建聊天机器人模型的演示,并与用户共享,或使用直观的聊天机器人图形界面自己尝试。
|
||||
|
||||
本教程将展示如何使用 Gradio 制作几种不同类型的聊天机器人用户界面:首先是一个简单的文本显示界面,其次是一个用于流式文本响应的界面,最后一个是可以处理媒体文件的聊天机器人。我们创建的聊天机器人界面将如下所示:
|
||||
|
||||
$ 演示 _ 聊天机器人 _ 流式
|
||||
|
||||
**先决条件**:我们将使用 `gradio.Blocks` 类来构建我们的聊天机器人演示。
|
||||
如果您对此还不熟悉,可以[先阅读 Blocks 指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)。同时,请确保您使用的是**最新版本**的 Gradio:`pip install --upgrade gradio`。
|
||||
|
||||
## 简单聊天机器人演示
|
||||
|
||||
让我们从重新创建上面的简单演示开始。正如您可能已经注意到的,我们的机器人只是随机对任何输入回复 " 你好吗?"、" 我爱你 " 或 " 我非常饿 "。这是使用 Gradio 创建此演示的代码:
|
||||
|
||||
$ 代码 _ 简单聊天机器人
|
||||
|
||||
这里有三个 Gradio 组件:
|
||||
|
||||
* 一个 `Chatbot`,其值将整个对话的历史记录作为用户和机器人之间的响应对列表存储。
|
||||
* 一个文本框,用户可以在其中键入他们的消息,然后按下 Enter/ 提交以触发聊天机器人的响应
|
||||
* 一个 `ClearButton` 按钮,用于清除文本框和整个聊天机器人的历史记录
|
||||
|
||||
我们有一个名为 `respond()` 的函数,它接收聊天机器人的整个历史记录,附加一个随机消息,等待 1 秒,然后返回更新后的聊天历史记录。`respond()` 函数在返回时还清除了文本框。
|
||||
|
||||
当然,实际上,您会用自己更复杂的函数替换 `respond()`,该函数可能调用预训练模型或 API 来生成响应。
|
||||
|
||||
$ 演示 _ 简单聊天机器人
|
||||
|
||||
## 为聊天机器人添加流式响应
|
||||
|
||||
我们可以通过几种方式来改进上述聊天机器人的用户体验。首先,我们可以流式传输响应,以便用户不必等待太长时间才能生成消息。其次,我们可以让用户的消息在聊天历史记录中立即出现,同时聊天机器人的响应正在生成。以下是实现这一点的代码:
|
||||
|
||||
$code_chatbot_streaming
|
||||
|
||||
当用户提交他们的消息时,您会注意到我们现在使用 `.then()` 与三个事件事件 *链* 起来:
|
||||
|
||||
1. 第一个方法 `user()` 用用户消息更新聊天机器人并清除输入字段。此方法还使输入字段处于非交互状态,以防聊天机器人正在响应时用户发送另一条消息。由于我们希望此操作立即发生,因此我们设置 `queue=False`,以跳过任何可能的队列。聊天机器人的历史记录附加了`(user_message, None)`,其中的 `None` 表示机器人未作出响应。
|
||||
|
||||
2. 第二个方法 `bot()` 使用机器人的响应更新聊天机器人的历史记录。我们不是创建新消息,而是将先前创建的 `None` 消息替换为机器人的响应。最后,我们逐个字符构造消息并 `yield` 正在构建的中间输出。Gradio 会自动将带有 `yield` 关键字的任何函数 [转换为流式输出接口](/key-features/#iterative-outputs)。
|
||||
|
||||
3. 第三个方法使输入字段再次可以交互,以便用户可以向机器人发送另一条消息。
|
||||
|
||||
当然,实际上,您会用自己更复杂的函数替换 `bot()`,该函数可能调用预训练模型或 API 来生成响应。
|
||||
|
||||
最后,我们通过运行 `demo.queue()` 启用排队,这对于流式中间输出是必需的。您可以通过滚动到本页面顶部的演示来尝试改进后的聊天机器人。
|
||||
|
||||
## 添加 Markdown、图片、音频或视频
|
||||
|
||||
`gr.Chatbot` 组件支持包含加粗、斜体和代码等一部分 Markdown 功能。例如,我们可以编写一个函数,以粗体回复用户的消息,类似于 **That's cool!**,如下所示:
|
||||
|
||||
```py
|
||||
def bot(history):
|
||||
response = "**That's cool!**"
|
||||
history[-1][1] = response
|
||||
return history
|
||||
```
|
||||
|
||||
此外,它还可以处理图片、音频和视频等媒体文件。要传递媒体文件,我们必须将文件作为两个字符串的元组传递,如`(filepath, alt_text)` 所示。`alt_text` 是可选的,因此您还可以只传入只有一个元素的元组`(filepath,)`,如下所示:
|
||||
|
||||
```python
|
||||
def add_file(history, file):
|
||||
history = history + [((file.name,), None)]
|
||||
return history
|
||||
```
|
||||
|
||||
将所有这些放在一起,我们可以创建一个*多模态*聊天机器人,其中包含一个文本框供用户提交文本,以及一个文件上传按钮供提交图像 / 音频 / 视频文件。余下的代码看起来与之前的代码几乎相同:
|
||||
|
||||
$code_chatbot_multimodal
|
||||
$demo_chatbot_multimodal
|
||||
|
||||
你完成了!这就是构建聊天机器人模型界面所需的所有代码。最后,我们将结束我们的指南,并提供一些在 Spaces 上运行的聊天机器人的链接,以让你了解其他可能性:
|
||||
|
||||
* [project-baize/Baize-7B](https://huggingface.co/spaces/project-baize/Baize-7B):一个带有停止生成和重新生成响应功能的样式化聊天机器人。
|
||||
* [MAGAer13/mPLUG-Owl](https://huggingface.co/spaces/MAGAer13/mPLUG-Owl):一个多模态聊天机器人,允许您对响应进行投票。
|
||||
390
guides/cn/07_other-tutorials/creating-a-new-component.md
Normal file
@ -0,0 +1,390 @@
|
||||
# 如何创建一个新组件
|
||||
|
||||
## 简介
|
||||
|
||||
本指南旨在说明如何添加一个新组件,你可以在 Gradio 应用程序中使用该组件。该指南将通过代码片段逐步展示如何添加[ColorPicker](https://gradio.app/docs/#colorpicker)组件。
|
||||
|
||||
## 先决条件
|
||||
|
||||
确保您已经按照[CONTRIBUTING.md](https://github.com/gradio-app/gradio/blob/main/CONTRIBUTING.md)指南设置了本地开发环境(包括客户端和服务器端)。
|
||||
|
||||
以下是在 Gradio 上创建新组件的步骤:
|
||||
|
||||
1. [创建一个新的 Python 类并导入它](#1-create-a-new-python-class-and-import-it)
|
||||
2. [创建一个新的 Svelte 组件](#2-create-a-new-svelte-component)
|
||||
3. [创建一个新的演示](#3-create-a-new-demo)
|
||||
|
||||
## 1. 创建一个新的 Python 类并导入它
|
||||
|
||||
首先要做的是在[components.py](https://github.com/gradio-app/gradio/blob/main/gradio/components.py)文件中创建一个新的类。这个 Python 类应该继承自一系列的基本组件,并且应该根据要添加的组件的类型(例如输入、输出或静态组件)将其放置在文件中的正确部分。
|
||||
一般来说,建议参考现有的组件(例如[TextBox](https://github.com/gradio-app/gradio/blob/main/gradio/components.py#L290)),将其代码复制为骨架,然后根据实际情况进行修改。
|
||||
|
||||
让我们来看一下添加到[components.py](https://github.com/gradio-app/gradio/blob/main/gradio/components.py)文件中的 ColorPicker 组件的类:
|
||||
|
||||
```python
|
||||
@document()
|
||||
class ColorPicker(Changeable, Submittable, IOComponent):
|
||||
"""
|
||||
创建一个颜色选择器,用户可以选择颜色作为字符串输入。
|
||||
预处理:将选择的颜色值作为{str}传递给函数。
|
||||
后处理:期望从函数中返回一个{str},并将颜色选择器的值设置为它。
|
||||
示例格式:表示颜色的十六进制{str},例如红色的"#ff0000"。
|
||||
演示:color_picker,color_generator
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
value: str = None,
|
||||
*,
|
||||
label: Optional[str] = None,
|
||||
show_label: bool = True,
|
||||
interactive: Optional[bool] = None,
|
||||
visible: bool = True,
|
||||
elem_id: Optional[str] = None,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Parameters:
|
||||
"""
|
||||
Parameters:
|
||||
value: default text to provide in color picker.
|
||||
label: component name in interface.
|
||||
show_label: if True, will display label.
|
||||
interactive: if True, will be rendered as an editable color picker; if False, editing will be disabled. If not provided, this is inferred based on whether the component is used as an input or output.
|
||||
visible: If False, component will be hidden.
|
||||
elem_id: An optional string that is assigned as the id of this component in the HTML DOM. Can be used for targeting CSS styles.
|
||||
"""
|
||||
self.value = self.postprocess(value)
|
||||
self.cleared_value = "#000000"
|
||||
self.test_input = value
|
||||
IOComponent.__init__(
|
||||
self,
|
||||
label=label,
|
||||
show_label=show_label,
|
||||
interactive=interactive,
|
||||
visible=visible,
|
||||
elem_id=elem_id,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
def get_config(self):
|
||||
return {
|
||||
"value": self.value,
|
||||
**IOComponent.get_config(self),
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def update(
|
||||
value: Optional[Any] = None,
|
||||
label: Optional[str] = None,
|
||||
show_label: Optional[bool] = None,
|
||||
visible: Optional[bool] = None,
|
||||
interactive: Optional[bool] = None,
|
||||
):
|
||||
return {
|
||||
"value": value,
|
||||
"label": label,
|
||||
"show_label": show_label,
|
||||
"visible": visible,
|
||||
"interactive": interactive,
|
||||
"__type__": "update",
|
||||
}
|
||||
|
||||
# 输入功能
|
||||
def preprocess(self, x: str | None) -> Any:
|
||||
"""
|
||||
Any preprocessing needed to be performed on function input.
|
||||
Parameters:
|
||||
x (str): text
|
||||
Returns:
|
||||
(str): text
|
||||
"""
|
||||
if x is None:
|
||||
return None
|
||||
else:
|
||||
return str(x)
|
||||
|
||||
def preprocess_example(self, x: str | None) -> Any:
|
||||
"""
|
||||
在传递给主函数之前,对示例进行任何预处理。
|
||||
"""
|
||||
if x is None:
|
||||
return None
|
||||
else:
|
||||
return str(x)
|
||||
|
||||
# 输出功能
|
||||
def postprocess(self, y: str | None):
|
||||
"""
|
||||
Any postprocessing needed to be performed on function output.
|
||||
Parameters:
|
||||
y (str | None): text
|
||||
Returns:
|
||||
(str | None): text
|
||||
"""
|
||||
if y is None:
|
||||
return None
|
||||
else:
|
||||
return str(y)
|
||||
|
||||
def deserialize(self, x):
|
||||
"""
|
||||
将从调用接口的序列化输出(例如base64表示)转换为输出的人类可读版本(图像的路径等)
|
||||
"""
|
||||
return x
|
||||
```
|
||||
|
||||
一旦定义完,就需要在[\_\_init\_\_](https://github.com/gradio-app/gradio/blob/main/gradio/__init__.py)模块类中导入新类,以使其可见。
|
||||
|
||||
```python
|
||||
|
||||
from gradio.components import (
|
||||
...
|
||||
ColorPicker,
|
||||
...
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
### 1.1 为 Python 类编写单元测试
|
||||
|
||||
在开发新组件时,还应为其编写一套单元测试。这些测试应该放在[gradio/test/test_components.py](https://github.com/gradio-app/gradio/blob/main/test/test_components.py)文件中。同样,如上所述,参考其他组件的测试(例如[Textbox](https://github.com/gradio-app/gradio/blob/main/test/test_components.py))并添加尽可能多的单元测试,以测试新组件的所有不同方面和功能。例如,为 ColorPicker 组件添加了以下测试:
|
||||
|
||||
```python
|
||||
class TestColorPicker(unittest.TestCase):
|
||||
def test_component_functions(self):
|
||||
"""
|
||||
Preprocess, postprocess, serialize, save_flagged, restore_flagged, tokenize, get_config
|
||||
"""
|
||||
color_picker_input = gr.ColorPicker()
|
||||
self.assertEqual(color_picker_input.preprocess("#000000"), "#000000")
|
||||
self.assertEqual(color_picker_input.preprocess_example("#000000"), "#000000")
|
||||
self.assertEqual(color_picker_input.postprocess(None), None)
|
||||
self.assertEqual(color_picker_input.postprocess("#FFFFFF"), "#FFFFFF")
|
||||
self.assertEqual(color_picker_input.serialize("#000000", True), "#000000")
|
||||
|
||||
color_picker_input.interpretation_replacement = "unknown"
|
||||
|
||||
self.assertEqual(
|
||||
color_picker_input.get_config(),
|
||||
{
|
||||
"value": None,
|
||||
"show_label": True,
|
||||
"label": None,
|
||||
"style": {},
|
||||
"elem_id": None,
|
||||
"visible": True,
|
||||
"interactive": None,
|
||||
"name": "colorpicker",
|
||||
},
|
||||
)
|
||||
|
||||
def test_in_interface_as_input(self):
|
||||
"""
|
||||
接口、处理、解释
|
||||
"""
|
||||
iface = gr.Interface(lambda x: x, "colorpicker", "colorpicker")
|
||||
self.assertEqual(iface.process(["#000000"]), ["#000000"])
|
||||
|
||||
def test_in_interface_as_output(self):
|
||||
"""
|
||||
接口、处理
|
||||
|
||||
"""
|
||||
iface = gr.Interface(lambda x: x, "colorpicker", gr.ColorPicker())
|
||||
self.assertEqual(iface.process(["#000000"]), ["#000000"])
|
||||
|
||||
def test_static(self):
|
||||
"""
|
||||
后处理
|
||||
"""
|
||||
component = gr.ColorPicker("#000000")
|
||||
self.assertEqual(component.get_config().get("value"), "#000000")
|
||||
```
|
||||
|
||||
## 2. 创建一个新的 Svelte 组件
|
||||
|
||||
让我们来看看创建新组件的前端并将其与其 Python 代码映射起来的步骤:
|
||||
|
||||
- 在 [js 文件夹](https://github.com/gradio-app/gradio/tree/main/js/) 中创建一个新的 UI-side Svelte 组件,并确定要放置在什么地方。选项包括:创建新组件的包(如果与现有组件完全不同),或将新组件添加到现有包中,例如 [form 包](https://github.com/gradio-app/gradio/tree/main/js/form)。例如,ColorPicker 组件被包含在 form 包中,因为它与已存在的组件相似。
|
||||
- 在您将 Svelte 组件放置的包的 src 文件夹中创建一个带有适当名称的文件,注意:名称必须以大写字母开头。这是“核心”组件,是没有 Gradio 特定功能了解的通用组件。最初,将任何文本 /HTML 添加到此文件,以便组件呈现任何内容。ColorPicker 的 Svelte 应用程序代码如下所示:
|
||||
|
||||
```typescript
|
||||
<script lang="ts">
|
||||
import { createEventDispatcher } from "svelte";
|
||||
import { get_styles } from "@gradio/utils";
|
||||
import { BlockTitle } from "@gradio/atoms";
|
||||
import type { Styles } from "@gradio/utils";
|
||||
|
||||
export let value: string = "#000000";
|
||||
export let style: Styles = {};
|
||||
export let label: string;
|
||||
export let disabled = false;
|
||||
export let show_label: boolean = true;
|
||||
|
||||
$: value;
|
||||
$: handle_change(value);
|
||||
|
||||
const dispatch = createEventDispatcher<{
|
||||
change: string;
|
||||
submit: undefined;
|
||||
}>();
|
||||
|
||||
function handle_change(val: string) {
|
||||
dispatch("change", val);
|
||||
}
|
||||
|
||||
$: ({ styles } = get_styles(style, ["rounded", "border"]));
|
||||
</script>
|
||||
|
||||
<!-- svelte-ignore a11y-label-has-associated-control -->
|
||||
<label class="block">
|
||||
<BlockTitle {show_label}>{label}</BlockTitle>
|
||||
<input
|
||||
type="color"
|
||||
class="gr-box-unrounded {classes}"
|
||||
bind:value
|
||||
{disabled}
|
||||
/>
|
||||
</label>
|
||||
```
|
||||
|
||||
- 通过执行 `export { default as FileName } from "./FileName.svelte"`,在您将 Svelte 组件放置的包的 index.ts 文件中导出此文件。例如,在 [index.ts](https://github.com/gradio-app/gradio/blob/main/js/form/src/index.ts) 文件中导出了 ColorPicker 文件,并通过 `export { default as ColorPicker } from "./ColorPicker.svelte";` 执行导出。
|
||||
- 创建 [js/app/src/components](https://github.com/gradio-app/gradio/tree/main/js/app/src/components) 中的 Gradio 特定组件。这是一个 Gradio 包装器,处理库的特定逻辑,将必要的数据传递给核心组件,并附加任何必要的事件监听器。复制另一个组件的文件夹,重新命名并编辑其中的代码,保持结构不变。
|
||||
|
||||
在这里,您将拥有三个文件,第一个文件用于 Svelte 应用程序,具体如下所示:
|
||||
|
||||
```typescript
|
||||
<svelte:options accessors={true} />
|
||||
|
||||
<script lang="ts">
|
||||
import { ColorPicker } from "@gradio/form";
|
||||
import { Block } from "@gradio/atoms";
|
||||
import StatusTracker from "../StatusTracker/StatusTracker.svelte";
|
||||
import type { LoadingStatus } from "../StatusTracker/types";
|
||||
import type { Styles } from "@gradio/utils";
|
||||
|
||||
export let label: string = "ColorPicker";
|
||||
export let elem_id: string = "";
|
||||
export let visible: boolean = true;
|
||||
export let value: string;
|
||||
export let form_position: "first" | "last" | "mid" | "single" = "single";
|
||||
export let show_label: boolean;
|
||||
|
||||
export let style: Styles = {};
|
||||
|
||||
export let loading_status: LoadingStatus;
|
||||
|
||||
export let mode: "static" | "dynamic";
|
||||
</script>
|
||||
|
||||
<Block
|
||||
{visible}
|
||||
{form_position}
|
||||
{elem_id}
|
||||
disable={typeof style.container === "boolean" && !style.container}
|
||||
>
|
||||
<StatusTracker {...loading_status} />
|
||||
|
||||
<ColorPicker
|
||||
{style}
|
||||
bind:value
|
||||
{label}
|
||||
{show_label}
|
||||
on:change
|
||||
on:submit
|
||||
disabled={mode === "static"}
|
||||
/>
|
||||
</Block>
|
||||
```
|
||||
|
||||
第二个文件包含了前端的测试,例如 ColorPicker 组件的测试:
|
||||
|
||||
```typescript
|
||||
import { test, describe, assert, afterEach } from "vitest";
|
||||
import { cleanup, render } from "@gradio/tootils";
|
||||
|
||||
import ColorPicker from "./ColorPicker.svelte";
|
||||
import type { LoadingStatus } from "../StatusTracker/types";
|
||||
|
||||
const loading_status = {
|
||||
eta: 0,
|
||||
queue_position: 1,
|
||||
status: "complete" as LoadingStatus["status"],
|
||||
scroll_to_output: false,
|
||||
visible: true,
|
||||
fn_index: 0
|
||||
};
|
||||
|
||||
describe("ColorPicker", () => {
|
||||
afterEach(() => cleanup());
|
||||
|
||||
test("renders provided value", () => {
|
||||
const { getByDisplayValue } = render(ColorPicker, {
|
||||
loading_status,
|
||||
show_label: true,
|
||||
mode: "dynamic",
|
||||
value: "#000000",
|
||||
label: "ColorPicker"
|
||||
});
|
||||
|
||||
const item: HTMLInputElement = getByDisplayValue("#000000");
|
||||
assert.equal(item.value, "#000000");
|
||||
});
|
||||
|
||||
test("changing the color should update the value", async () => {
|
||||
const { component, getByDisplayValue } = render(ColorPicker, {
|
||||
loading_status,
|
||||
show_label: true,
|
||||
mode: "dynamic",
|
||||
value: "#000000",
|
||||
label: "ColorPicker"
|
||||
});
|
||||
|
||||
const item: HTMLInputElement = getByDisplayValue("#000000");
|
||||
|
||||
assert.equal(item.value, "#000000");
|
||||
|
||||
await component.$set({
|
||||
value: "#FFFFFF"
|
||||
});
|
||||
|
||||
assert.equal(component.value, "#FFFFFF");
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
The third one is the index.ts file:
|
||||
|
||||
```typescript
|
||||
export { default as Component } from "./ColorPicker.svelte";
|
||||
export const modes = ["static", "dynamic"];
|
||||
```
|
||||
|
||||
- `directory.ts` 文件中添加组件的映射。复制并粘贴任何组件的映射行,并编辑其文本。键名必须是 Python 库中实际组件名称的小写版本。例如,对于 ColorPicker 组件,映射如下所示:
|
||||
|
||||
```typescript
|
||||
export const component_map = {
|
||||
...
|
||||
colorpicker: () => import("./ColorPicker"),
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
### 2.1 为 Svelte 组件编写单元测试
|
||||
|
||||
在开发新组件时,您还应该为其编写一套单元测试。测试应该放置在新组件的文件夹中,文件名为 MyAwesomeComponent.test.ts。同样,像上面那样参考其他组件的测试(例如[Textbox.test.ts](https://github.com/gradio-app/gradio/blob/main/js/app/src/components/Textbox/Textbox.test.ts)),并添加尽可能多的单元测试,以测试新组件的不同方面和功能。
|
||||
|
||||
### 3. 创建新的演示
|
||||
|
||||
最后一步是在[gradio/demo 文件夹](https://github.com/gradio-app/gradio/tree/main/demo)中创建一个使用新添加的组件的演示。同样,建议参考现有演示。在一个名为 run.py 的文件中编写演示的代码,添加必要的要求和显示应用程序界面的图像。最后添加一个显示其用法的 gif。
|
||||
您可以查看为 ColorPicker 创建的[demo](https://github.com/gradio-app/gradio/tree/main/demo/color_picker),其中以新组件选择的图标和颜色作为输入,并以选择的颜色着色的相同图标作为输出。
|
||||
|
||||
要测试应用程序:
|
||||
|
||||
- 在终端上运行 `python path/demo/run.py`,它会在地址 [http://localhost:7860](http://localhost:7860) 启动后端;
|
||||
- 在另一个终端上,运行 `pnpm dev` 以在 [http://localhost:9876](http://localhost:9876) 上启动具有热重新加载功能的前端。
|
||||
|
||||
## 结论
|
||||
|
||||
在本指南中,我们展示了将新组件添加到 Gradio 是多么简单,逐步介绍了如何添加 ColorPicker 组件。要了解更多细节,可以参考 PR:[#1695](https://github.com/gradio-app/gradio/pull/1695).
|
||||
@ -0,0 +1,178 @@
|
||||
# 使用 Blocks 进行自定义机器学习解释
|
||||
|
||||
Tags: INTERPRETATION, SENTIMENT ANALYSIS
|
||||
|
||||
**前提条件**: 此指南要求您了解 Blocks 和界面的解释功能。请确保[首先阅读 Blocks 指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)以及[高级界面功能指南](/advanced-interface-features#interpreting-your-predictions)的解释部分。
|
||||
|
||||
## 简介
|
||||
|
||||
如果您有使用界面类的经验,那么您就知道解释机器学习模型的预测有多么容易,只需要将 `interpretation` 参数设置为 "default" 或 "shap" 即可。
|
||||
|
||||
您可能想知道是否可以将同样的解释功能添加到使用 Blocks API 构建的应用程序中。不仅可以做到,而且 Blocks 的灵活性还可以以不可能使用界面来显示解释的方式!
|
||||
|
||||
本指南将展示如何:
|
||||
|
||||
1. 在 Blocks 应用程序中重新创建界面的解释功能的行为。
|
||||
2. 自定义 Blocks 应用程序中的解释显示方式。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
## 设置 Blocks 应用程序
|
||||
|
||||
让我们使用 Blocks API 构建一款情感分类应用程序。该应用程序将以文本作为输入,并输出此文本表达负面或正面情感的概率。我们会有一个单独的输入 `Textbox` 和一个单独的输出 `Label` 组件。以下是应用程序的代码以及应用程序本身。
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
from transformers import pipeline
|
||||
|
||||
sentiment_classifier = pipeline("text-classification", return_all_scores=True)
|
||||
|
||||
def classifier(text):
|
||||
pred = sentiment_classifier(text)
|
||||
return {p["label"]: p["score"] for p in pred[0]}
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
input_text = gr.Textbox(label="Input Text")
|
||||
with gr.Row():
|
||||
classify = gr.Button("Classify Sentiment")
|
||||
with gr.Column():
|
||||
label = gr.Label(label="Predicted Sentiment")
|
||||
|
||||
classify.click(classifier, input_text, label)
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
<gradio-app space="freddyaboulton/sentiment-classification"> </gradio-app>
|
||||
## 向应用程序添加解释
|
||||
|
||||
我们的目标是向用户呈现输入中的单词如何 contributed 到模型的预测。
|
||||
这将帮助用户理解模型的工作方式,并评估其有效性。
|
||||
例如,我们应该期望我们的模型能够将“happy”和“love”这些词与积极的情感联系起来;如果模型没有联系起来,那么这意味着我们在训练过程中出现了错误!
|
||||
|
||||
对于输入中的每个单词,我们将计算模型预测的积极情感如何受该单词的影响。
|
||||
一旦我们有了这些 `(word, score)` 对,我们就可以使用 Gradio 将其可视化给用户。
|
||||
|
||||
[shap](https://shap.readthedocs.io/en/stable/index.html) 库将帮助我们计算 `(word, score)` 对,而 Gradio 将负责将输出显示给用户。
|
||||
|
||||
以下代码计算 `(word, score)` 对:
|
||||
|
||||
```python
|
||||
def interpretation_function(text):
|
||||
explainer = shap.Explainer(sentiment_classifier)
|
||||
shap_values = explainer([text])
|
||||
|
||||
# Dimensions are (batch size, text size, number of classes)
|
||||
# Since we care about positive sentiment, use index 1
|
||||
scores = list(zip(shap_values.data[0], shap_values.values[0, :, 1]))
|
||||
# Scores contains (word, score) pairs
|
||||
|
||||
|
||||
# Format expected by gr.components.Interpretation
|
||||
return {"original": text, "interpretation": scores}
|
||||
```
|
||||
|
||||
现在,我们所要做的就是添加一个按钮,在单击后运行此函数。
|
||||
为了显示解释,我们将使用 `gr.components.Interpretation`。
|
||||
这将使输入中的每个单词变成红色或蓝色。
|
||||
如果它有助于积极情感,则为红色,如果它有助于负面情感,则为蓝色。
|
||||
这就是界面如何显示文本的解释输出。
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
input_text = gr.Textbox(label="Input Text")
|
||||
with gr.Row():
|
||||
classify = gr.Button("Classify Sentiment")
|
||||
interpret = gr.Button("Interpret")
|
||||
with gr.Column():
|
||||
label = gr.Label(label="Predicted Sentiment")
|
||||
with gr.Column():
|
||||
interpretation = gr.components.Interpretation(input_text)
|
||||
classify.click(classifier, input_text, label)
|
||||
interpret.click(interpretation_function, input_text, interpretation)
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
<gradio-app space="freddyaboulton/sentiment-classification-interpretation"> </gradio-app>
|
||||
|
||||
## 自定义解释的显示方式
|
||||
|
||||
`gr.components.Interpretation` 组件以很好的方式显示单个单词如何 contributed 到情感预测,但是如果我们还想显示分数本身,怎么办呢?
|
||||
|
||||
一种方法是生成一个条形图,其中单词在水平轴上,条形高度对应 shap 得分。
|
||||
|
||||
我们可以通过修改我们的 `interpretation_function` 来执行此操作,以同时返回一个 matplotlib 条形图。我们将在单独的选项卡中使用 'gr.Plot' 组件显示它。
|
||||
|
||||
这是解释函数的外观:
|
||||
```python
|
||||
def interpretation_function(text):
|
||||
explainer = shap.Explainer(sentiment_classifier)
|
||||
shap_values = explainer([text])
|
||||
# Dimensions are (batch size, text size, number of classes)
|
||||
# Since we care about positive sentiment, use index 1
|
||||
scores = list(zip(shap_values.data[0], shap_values.values[0, :, 1]))
|
||||
|
||||
scores_desc = sorted(scores, key=lambda t: t[1])[::-1]
|
||||
|
||||
# Filter out empty string added by shap
|
||||
scores_desc = [t for t in scores_desc if t[0] != ""]
|
||||
|
||||
fig_m = plt.figure()
|
||||
|
||||
# Select top 5 words that contribute to positive sentiment
|
||||
plt.bar(x=[s[0] for s in scores_desc[:5]],
|
||||
height=[s[1] for s in scores_desc[:5]])
|
||||
plt.title("Top words contributing to positive sentiment")
|
||||
plt.ylabel("Shap Value")
|
||||
plt.xlabel("Word")
|
||||
return {"original": text, "interpretation": scores}, fig_m
|
||||
```
|
||||
|
||||
以下是应用程序代码:
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
input_text = gr.Textbox(label="Input Text")
|
||||
with gr.Row():
|
||||
classify = gr.Button("Classify Sentiment")
|
||||
interpret = gr.Button("Interpret")
|
||||
with gr.Column():
|
||||
label = gr.Label(label="Predicted Sentiment")
|
||||
with gr.Column():
|
||||
with gr.Tabs():
|
||||
with gr.TabItem("Display interpretation with built-in component"):
|
||||
interpretation = gr.components.Interpretation(input_text)
|
||||
with gr.TabItem("Display interpretation with plot"):
|
||||
interpretation_plot = gr.Plot()
|
||||
|
||||
classify.click(classifier, input_text, label)
|
||||
interpret.click(interpretation_function, input_text, [interpretation, interpretation_plot])
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
demo 在这里 !
|
||||
|
||||
<gradio-app space="freddyaboulton/sentiment-classification-interpretation-tabs"> </gradio-app>
|
||||
|
||||
## Beyond Sentiment Classification (超越情感分类)
|
||||
|
||||
尽管到目前为止我们已经集中讨论了情感分类,但几乎可以为任何机器学习模型添加解释。
|
||||
输出必须是 `gr.Image` 或 `gr.Label`,但输入几乎可以是任何内容 (`gr.Number`, `gr.Slider`, `gr.Radio`, `gr.Image`)。
|
||||
|
||||
这是一个使用 Blocks 构建的图像分类模型解释演示:
|
||||
|
||||
<gradio-app space="freddyaboulton/image-classification-interpretation-blocks"> </gradio-app>
|
||||
|
||||
## 结语
|
||||
|
||||
我们深入地探讨了解释的工作原理以及如何将其添加到您的 Blocks 应用程序中。
|
||||
|
||||
我们还展示了 Blocks API 如何让您控制解释在应用程序中的可视化方式。
|
||||
|
||||
添加解释是使您的用户了解和信任您的模型的有用方式。现在,您拥有了将其添加到所有应用程序所需的所有工具!
|
||||
@ -0,0 +1,144 @@
|
||||
# 通过自动重载实现更快的开发
|
||||
|
||||
**先决条件**:本指南要求您了解块的知识。请确保[先阅读块指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)。
|
||||
|
||||
本指南介绍了自动重新加载、在 Python IDE 中重新加载以及在 Jupyter Notebooks 中使用 gradio 的方法。
|
||||
|
||||
## 为什么要使用自动重载?
|
||||
|
||||
当您构建 Gradio 演示时,特别是使用 Blocks 构建时,您可能会发现反复运行代码以测试更改很麻烦。
|
||||
|
||||
为了更快速、更便捷地编写代码,我们已经简化了在 **Python IDE**(如 VS Code、Sublime Text、PyCharm 等)中开发或从终端运行 Python 代码时“重新加载”Gradio 应用的方式。我们还开发了一个类似的“魔法命令”,使您可以更快速地重新运行单元格,如果您使用 Jupyter Notebooks(或类似的环境,如 Colab)的话。
|
||||
|
||||
这个简短的指南将涵盖这两种方法,所以无论您如何编写 Python 代码,您都将知道如何更快地构建 Gradio 应用程序。
|
||||
|
||||
## Python IDE 重载 🔥
|
||||
|
||||
如果您使用 Python IDE 构建 Gradio Blocks,那么代码文件(假设命名为 `run.py`)可能如下所示:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.Markdown("# 来自Gradio的问候!")
|
||||
inp = gr.Textbox(placeholder="您叫什么名字?")
|
||||
out = gr.Textbox()
|
||||
|
||||
inp.change(fn=lambda x: f"欢迎,{x}!",
|
||||
inputs=inp,
|
||||
outputs=out)
|
||||
|
||||
if __name__ == "__main__":
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
问题在于,每当您想要更改布局、事件或组件时,都必须通过编写 `python run.py` 来关闭和重新运行应用程序。
|
||||
|
||||
而不是这样做,您可以通过更改 1 个单词来以**重新加载模式**运行代码:将 `python` 更改为 `gradio`:
|
||||
|
||||
在终端中运行 `gradio run.py`。就是这样!
|
||||
|
||||
现在,您将看到类似于这样的内容:
|
||||
|
||||
```bash
|
||||
Launching in *reload mode* on: http://127.0.0.1:7860 (Press CTRL+C to quit)
|
||||
|
||||
Watching...
|
||||
|
||||
WARNING: The --reload flag should not be used in production on Windows.
|
||||
```
|
||||
|
||||
这里最重要的一行是 `正在观察 ...`。这里发生的情况是 Gradio 将观察 `run.py` 文件所在的目录,如果文件发生更改,它将自动为您重新运行文件。因此,您只需专注于编写代码,Gradio 演示将自动刷新 🥳
|
||||
|
||||
⚠️ 警告:`gradio` 命令不会检测传递给 `launch()` 方法的参数,因为在重新加载模式下从未调用 `launch()` 方法。例如,设置 `launch()` 中的 `auth` 或 `show_error` 不会在应用程序中反映出来。
|
||||
|
||||
当您使用重新加载模式时,请记住一件重要的事情:Gradio 专门查找名为 `demo` 的 Gradio Blocks/Interface 演示。如果您将演示命名为其他名称,您需要在代码中的第二个参数中传入演示的 FastAPI 应用程序的名称。对于 Gradio 演示,可以使用 `.app` 属性访问 FastAPI 应用程序。因此,如果您的 `run.py` 文件如下所示:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
with gr.Blocks() as my_demo:
|
||||
gr.Markdown("# 来自Gradio的问候!")
|
||||
inp = gr.Textbox(placeholder="您叫什么名字?")
|
||||
out = gr.Textbox()
|
||||
|
||||
inp.change(fn=lambda x: f"欢迎,{x}!",
|
||||
inputs=inp,
|
||||
outputs=out)
|
||||
|
||||
if __name__ == "__main__":
|
||||
my_demo.launch()
|
||||
```
|
||||
|
||||
那么您可以这样启动它:`gradio run.py my_demo.app`。
|
||||
|
||||
🔥 如果您的应用程序接受命令行参数,您也可以传递它们。下面是一个例子:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
import argparse
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--name", type=str, default="User")
|
||||
args, unknown = parser.parse_known_args()
|
||||
|
||||
with gr.Blocks() as demo:
|
||||
gr.Markdown(f"# 欢迎 {args.name}!")
|
||||
inp = gr.Textbox()
|
||||
out = gr.Textbox()
|
||||
|
||||
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
|
||||
|
||||
if __name__ == "__main__":
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
您可以像这样运行它:`gradio run.py --name Gretel`
|
||||
|
||||
作为一个小提示,只要更改了 `run.py` 源代码或 Gradio 源代码,自动重新加载就会发生。这意味着如果您决定[为 Gradio 做贡献](https://github.com/gradio-app/gradio/blob/main/CONTRIBUTING.md),这将非常有用 ✅
|
||||
|
||||
## Jupyter Notebook 魔法命令🔮
|
||||
|
||||
如果您使用 Jupyter Notebooks(或 Colab Notebooks 等)进行开发,我们也为您提供了一个解决方案!
|
||||
|
||||
我们开发了一个 **magic command 魔法命令**,可以为您创建和运行一个 Blocks 演示。要使用此功能,在笔记本顶部加载 gradio 扩展:
|
||||
|
||||
`%load_ext gradio`
|
||||
|
||||
然后,在您正在开发 Gradio 演示的单元格中,只需在顶部写入魔法命令**`%%blocks`**,然后像平常一样编写布局和组件:
|
||||
|
||||
```py
|
||||
%%blocks
|
||||
|
||||
import gradio as gr
|
||||
|
||||
gr.Markdown("# 来自Gradio的问候!")
|
||||
inp = gr.Textbox(placeholder="您叫什么名字?")
|
||||
out = gr.Textbox()
|
||||
|
||||
inp.change(fn=lambda x: f"欢迎,{x}!",
|
||||
inputs=inp,
|
||||
outputs=out)
|
||||
```
|
||||
|
||||
请注意:
|
||||
|
||||
* 您不需要放置样板代码 `with gr.Blocks() as demo:` 和 `demo.launch()` — Gradio 会自动为您完成!
|
||||
|
||||
* 每次重新运行单元格时,Gradio 都将在相同的端口上重新启动您的应用程序,并使用相同的底层网络服务器。这意味着您将比正常重新运行单元格更快地看到变化。
|
||||
|
||||
下面是在 Jupyter Notebook 中的示例:
|
||||
|
||||

|
||||
|
||||
🪄这在 colab 笔记本中也适用,您可以在其中看到 Blocks 魔法效果。尝试进行一些更改并重新运行带有 Gradio 代码的单元格!
|
||||
|
||||
Notebook Magic 现在是作者构建 Gradio 演示的首选方式。无论您如何编写 Python 代码,我们都希望这两种方法都能为您提供更好的 Gradio 开发体验。
|
||||
|
||||
--------
|
||||
|
||||
## 下一步
|
||||
|
||||
既然您已经了解了如何使用 Gradio 快速开发,请开始构建自己的应用程序吧!
|
||||
|
||||
如果你正在寻找灵感,请尝试浏览其他人用 Gradio 构建的演示,[浏览 Hugging Face Spaces](http://hf.space/) 🤗
|
||||
@ -0,0 +1,72 @@
|
||||
# 如何使用 3D 模型组件
|
||||
|
||||
相关空间:https://huggingface.co/spaces/dawood/Model3D, https://huggingface.co/spaces/radames/PIFu-Clothed-Human-Digitization, https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-obj
|
||||
标签:VISION, IMAGE
|
||||
|
||||
## 介绍
|
||||
|
||||
机器学习中的 3D 模型越来越受欢迎,并且是一些最有趣的演示实验。使用 `gradio`,您可以轻松构建您的 3D 图像模型的演示,并与任何人分享。Gradio 3D 模型组件接受 3 种文件类型,包括:*.obj*,*.glb* 和 *.gltf*。
|
||||
|
||||
本指南将向您展示如何使用几行代码构建您的 3D 图像模型的演示;像下面这个示例一样。点击、拖拽和缩放来玩转 3D 对象:
|
||||
|
||||
<gradio-app space="dawood/Model3D"> </gradio-app>
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保已经[安装](https://gradio.app/quickstart)了 `gradio` Python 包。
|
||||
|
||||
## 查看代码
|
||||
|
||||
让我们来看看如何创建上面的最简界面。在这种情况下,预测函数将只返回原始的 3D 模型网格,但您可以更改此函数以在您的机器学习模型上运行推理。我们将在下面看更复杂的示例。
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
def load_mesh(mesh_file_name):
|
||||
return mesh_file_name
|
||||
|
||||
demo = gr.Interface(
|
||||
fn=load_mesh,
|
||||
inputs=gr.Model3D(),
|
||||
outputs=gr.Model3D(clear_color=[0.0, 0.0, 0.0, 0.0], label="3D Model"),
|
||||
examples=[
|
||||
["files/Bunny.obj"],
|
||||
["files/Duck.glb"],
|
||||
["files/Fox.gltf"],
|
||||
["files/face.obj"],
|
||||
],
|
||||
cache_examples=True,
|
||||
)
|
||||
|
||||
demo.launch()
|
||||
```
|
||||
|
||||
让我们来解析上面的代码:
|
||||
|
||||
`load_mesh`:这是我们的“预测”函数,为简单起见,该函数将接收 3D 模型网格并返回它。
|
||||
|
||||
创建界面:
|
||||
|
||||
* `fn`:当用户点击提交时使用的预测函数。在我们的例子中,它是 `load_mesh` 函数。
|
||||
* `inputs`:创建一个 model3D 输入组件。输入是一个上传的文件,作为{str}文件路径。
|
||||
* `outputs`:创建一个 model3D 输出组件。输出组件也期望一个文件作为{str}文件路径。
|
||||
* `clear_color`:这是 3D 模型画布的背景颜色。期望 RGBa 值。
|
||||
* `label`:出现在组件左上角的标签。
|
||||
* `examples`:3D 模型文件的列表。3D 模型组件可以接受*.obj*,*.glb*和*.gltf*文件类型。
|
||||
* `cache_examples`:保存示例的预测输出,以节省推理时间。
|
||||
|
||||
## 探索更复杂的 Model3D 演示
|
||||
|
||||
下面是一个使用 DPT 模型预测图像深度,然后使用 3D 点云创建 3D 对象的演示。查看[code.py](https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-obj/blob/main/app.py)文件,了解代码和模型预测函数。
|
||||
<gradio-app space="radames/dpt-depth-estimation-3d-obj"> </gradio-app>
|
||||
|
||||
下面是一个使用 PIFu 模型将穿着衣物的人的图像转换为 3D 数字化模型的演示。查看[spaces.py](https://huggingface.co/spaces/radames/PIFu-Clothed-Human-Digitization/blob/main/PIFu/spaces.py)文件,了解代码和模型预测函数。
|
||||
|
||||
<gradio-app space="radames/PIFu-Clothed-Human-Digitization"> </gradio-app>
|
||||
|
||||
----------
|
||||
|
||||
搞定!这就是构建 Model3D 模型界面所需的所有代码。以下是一些您可能会发现有用的参考资料:
|
||||
|
||||
* Gradio 的[“入门指南”](https://gradio.app/getting_started/)
|
||||
* 第一个[3D 模型演示](https://huggingface.co/spaces/dawood/Model3D)和[完整代码](https://huggingface.co/spaces/dawood/Model3D/tree/main)(在 Hugging Face Spaces 上)
|
||||
79
guides/cn/07_other-tutorials/named-entity-recognition.md
Normal file
@ -0,0 +1,79 @@
|
||||
# 命名实体识别 (Named-Entity Recognition)
|
||||
|
||||
相关空间:https://huggingface.co/spaces/rajistics/biobert_ner_demo,https://huggingface.co/spaces/abidlabs/ner,https://huggingface.co/spaces/rajistics/Financial_Analyst_AI
|
||||
标签:NER,TEXT,HIGHLIGHT
|
||||
|
||||
## 简介
|
||||
|
||||
命名实体识别(NER)又称为标记分类或文本标记,它的任务是对一个句子进行分类,将每个单词(或 "token")归为不同的类别,比如人名、地名或词性等。
|
||||
|
||||
例如,给定以下句子:
|
||||
|
||||
> 芝加哥有巴基斯坦餐厅吗?
|
||||
|
||||
命名实体识别算法可以识别出:
|
||||
* "Chicago" as a **location**
|
||||
* "Pakistani" as an **ethnicity**
|
||||
|
||||
等等。
|
||||
|
||||
使用 `gradio`(特别是 `HighlightedText` 组件),您可以轻松构建一个 NER 模型的 Web 演示并与团队分享。
|
||||
|
||||
这是您将能够构建的一个演示的示例:
|
||||
|
||||
$demo_ner_pipeline
|
||||
|
||||
本教程将展示如何使用预训练的 NER 模型并使用 Gradio 界面部署该模型。我们将展示两种不同的使用 `HighlightedText` 组件的方法--根据您的 NER 模型,可以选择其中任何一种更容易学习的方式!
|
||||
|
||||
### 环境要求
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 包。您还需要一个预训练的命名实体识别模型。在本教程中,我们将使用 `transformers` 库中的一个模型。
|
||||
|
||||
### 方法一:实体字典列表
|
||||
|
||||
许多命名实体识别模型输出的是一个字典列表。每个字典包含一个*实体*,一个 " 起始 " 索引和一个 " 结束 " 索引。这就是 `transformers` 库中的 NER 模型的操作方式。
|
||||
|
||||
```py
|
||||
from transformers import pipeline
|
||||
ner_pipeline = pipeline("ner")
|
||||
ner_pipeline("芝加哥有巴基斯坦餐厅吗?")
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```bash
|
||||
[{'entity': 'I-LOC',
|
||||
'score': 0.9988978,
|
||||
'index': 2,
|
||||
'word': 'Chicago',
|
||||
'start': 5,
|
||||
'end': 12},
|
||||
{'entity': 'I-MISC',
|
||||
'score': 0.9958592,
|
||||
'index': 5,
|
||||
'word': 'Pakistani',
|
||||
'start': 22,
|
||||
'end': 31}]
|
||||
```
|
||||
|
||||
如果您有这样的模型,将其连接到 Gradio 的 `HighlightedText` 组件非常简单。您只需要将这个**实体列表**与**原始文本**以字典的形式传递给模型,其中键分别为 `"entities"` 和 `"text"`。
|
||||
|
||||
下面是一个完整的示例:
|
||||
|
||||
$code_ner_pipeline
|
||||
$demo_ner_pipeline
|
||||
|
||||
### 方法二:元组列表
|
||||
|
||||
将数据传递给 `HighlightedText` 组件的另一种方法是使用元组列表。每个元组的第一个元素应该是被归类为特定实体的单词或词组。第二个元素应该是实体标签(如果不需要标签,则为 `None`)。`HighlightedText` 组件会自动组合单词和标签来显示实体。
|
||||
|
||||
在某些情况下,这比第一种方法更简单。下面是一个使用 Spacy 的词性标注器演示此方法的示例:
|
||||
|
||||
$code_text_analysis
|
||||
$demo_text_analysis
|
||||
|
||||
--------------------------------------------
|
||||
|
||||
到此为止!您已经了解了为您的 NER 模型构建基于 Web 的图形用户界面所需的全部内容。
|
||||
|
||||
有趣的提示:只需在 `launch()` 中设置 `share=True`,即可立即与其他人分享您的 NER 演示。
|
||||
220
guides/cn/07_other-tutorials/real-time-speech-recognition.md
Normal file
@ -0,0 +1,220 @@
|
||||
# 实时语音识别
|
||||
|
||||
Related spaces: https://huggingface.co/spaces/abidlabs/streaming-asr-paused, https://huggingface.co/spaces/abidlabs/full-context-asr
|
||||
Tags: ASR, SPEECH, STREAMING
|
||||
|
||||
## 介绍
|
||||
|
||||
自动语音识别(ASR)是机器学习中非常重要且蓬勃发展的领域,它将口语转换为文本。ASR 算法几乎在每部智能手机上都有运行,并越来越多地嵌入到专业工作流程中,例如护士和医生的数字助手。由于 ASR 算法是直接面向客户和最终用户设计的,因此在面对各种语音模式(不同的口音、音调和背景音频条件)时,验证它们的行为是否符合预期非常重要。
|
||||
|
||||
使用 `gradio`,您可以轻松构建一个 ASR 模型的演示,并与测试团队共享,或通过设备上的麦克风进行自行测试。
|
||||
|
||||
本教程将展示如何使用预训练的语音识别模型并在 Gradio 界面上部署。我们将从一个 **full-context 全文**模型开始,其中用户在进行预测之前要说完整段音频。然后,我们将调整演示以使其变为 **streaming 流式**,这意味着音频模型将在您说话时将语音转换为文本。我们创建的流式演示将如下所示(在下方尝试或[在新标签页中打开](https://huggingface.co/spaces/abidlabs/streaming-asr-paused)):
|
||||
|
||||
<iframe src="https://abidlabs-streaming-asr-paused.hf.space" frameBorder="0" height="350" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
实时 ASR 本质上是*有状态的*,即模型的预测结果取决于用户先前说的单词。因此,在本教程中,我们还将介绍如何在 Gradio 演示中使用 **state**。
|
||||
|
||||
### 先决条件
|
||||
|
||||
确保您已经[安装](/getting_started)了 `gradio` Python 包。您还需要一个预训练的语音识别模型。在本教程中,我们将从两个 ASR 库构建演示:
|
||||
|
||||
* Transformers(为此,`pip install transformers` 和 `pip install torch`)* DeepSpeech(`pip install deepspeech==0.8.2`)
|
||||
|
||||
确保您至少安装了其中之一,以便您可以跟随本教程操作。如果您尚未安装 `ffmpeg`,请在[系统上下载并安装](https://www.ffmpeg.org/download.html),以便从麦克风处理文件。
|
||||
|
||||
下面是构建实时语音识别(ASR)应用程序的步骤:
|
||||
1. [设置 Transformers ASR 模型](#1-set-up-the-transformers-asr-model)
|
||||
2. [使用 Transformers 创建一个全文 ASR 演示]
|
||||
(#2-create-a-full-context-asr-demo-with-transformers)
|
||||
3. [使用 Transformers 创建一个流式 ASR 演示](#3-create-a-streaming-asr-demo-with-transformers)
|
||||
4. [使用 DeepSpeech 创建一个流式 ASR 演示](#4-create-a-streaming-asr-demo-with-deepspeech)
|
||||
|
||||
## 1. 设置 Transformers ASR 模型
|
||||
首先,您需要拥有一个 ASR 模型,您可以自己训练,或者需要下载一个预训练模型。在本教程中,我们将使用 Hugging Face 模型的预训练 ASR 模型 `Wav2Vec2`。
|
||||
|
||||
以下是从 Hugging Face 的 `transformers` 加载 `Wav2Vec2` 的代码:
|
||||
```python
|
||||
from transformers import pipeline
|
||||
p = pipeline("automatic-speech-recognition")
|
||||
```
|
||||
|
||||
就是这样!默认情况下,自动语音识别模型管道会加载 Facebook 的 `facebook/wav2vec2-base-960h` 模型。
|
||||
|
||||
## 2. 使用 Transformers 创建一个全文 ASR 演示
|
||||
我们将首先创建一个*全文*ASR 演示,其中用户在使用 ASR 模型进行预测之前说完整段音频。使用 Gradio 非常简单,我们只需在上面的 `pipeline` 对象周围创建一个函数。
|
||||
|
||||
我们将使用 `gradio` 内置的 `Audio` 组件,配置从用户的麦克风接收输入并返回录制音频的文件路径。输出组件将是一个简单的 `Textbox`。
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
def transcribe(audio):
|
||||
text = p(audio)["text"]
|
||||
return text
|
||||
|
||||
gr.Interface(
|
||||
fn=transcribe,
|
||||
inputs=gr.Audio(source="microphone", type="filepath"),
|
||||
outputs="text").launch()
|
||||
```
|
||||
|
||||
那么这里发生了什么?`transcribe` 函数接受一个参数 `audio`,它是用户录制的音频文件的文件路径。`pipeline` 对象期望一个文件路径,并将其转换为文本,然后返回到前端并在文本框中显示。
|
||||
|
||||
让我们看看它的效果吧!(录制一段短音频并点击提交,或[在新标签页打开](https://huggingface.co/spaces/abidlabs/full-context-asr)):
|
||||
<iframe src="https://abidlabs-full-context-asr.hf.space" frameBorder="0" height="350" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
## 3. 使用 Transformers 创建一个流式 ASR 演示
|
||||
太棒了!我们已经构建了一个对短音频剪辑效果良好的 ASR 模型。但是,如果您正在记录较长的音频剪辑,则可能需要一个*流式*界面,即在用户说话时逐句转录音频,而不仅仅在最后一次全部转录。
|
||||
|
||||
好消息是,我们可以很容易地调整刚刚创建的演示,使其成为流式的,使用相同的 `Wav2Vec2` 模型。
|
||||
|
||||
最大的变化是我们现在必须引入一个 `state` 参数,它保存到目前为止*转录的音频*。这样,我们只需处理最新的音频块,并将其简单地追加到先前转录的音频中。
|
||||
|
||||
在向 Gradio 演示添加状态时,您需要完成 3 件事:
|
||||
* 在函数中添加 `state` 参数* 在函数末尾返回更新后的 `state`* 在 `Interface` 的 `inputs` 和 `outputs` 中添加 `"state"` 组件
|
||||
|
||||
以下是代码示例:
|
||||
```python
|
||||
def transcribe(audio, state=""):
|
||||
text = p(audio)["text"]
|
||||
state += text + " "
|
||||
return state, state
|
||||
|
||||
# Set the starting state to an empty string
|
||||
gr.Interface(
|
||||
fn=transcribe,
|
||||
inputs=[
|
||||
gr.Audio(source="microphone", type="filepath", streaming=True),
|
||||
"state"
|
||||
],
|
||||
outputs=[
|
||||
"textbox",
|
||||
"state"
|
||||
],
|
||||
live=True).launch()
|
||||
```
|
||||
|
||||
请注意,我们还进行了另一个更改,即我们设置了 `live=True`。这使得 Gradio 接口保持持续运行,因此它可以自动转录音频,而无需用户反复点击提交按钮。
|
||||
|
||||
让我们看看它的效果(在下方尝试或[在新标签页中打开](https://huggingface.co/spaces/abidlabs/streaming-asr))!
|
||||
|
||||
<iframe src="https://abidlabs-streaming-asr.hf.space" frameBorder="0" height="350" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
你可能注意到的一件事是,由于音频块非常小,所以转录质量下降了,它们缺乏正确转录所需的上下文。此问题的“hacky”解决方法是简单地增加 `transcribe()` 函数的运行时间,以便处理更长的音频块。我们可以通过在函数中添加 `time.sleep()` 来实现这一点,如下所示(接下来我们将看到一个正确的解决方法)
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
import gradio as gr
|
||||
import time
|
||||
|
||||
p = pipeline("automatic-speech-recognition")
|
||||
|
||||
def transcribe(audio, state=""):
|
||||
time.sleep(2)
|
||||
text = p(audio)["text"]
|
||||
state += text + " "
|
||||
return state, state
|
||||
|
||||
gr.Interface(
|
||||
fn=transcribe,
|
||||
inputs=[
|
||||
gr.Audio(source="microphone", type="filepath", streaming=True),
|
||||
"state"
|
||||
],
|
||||
outputs=[
|
||||
"textbox",
|
||||
"state"
|
||||
],
|
||||
live=True).launch()
|
||||
```
|
||||
|
||||
尝试下面的演示,查看差异(或[在新标签页中打开](https://huggingface.co/spaces/abidlabs/streaming-asr-paused))!
|
||||
|
||||
<iframe src="https://abidlabs-streaming-asr-paused.hf.space" frameBorder="0" height="350" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
|
||||
|
||||
## 4. 使用 DeepSpeech 创建流式 ASR 演示
|
||||
|
||||
您不仅限于使用 `transformers` 库中的 ASR 模型 - 您可以使用自己的模型或其他库中的模型。`DeepSpeech` 库包含专门用于处理流式音频数据的模型。这些模型在处理流式数据时表现非常好,因为它们能够考虑到先前的音频块在进行预测时产生的影响。
|
||||
|
||||
深入研究 DeepSpeech 库超出了本指南的范围(可以在[此处查看其优秀的文档](https://deepspeech.readthedocs.io/en/r0.9/)),但是您可以像使用 Transformer ASR 模型一样,使用 DeepSpeech ASR 模型使用类似的方法使用 Gradio。
|
||||
|
||||
下面是一个完整的示例(在 Linux 上):
|
||||
|
||||
首先通过终端安装 DeepSpeech 库并下载预训练模型:
|
||||
|
||||
```bash
|
||||
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-models.pbmm
|
||||
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-models.scorer
|
||||
apt install libasound2-dev portaudio19-dev libportaudio2 libportaudiocpp0 ffmpeg
|
||||
pip install deepspeech==0.8.2
|
||||
```
|
||||
|
||||
然后,创建与之前相似的 `transcribe()` 函数:
|
||||
|
||||
```python
|
||||
from deepspeech import Model
|
||||
import numpy as np
|
||||
|
||||
model_file_path = "deepspeech-0.8.2-models.pbmm"
|
||||
lm_file_path = "deepspeech-0.8.2-models.scorer"
|
||||
beam_width = 100
|
||||
lm_alpha = 0.93
|
||||
lm_beta = 1.18
|
||||
|
||||
model = Model(model_file_path)
|
||||
model.enableExternalScorer(lm_file_path)
|
||||
model.setScorerAlphaBeta(lm_alpha, lm_beta)
|
||||
model.setBeamWidth(beam_width)
|
||||
|
||||
|
||||
def reformat_freq(sr, y):
|
||||
if sr not in (
|
||||
48000,
|
||||
16000,
|
||||
): # Deepspeech only supports 16k, (we convert 48k -> 16k)
|
||||
raise ValueError("Unsupported rate", sr)
|
||||
if sr == 48000:
|
||||
y = (
|
||||
((y / max(np.max(y), 1)) * 32767)
|
||||
.reshape((-1, 3))
|
||||
.mean(axis=1)
|
||||
.astype("int16")
|
||||
)
|
||||
sr = 16000
|
||||
return sr, y
|
||||
|
||||
|
||||
def transcribe(speech, stream):
|
||||
_, y = reformat_freq(*speech)
|
||||
if stream is None:
|
||||
stream = model.createStream()
|
||||
stream.feedAudioContent(y)
|
||||
text = stream.intermediateDecode()
|
||||
return text, stream
|
||||
|
||||
```
|
||||
|
||||
然后,如前所述创建一个 Gradio 接口(唯一的区别是返回类型应该是 `numpy` 而不是 `filepath` 以与 DeepSpeech 模型兼容)
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.Interface(
|
||||
fn=transcribe,
|
||||
inputs=[
|
||||
gr.Audio(source="microphone", type="numpy"),
|
||||
"state"
|
||||
],
|
||||
outputs= [
|
||||
"text",
|
||||
"state"
|
||||
],
|
||||
live=True).launch()
|
||||
```
|
||||
|
||||
运行所有这些应该允许您使用一个漂亮的 GUI 部署实时 ASR 模型。尝试一下,看它在您那里运行得有多好。
|
||||
|
||||
--------------------------------------------
|
||||
|
||||
你已经完成了!这就是构建用于 ASR 模型的基于 Web 的 GUI 所需的所有代码。
|
||||
|
||||
有趣的提示:您只需在 `launch()` 中设置 `share=True`,即可即时与他人共享 ASR 模型。
|
||||
151
guides/cn/07_other-tutorials/running-background-tasks.md
Normal file
@ -0,0 +1,151 @@
|
||||
# 运行后台任务
|
||||
|
||||
Related spaces: https://huggingface.co/spaces/freddyaboulton/gradio-google-forms
|
||||
Tags: TASKS, SCHEDULED, TABULAR, DATA
|
||||
|
||||
## 简介
|
||||
|
||||
本指南介绍了如何从 gradio 应用程序中运行后台任务。
|
||||
后台任务是在您的应用程序的请求-响应生命周期之外执行的操作,可以是一次性的或定期的。
|
||||
后台任务的示例包括定期将数据与外部数据库同步或通过电子邮件发送模型预测报告。
|
||||
|
||||
## 概述
|
||||
|
||||
我们将创建一个简单的“Google Forms”风格的应用程序,用于收集 gradio 库的用户反馈。
|
||||
我们将使用一个本地 sqlite 数据库来存储数据,但我们将定期将数据库的状态与[HuggingFace Dataset](https://huggingface.co/datasets)同步,以便始终备份我们的用户评论。
|
||||
同步将在每 60 秒运行的后台任务中进行。
|
||||
|
||||
在演示结束时,您将拥有一个完全可工作的应用程序,类似于以下应用程序 :
|
||||
|
||||
<gradio-app space="freddyaboulton/gradio-google-forms"> </gradio-app>
|
||||
|
||||
## 第一步 - 编写数据库逻辑 💾
|
||||
我们的应用程序将存储评论者的姓名,他们对 gradio 给出的评分(1 到 5 的范围),以及他们想要分享的关于该库的任何评论。让我们编写一些代码,创建一个数据库表来存储这些数据。我们还将编写一些函数,以将评论插入该表中并获取最新的 10 条评论。
|
||||
|
||||
我们将使用 `sqlite3` 库来连接我们的 sqlite 数据库,但 gradio 可以与任何库一起使用。
|
||||
|
||||
代码如下 :
|
||||
|
||||
```python
|
||||
DB_FILE = "./reviews.db"
|
||||
db = sqlite3.connect(DB_FILE)
|
||||
|
||||
# Create table if it doesn't already exist
|
||||
try:
|
||||
db.execute("SELECT * FROM reviews").fetchall()
|
||||
db.close()
|
||||
except sqlite3.OperationalError:
|
||||
db.execute(
|
||||
'''
|
||||
CREATE TABLE reviews (id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
|
||||
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
|
||||
name TEXT, review INTEGER, comments TEXT)
|
||||
''')
|
||||
db.commit()
|
||||
db.close()
|
||||
|
||||
def get_latest_reviews(db: sqlite3.Connection):
|
||||
reviews = db.execute("SELECT * FROM reviews ORDER BY id DESC limit 10").fetchall()
|
||||
total_reviews = db.execute("Select COUNT(id) from reviews").fetchone()[0]
|
||||
reviews = pd.DataFrame(reviews, columns=["id", "date_created", "name", "review", "comments"])
|
||||
return reviews, total_reviews
|
||||
|
||||
|
||||
def add_review(name: str, review: int, comments: str):
|
||||
db = sqlite3.connect(DB_FILE)
|
||||
cursor = db.cursor()
|
||||
cursor.execute("INSERT INTO reviews(name, review, comments) VALUES(?,?,?)", [name, review, comments])
|
||||
db.commit()
|
||||
reviews, total_reviews = get_latest_reviews(db)
|
||||
db.close()
|
||||
return reviews, total_reviews
|
||||
```
|
||||
|
||||
让我们还写一个函数,在 gradio 应用程序加载时加载最新的评论 :
|
||||
|
||||
```python
|
||||
def load_data():
|
||||
db = sqlite3.connect(DB_FILE)
|
||||
reviews, total_reviews = get_latest_reviews(db)
|
||||
db.close()
|
||||
return reviews, total_reviews
|
||||
```
|
||||
|
||||
## 第二步 - 创建 gradio 应用 ⚡
|
||||
现在我们已经定义了数据库逻辑,我们可以使用 gradio 创建一个动态的网页来询问用户的反馈意见!
|
||||
|
||||
使用以下代码段 :
|
||||
|
||||
```python
|
||||
with gr.Blocks() as demo:
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
name = gr.Textbox(label="Name", placeholder="What is your name?")
|
||||
review = gr.Radio(label="How satisfied are you with using gradio?", choices=[1, 2, 3, 4, 5])
|
||||
comments = gr.Textbox(label="Comments", lines=10, placeholder="Do you have any feedback on gradio?")
|
||||
submit = gr.Button(value="Submit Feedback")
|
||||
with gr.Column():
|
||||
data = gr.Dataframe(label="Most recently created 10 rows")
|
||||
count = gr.Number(label="Total number of reviews")
|
||||
submit.click(add_review, [name, review, comments], [data, count])
|
||||
demo.load(load_data, None, [data, count])
|
||||
```
|
||||
|
||||
## 第三步 - 与 HuggingFace 数据集同步 🤗
|
||||
|
||||
在第 2 步后我们可以调用 `demo.launch()` 来运行一个完整功能的应用程序。然而,我们的数据将存储在本地机器上。如果 sqlite 文件意外删除,我们将丢失所有评论!让我们将我们的数据备份到 HuggingFace hub 的数据集中。
|
||||
|
||||
在继续之前,请在[此处](https://huggingface.co/datasets)创建一个数据集。
|
||||
|
||||
现在,在我们脚本的**顶部**,我们将使用[huggingface hub 客户端库](https://huggingface.co/docs/huggingface_hub/index)连接到我们的数据集并获取最新的备份。
|
||||
```python
|
||||
TOKEN = os.environ.get('HUB_TOKEN')
|
||||
repo = huggingface_hub.Repository(
|
||||
local_dir="data",
|
||||
repo_type="dataset",
|
||||
clone_from="<name-of-your-dataset>",
|
||||
use_auth_token=TOKEN
|
||||
)
|
||||
repo.git_pull()
|
||||
|
||||
shutil.copyfile("./data/reviews.db", DB_FILE)
|
||||
```
|
||||
|
||||
请注意,您需要从 HuggingFace 的“设置”选项卡中获取访问令牌,以上代码才能正常工作。在脚本中,通过环境变量安全访问令牌。
|
||||
|
||||

|
||||
|
||||
现在,我们将创建一个后台任务,每 60 秒将我们的本地数据库与数据集中的数据同步一次。
|
||||
我们将使用[AdvancedPythonScheduler](https://apscheduler.readthedocs.io/en/3.x/)来处理调度。
|
||||
然而,这并不是唯一可用的任务调度库。请随意使用您熟悉的任何库。
|
||||
|
||||
备份数据的函数如下 :
|
||||
```python
|
||||
from apscheduler.schedulers.background import BackgroundScheduler
|
||||
|
||||
def backup_db():
|
||||
shutil.copyfile(DB_FILE, "./data/reviews.db")
|
||||
db = sqlite3.connect(DB_FILE)
|
||||
reviews = db.execute("SELECT * FROM reviews").fetchall()
|
||||
pd.DataFrame(reviews).to_csv("./data/reviews.csv", index=False)
|
||||
print("updating db")
|
||||
repo.push_to_hub(blocking=False, commit_message=f"Updating data at {datetime.datetime.now()}")
|
||||
|
||||
|
||||
scheduler = BackgroundScheduler()
|
||||
scheduler.add_job(func=backup_db, trigger="interval", seconds=60)
|
||||
scheduler.start()
|
||||
```
|
||||
|
||||
## 第四步(附加)- 部署到 HuggingFace Spaces
|
||||
|
||||
您可以使用 HuggingFace [Spaces](https://huggingface.co/spaces) 平台免费部署这个应用程序 ✨
|
||||
|
||||
如果您之前没有使用过 Spaces,请查看[此处](/using_hugging_face_integrations)的先前指南。
|
||||
您将需要将 `HUB_TOKEN` 环境变量作为指南中的一个秘密使用。
|
||||
|
||||
## 结论
|
||||
恭喜!您知道如何在您的 gradio 应用程序中按计划运行后台任务⏲️。
|
||||
|
||||
在 Spaces 上运行的应用程序可在[此处](https://huggingface.co/spaces/freddyaboulton/gradio-google-forms)查看。
|
||||
完整的代码在[此处](https://huggingface.co/spaces/freddyaboulton/gradio-google-forms/blob/main/app.py)。
|
||||
@ -0,0 +1,77 @@
|
||||
# 在 Web 服务器上使用 Nginx 运行 Gradio 应用
|
||||
标签:部署,Web 服务器,Nginx
|
||||
|
||||
## 介绍
|
||||
|
||||
Gradio 是一个 Python 库,允许您快速创建可定制的 Web 应用程序,用于机器学习模型和数据处理流水线。Gradio 应用可以免费部署在[Hugging Face Spaces](https://hf.space)上。
|
||||
|
||||
然而,在某些情况下,您可能希望在自己的 Web 服务器上部署 Gradio 应用。您可能已经在使用[Nginx](https://www.nginx.com/)作为高性能的 Web 服务器来提供您的网站(例如 `https://www.example.com`),并且您希望将 Gradio 附加到网站的特定子路径上(例如 `https://www.example.com/gradio-demo`)。
|
||||
|
||||
在本指南中,我们将指导您在自己的 Web 服务器上的 Nginx 后面运行 Gradio 应用的过程,以实现此目的。
|
||||
|
||||
**先决条件**
|
||||
|
||||
1. 安装了 [Nginx 的 Linux Web 服务器](https://www.nginx.com/blog/setting-up-nginx/) 和 [Gradio](/quickstart) 库
|
||||
|
||||
2. 在 Web 服务器上将 Gradio 应用保存为 Python 文件
|
||||
|
||||
## 编辑 Nginx 配置文件
|
||||
|
||||
1. 首先编辑 Web 服务器上的 Nginx 配置文件。默认情况下,文件位于:`/etc/nginx/nginx.conf`
|
||||
|
||||
在 `http` 块中,添加以下行以从单独的文件包含服务器块配置:
|
||||
|
||||
```bash
|
||||
include /etc/nginx/sites-enabled/*;
|
||||
```
|
||||
|
||||
2. 在 `/etc/nginx/sites-available` 目录中创建一个新文件(如果目录不存在则创建),文件名表示您的应用,例如:`sudo nano /etc/nginx/sites-available/my_gradio_app`
|
||||
|
||||
3. 将以下内容粘贴到文件编辑器中:
|
||||
|
||||
```bash
|
||||
server {
|
||||
listen 80;
|
||||
server_name example.com www.example.com; # 将此项更改为您的域名
|
||||
|
||||
location /gradio-demo/ { # 如果要在不同路径上提供Gradio应用,请更改此项
|
||||
proxy_pass http://127.0.0.1:7860/; # 如果您的Gradio应用将在不同端口上运行,请更改此项
|
||||
proxy_redirect off;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_set_header Host $host;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 在 Web 服务器上运行 Gradio 应用
|
||||
|
||||
1. 在启动 Gradio 应用之前,您需要将 `root_path` 设置为与 Nginx 配置中指定的子路径相同。这对于 Gradio 在除域的根路径之外的任何子路径上运行是必要的。
|
||||
|
||||
以下是一个具有自定义 `root_path` 的简单示例 Gradio 应用:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
import time
|
||||
|
||||
def test(x):
|
||||
time.sleep(4)
|
||||
return x
|
||||
|
||||
gr.Interface(test, "textbox", "textbox").queue().launch(root_path="/gradio-demo")
|
||||
```
|
||||
|
||||
2. 通过键入 `tmux` 并按回车键(可选)启动 `tmux` 会话
|
||||
|
||||
推荐在 `tmux` 会话中运行 Gradio 应用,以便可以轻松地在后台运行它
|
||||
|
||||
3. 然后,启动您的 Gradio 应用。只需输入 `python`,后跟您的 Gradio Python 文件的名称。默认情况下,应用将在 `localhost:7860` 上运行,但如果它在其他端口上启动,您需要更新上面的 Nginx 配置文件。
|
||||
|
||||
## 重新启动 Nginx
|
||||
|
||||
1. 如果您在 tmux 会话中,请通过键入 CTRL + B(或 CMD + B),然后按下 "D" 键来退出。
|
||||
|
||||
2. 最后,通过运行 `sudo systemctl restart nginx` 重新启动 nginx。
|
||||
|
||||
就是这样!如果您在浏览器中访问 `https://example.com/gradio-demo`,您应该能够看到您的 Gradio 应用在那里运行。
|
||||
@ -0,0 +1,109 @@
|
||||
# 最佳性能的演示 (Maximum Performance)
|
||||
|
||||
Tags: QUEUE, PERFORMANCE
|
||||
|
||||
假设您的 Gradio 演示在社交媒体上迅速走红-有很多用户同时尝试,您希望为用户提供最佳体验,换句话说就是尽量减少每个用户等待队列中查看他们的预测结果的时间。
|
||||
|
||||
如何配置您的 Gradio 演示以处理最大流量?在本指南中,我们将深入介绍 Gradio 的 `.queue()` 方法以及其他相关配置的一些参数,并讨论如何设置这些参数,以便您可以同时为大量用户提供服务,并使延迟保持最小。
|
||||
|
||||
这是一份高级指南,请确保您已经了解 Gradio 的基础知识,例如[如何创建和启动 Gradio 界面](https://gradio.app/quickstart/)。本指南中的大部分信息对于您是将演示托管在[Hugging Face Spaces](https://hf.space)还是在自己的服务器上都是相关的。
|
||||
|
||||
## 启用 Gradio 的队列系统
|
||||
|
||||
默认情况下,Gradio 演示不使用队列,而是通过 POST 请求将预测请求发送到托管 Gradio 服务器和 Python 代码的服务器。然而,常规 POST 请求有两个重要的限制:
|
||||
|
||||
(1) 它们会超时-大多数浏览器在 POST 请求在很短的时间(例如 1 分钟)内没有响应时会引发超时错误。
|
||||
如果推理功能运行时间超过 1 分钟,或者当同时有很多人尝试您的演示时,增加了延迟。
|
||||
|
||||
(2) 它们不允许 Gradio 演示和 Gradio 服务器之间的双向通信。这意味着,例如,您无法实时获得您的预测完成所需的预计时间。
|
||||
|
||||
为了解决这些限制,任何 Gradio 应用都可以通过在 Interface 或 Blocks 启动之前添加 `.queue()` 来转换为使用 **websockets**。以下是一个示例:
|
||||
|
||||
```py
|
||||
app = gr.Interface(lambda x:x, "image", "image")
|
||||
app.queue() # <-- Sets up a queue with default parameters
|
||||
app.launch()
|
||||
```
|
||||
在上面的演示 `app` 中,预测现在将通过 websocket 发送。
|
||||
与 POST 请求不同,websocket 不会超时并且允许双向通信。在 Gradio 服务器上,设置了一个 **queue 队列**,它将每个到达的请求添加到列表中。当一个工作线程可用时,第一个可用的请求将传递给工作线程用于预测。预测完成后,队列通过 websocket 将预测结果发送回调用该预测的特定 Gradio 用户。
|
||||
|
||||
注意:如果您将 Gradio 应用程序托管在[Hugging Face Spaces](https://hf.space),队列已经 **enabled by default 默认启用**。您仍然可以手动调用 `.queue()` 方法以配置下面描述的队列参数。
|
||||
|
||||
## 队列参数 (Queuing Parameters)
|
||||
|
||||
有几个参数可用于配置队列,并帮助减少延迟。让我们逐个介绍。
|
||||
|
||||
### `concurrency_count` 参数
|
||||
|
||||
我们将首先探讨 `queue()` 的 `concurrency_count` 参数。该参数用于设置在 Gradio 服务器中将并行处理请求的工作线程数。默认情况下,此参数设置为 `1`,但增加此参数可以**线性增加服务器处理请求的能力**。
|
||||
|
||||
那为什么不将此参数设置得更高呢?请记住,由于请求是并行处理的,每个请求将消耗内存用于存储处理的数据和权重。这意味着,如果您将 `concurrency_count` 设置得过高,可能会导致内存溢出错误。如果 `concurrency_count` 过高,也可能出现不断切换不同工作线程的成本导致收益递减的情况。
|
||||
|
||||
**推荐**:将 `concurrency_count` 参数增加到能够获得性能提升或达到机器内存限制为止。您可以[在此处了解有关 Hugging Face Spaces 机器规格的信息](https://huggingface.co/docs/hub/spaces-overview)。
|
||||
|
||||
*注*:还有第二个参数可控制 Gradio 能够生成的*总*线程数,无论是否启用队列。这是 `launch()` 方法中的 `max_threads` 参数。当您增加 `queue()` 中的 `concurrency_count` 参数时,此参数也会自动增加。然而,在某些情况下,您可能希望手动增加此参数,例如,如果未启用队列。
|
||||
|
||||
### `max_size` 参数
|
||||
|
||||
减少等待时间的更直接的方法是防止过多的人加入队列。您可以使用 `queue()` 的 `max_size` 参数设置队列处理的最大请求数。如果请求在队列已经达到最大大小时到达,它将被拒绝加入队列,并且用户将收到一个错误提示,指示队列已满,请重试。默认情况下,`max_size=None`,表示没有限制可以加入队列的用户数量。
|
||||
|
||||
矛盾地,设置 `max_size` 通常可以改善用户体验,因为它可以防止用户因等待时间过长而被打消兴趣。对您的演示更感兴趣和投入的用户将继续尝试加入队列,并且能够更快地获得他们的结果。
|
||||
|
||||
**推荐**:为了获得更好的用户体验,请设置一个合理的 `max_size`,该值基于用户对预测所愿意等待多长时间的预期。
|
||||
|
||||
### `max_batch_size` 参数
|
||||
|
||||
增加 Gradio 演示的并行性的另一种方法是编写能够接受**批次**输入的函数。大多数深度学习模型可以比处理单个样本更高效地处理批次样本。
|
||||
|
||||
如果您编写的函数可以处理一批样本,Gradio 将自动将传入的请求批量处理并作为批量样本传递给您的函数。您需要将 `batch` 设置为 `True`(默认为 `False`),并根据函数能够处理的最大样本数设置 `max_batch_size`(默认为 `4`)。这两个参数可以传递给 `gr.Interface()` 或 Blocks 中的事件,例如 `.click()`。
|
||||
|
||||
虽然设置批次在概念上与使工作线程并行处理请求类似,但对于深度学习模型而言,它通常比设置 `concurrency_count` 更快。缺点是您可能需要稍微调整函数以接受批次样本而不是单个样本。
|
||||
|
||||
以下是一个不接受批次输入的函数的示例-它一次处理一个输入:
|
||||
|
||||
```py
|
||||
import time
|
||||
|
||||
def trim_words(word, length):
|
||||
return w[:int(length)]
|
||||
|
||||
```
|
||||
|
||||
这是相同函数的重写版本,接受一批样本:
|
||||
|
||||
```py
|
||||
import time
|
||||
|
||||
def trim_words(words, lengths):
|
||||
trimmed_words = []
|
||||
for w, l in zip(words, lengths):
|
||||
trimmed_words.append(w[:int(l)])
|
||||
return [trimmed_words]
|
||||
|
||||
```
|
||||
|
||||
# Setup 安装和设置
|
||||
|
||||
**建议**:如果可能的话,请编写接受样本批次的函数,然后将 `batch` 设置为 `True`,并根据计算机的内存限制将 `max_batch_size` 设置得尽可能高。如果将 `max_batch_size` 设置为尽可能高,很可能需要将 `concurrency_count` 重新设置为 `1`,因为您将没有足够的内存来同时运行多个工作线程。
|
||||
|
||||
### `api_open` 参数
|
||||
|
||||
在创建 Gradio 演示时,您可能希望将所有流量限制为通过用户界面而不是通过自动为您的 Gradio 演示创建的[编程 API](/sharing_your_app/#api-page)进行。这一点很重要,因为当人们通过编程 API 进行请求时,可能会绕过正在等待队列中的用户并降低这些用户的体验。
|
||||
|
||||
**建议**:在演示中将 `queue()` 中的 `api_open` 参数设置为 `False`,以防止程序化请求。
|
||||
|
||||
### 升级硬件(GPU,TPU 等)
|
||||
|
||||
如果您已经完成了以上所有步骤,但您的演示仍然不够快,您可以升级模型运行的硬件。将模型从 CPU 上运行切换到 GPU 上运行,深度学习模型的推理时间通常会提高 10 倍到 50 倍。
|
||||
|
||||
在 Hugging Face Spaces 上升级硬件非常简单。只需单击自己的 Space 中的 "Settings" 选项卡,然后选择所需的 Space 硬件。
|
||||
|
||||
|
||||
|
||||
虽然您可能需要调整部分机器学习推理代码以在 GPU 上运行(如果您使用 PyTorch,[这里有一个方便的指南](https://cnvrg.io/pytorch-cuda/)),但 Gradio 对于硬件选择是完全无感知的,无论您是使用 CPU、GPU、TPU 还是其他任何硬件,都可以正常工作!
|
||||
|
||||
注意:您的 GPU 内存与 CPU 内存不同,因此如果您升级了硬件,您可能需要调整上面描述的``concurrency_count`` 参数的值。
|
||||
|
||||
## 结论
|
||||
|
||||
祝贺您!您已经了解如何设置 Gradio 演示以获得最佳性能。祝您在下一个病毒式演示中好运!
|
||||
390
guides/cn/07_other-tutorials/theming-guide.md
Normal file
@ -0,0 +1,390 @@
|
||||
# 主题 Theming
|
||||
Tags: THEMES
|
||||
|
||||
## 介绍
|
||||
|
||||
Gradio 具有内置的主题引擎,可让您自定义应用的外观和感觉。您可以选择各种主题,或者创建自己的主题。要这样做,请将 `theme=` kwarg 传递给 `Blocks` 或 `Interface` 构造函数。例如:
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Soft()) as demo:
|
||||
...
|
||||
```
|
||||
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-soft.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
Gradio 带有一组预构建的主题,您可以从 `gr.themes.*` 中加载这些主题。这些主题包括:
|
||||
|
||||
* `gr.themes.Base()`
|
||||
* `gr.themes.Default()`
|
||||
* `gr.themes.Glass()`
|
||||
* `gr.themes.Monochrome()`
|
||||
* `gr.themes.Soft()`
|
||||
|
||||
这些主题为数百个 CSS 变量设置了值。您可以使用预构建的主题作为自定义主题的起点,也可以从头开始创建自己的主题。让我们看看每种方法。
|
||||
|
||||
## 使用主题构建器
|
||||
|
||||
使用主题构建器构建主题最简单。要在本地启动主题构建器,请运行以下代码:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
gr.themes.builder()
|
||||
```
|
||||
|
||||
$demo_theme_builder
|
||||
|
||||
您可以使用上面的 Spaces 上运行的 Theme Builder,但通过 `gr.themes.builder()` 在本地启动时运行速度更快。
|
||||
|
||||
在 Theme Builder 中编辑值时,应用程序将实时预览更新。您可以下载生成的主题代码,以便在任何 Gradio 应用程序中使用它。
|
||||
|
||||
在本指南的其余部分,我们将介绍如何以编程方式构建主题。
|
||||
|
||||
## 通过构造函数扩展主题
|
||||
|
||||
尽管每个主题都有数百个 CSS 变量,但大多数这些变量的值都是从 8 个核心变量中获取的,可以通过每个预构建主题的构造函数设置这些变量。通过修改这 8 个参数的值,您可以快速更改应用程序的外观和感觉。
|
||||
|
||||
### 核心颜色
|
||||
|
||||
前 3 个构造函数参数设置主题的颜色,并且是 `gradio.themes.Color` 对象。在内部,这些 Color 对象包含单个色调的调色板的亮度值,范围从 50,100,200...,800,900,950。其他 CSS 变量是从这 3 种颜色派生的。
|
||||
|
||||
3 个颜色构造函数参数是:
|
||||
|
||||
- `primary_hue`:这是主题中的主色。在默认主题中,此值设置为 `gradio.themes.colors.orange`。
|
||||
- `secondary_hue`:这是主题中用于辅助元素的颜色。在默认主题中,此值设置为 `gradio.themes.colors.blue`。
|
||||
- `neutral_hue`:这是主题中用于文本和其他中性元素的颜色。在默认主题中,此值设置为 `gradio.themes.colors.gray`。
|
||||
|
||||
您可以使用字符串快捷方式修改这些值,例如
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Default(primary_hue="red", secondary_hue="pink")) as demo:
|
||||
...
|
||||
```
|
||||
|
||||
或者直接使用 `Color` 对象,如下所示:
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Default(primary_hue=gr.themes.colors.red, secondary_hue=gr.themes.colors.pink)) as demo:
|
||||
...
|
||||
```
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-extended-step-1.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
预定义的颜色包括:
|
||||
|
||||
* `slate`
|
||||
* `gray`
|
||||
* `zinc`
|
||||
* `neutral`
|
||||
* `stone`
|
||||
* `red`
|
||||
* `orange`
|
||||
* `amber`
|
||||
* `yellow`
|
||||
* `lime`
|
||||
* `green`
|
||||
* `emerald`
|
||||
* `teal`
|
||||
* `cyan`
|
||||
* `sky`
|
||||
* `blue`
|
||||
* `indigo`
|
||||
* `violet`
|
||||
* `purple`
|
||||
* `fuchsia`
|
||||
* `pink`
|
||||
* `rose`
|
||||
|
||||
您还可以创建自己的自定义 `Color` 对象并传递它们。
|
||||
|
||||
### 核心大小 (Core Sizing)
|
||||
|
||||
接下来的 3 个构造函数参数设置主题的大小,并且是 `gradio.themes.Size` 对象。在内部,这些 Size 对象包含从 `xxs` 到 `xxl` 的像素大小值。其他 CSS 变量是从这 3 个大小派生的。
|
||||
|
||||
- `spacing_size`:此设置了元素内部的填充和元素之间的间距。在默认主题中,此值设置为 `gradio.themes.sizes.spacing_md`。
|
||||
- `radius_size`:此设置了元素的圆角弧度。在默认主题中,此值设置为 `gradio.themes.sizes.radius_md`。
|
||||
- `text_size`:此设置了文本的字体大小。在默认主题中,此值设置为 `gradio.themes.sizes.text_md`。
|
||||
|
||||
您可以使用字符串快捷方式修改这些值,例如
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Default(spacing_size="sm", radius_size="none")) as demo:
|
||||
...
|
||||
```
|
||||
|
||||
或者直接使用 `Size` 对象,如下所示:
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size=gr.themes.sizes.radius_none)) as demo:
|
||||
...
|
||||
```
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-extended-step-2.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
预定义的大小对象包括:
|
||||
|
||||
* `radius_none`
|
||||
* `radius_sm`
|
||||
* `radius_md`
|
||||
* `radius_lg`
|
||||
* `spacing_sm`
|
||||
* `spacing_md`
|
||||
* `spacing_lg`
|
||||
* `text_sm`
|
||||
* `text_md`
|
||||
* `text_lg`
|
||||
|
||||
您还可以创建自己的自定义 `Size` 对象并传递它们。
|
||||
|
||||
### 核心字体(Core Fonts)
|
||||
|
||||
最后的 2 个构造函数参数设置主题的字体。您可以将一系列字体传递给这些参数,以指定回退字体。如果提供了字符串,它将被加载为系统字体。如果提供了 `gradio.themes.GoogleFont`,则将从 Google Fonts 加载该字体。
|
||||
|
||||
- `font`:此设置主题的主要字体。在默认主题中,此值设置为 `gradio.themes.GoogleFont("Source Sans Pro")`。
|
||||
- `font_mono`:此设置主题的等宽字体。在默认主题中,此值设置为 `gradio.themes.GoogleFont("IBM Plex Mono")`。
|
||||
|
||||
您可以修改这些值,例如以下方式:
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme=gr.themes.Default(font=[gr.themes.GoogleFont("Inconsolata"), "Arial", "sans-serif"])) as demo:
|
||||
...
|
||||
```
|
||||
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-extended-step-3.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
## 通过 `.set()` 扩展主题
|
||||
|
||||
主题加载后,您还可以修改 CSS 变量的值。为此,请使用主题对象的 `.set()` 方法来访问 CSS 变量。例如:
|
||||
```python
|
||||
theme = gr.themes.Default(primary_hue="blue").set( loader_color="#FF0000", slider_color="#FF0000",)
|
||||
使用`gr.Blocks(theme=theme)`创建演示块 ...
|
||||
```
|
||||
|
||||
在上面的示例中,我们将 `loader_color` 和 `slider_color` 变量设置为`#FF0000`,尽管整体 `primary_color` 使用蓝色调色板。您可以以这种方式设置主题中定义的任何 CSS 变量。
|
||||
您的 IDE 类型提示应该帮助您导航这些变量。由于有很多 CSS 变量,让我们看一下这些变量的命名和组织方式。
|
||||
|
||||
### CSS 变量命名规范
|
||||
|
||||
CSS 变量名可能会变得很长,例如 `button_primary_background_fill_hover_dark`!但是它们遵循一种常见的命名约定,使得理解变量功能和查找您要查找的变量变得容易。变量名由下划线分隔,由以下组成:
|
||||
1. 目标元素,例如 `button`、`slider` 或 `block`。2. 目标元素类型或子元素,例如 `button_primary` 或 `block_label`。3. 属性,例如 `button_primary_background_fill` 或 `block_label_border_width`。4. 任何相关状态,例如 `button_primary_background_fill_hover`。5. 如果在暗模式中值不同,则使用后缀 `_dark`。例如,`input_border_color_focus_dark`。
|
||||
当然,许多 CSS 变量名都比这个短,例如 `table_border_color` 或 `input_shadow`。
|
||||
|
||||
### CSS 变量组织
|
||||
|
||||
虽然有数百个 CSS 变量,但并不需要为每个变量都指定单独的值。它们通过引用一组核心变量和彼此引用来获取值。这样做可以仅修改少量变量以改变整个主题的外观和感觉,同时也可以更精细地控制我们可能想要修改的个别元素。
|
||||
|
||||
#### 引用核心变量
|
||||
|
||||
要引用其中一个核心构造函数变量,请在变量名前加上星号。要引用核心颜色,请使用`*primary_`、`*secondary_` 或`*neutral_` 前缀,后跟亮度值。例如:
|
||||
```python
|
||||
theme = gr.themes.Default(primary_hue="blue").set(
|
||||
button_primary_background_fill="*primary_200",
|
||||
button_primary_background_fill_hover="*primary_300",
|
||||
)
|
||||
```
|
||||
|
||||
在上面的示例中,我们将 `button_primary_background_fill` 和 `button_primary_background_fill_hover` 变量分别设置为`*primary_200` 和`*primary_300`。这些变量将分别设置为蓝色主色调调色板的 200 和 300 亮度值。
|
||||
同样地,要引用核心大小,请使用`*spacing_`、`*radius_` 或`*text_` 前缀,后跟大小值。例如:
|
||||
```python
|
||||
theme = gr.themes.Default(radius_size="md").set(
|
||||
button_primary_border_radius="*radius_xl",
|
||||
)
|
||||
```
|
||||
在上面的示例中,我们将 `button_primary_border_radius` 变量设置为`*radius_xl`。此变量将设置为中等半径大小范围的 `xl` 设置。
|
||||
|
||||
#### 引用其他变量
|
||||
变量也可以引用彼此。例如,请看下面的示例:
|
||||
```python
|
||||
theme = gr.themes.Default().set(
|
||||
button_primary_background_fill="#FF0000",
|
||||
button_primary_background_fill_hover="#FF0000",
|
||||
button_primary_border="#FF0000",
|
||||
)
|
||||
```
|
||||
|
||||
将这些值设置为相同的颜色有点繁琐。相反,我们可以在 `button_primary_background_fill_hover` 和 `button_primary_border` 变量中使用`*` 前缀引用 `button_primary_background_fill` 变量。
|
||||
```python
|
||||
theme = gr.themes.Default().set(
|
||||
button_primary_background_fill="#FF0000",
|
||||
button_primary_background_fill_hover="*button_primary_background_fill",
|
||||
button_primary_border="*button_primary_background_fill",
|
||||
)
|
||||
```
|
||||
|
||||
现在,如果我们更改 `button_primary_background_fill` 变量,`button_primary_background_fill_hover` 和 `button_primary_border` 变量将自动更新。
|
||||
如果您打算共享主题,这将非常有用- 它使得修改主题变得容易,而无需更改每个变量。
|
||||
请注意,暗模式变量自动相互引用。例如:
|
||||
```python
|
||||
theme = gr.themes.Default().set(
|
||||
button_primary_background_fill="#FF0000",
|
||||
button_primary_background_fill_dark="#AAAAAA",
|
||||
button_primary_border="*button_primary_background_fill",
|
||||
button_primary_border_dark="*button_primary_background_fill_dark",
|
||||
)
|
||||
```
|
||||
|
||||
`button_primary_border_dark` 将从 `button_primary_background_fill_dark` 获取其值,因为暗模式总是使用变量的暗版本。
|
||||
## 创建一个完整的主题
|
||||
假设您想从头开始创建一个主题!我们将逐步进行 - 您还可以参考 gradio 源代码库中预构建主题的源代码,请看这里的示例:[Monochrome theme 的源代码](https://github.com/gradio-app/gradio/blob/main/gradio/themes/monochrome.py)
|
||||
我们的新主题类将继承自 `gradio.themes.Base`,这是一个设置了许多方便默认值的主题。让我们创建一个名为 Seafoam 的简单演示,以及使用它的简单应用程序。
|
||||
$code_theme_new_step_1
|
||||
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-new-step-1.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
Base 主题非常简洁,使用 `gr.themes.Blue` 作为其主要颜色-由于此原因,主按钮和加载动画都是蓝色的。让我们改变应用程序的默认核心参数。我们将覆盖构造函数并传递新的默认值给核心构造函数参数。
|
||||
我们将使用 `gr.themes.Emerald` 作为我们的主要颜色,并将次要和中性色调设置为 `gr.themes.Blue`。我们将使用 `text_lg` 使文本更大。我们将使用 `Quicksand` 作为我们的默认字体,从 Google Fonts 加载。
|
||||
$code_theme_new_step_2
|
||||
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-new-step-2.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
注意到主按钮和加载动画现在是绿色的了吗?这些 CSS 变量与 `primary_hue` 相关联。
|
||||
我们来直接修改主题。我们将调用 `set()` 方法来明确覆盖 CSS 变量值。我们可以使用任何 CSS 逻辑,并使用`*` 前缀引用我们的核心构造函数的参数。
|
||||
|
||||
$code_theme_new_step_3
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-new-step-3.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
看看我们的主题现在多么有趣!仅通过几个变量的更改,我们的主题完全改变了。
|
||||
|
||||
您可能会发现探索[其他预建主题的源代码](https://github.com/gradio-app/gradio/blob/main/gradio/themes)会很有帮助,以了解他们如何修改基本主题。您还可以使用浏览器的检查工具,选择 UI 中的元素并查看在样式面板中使用的 CSS 变量。
|
||||
|
||||
## 分享主题
|
||||
|
||||
在创建主题后,您可以将其上传到 HuggingFace Hub,让其他人查看、使用和构建主题!
|
||||
|
||||
### 上传主题
|
||||
有两种上传主题的方式,通过主题类实例或命令行。我们将使用之前创建的“seafoam”主题来介绍这两种方式。
|
||||
|
||||
* 通过类实例
|
||||
|
||||
每个主题实例都有一个名为“push_to_hub”的方法,我们可以使用它来将主题上传到 HuggingFace Hub。
|
||||
|
||||
```python
|
||||
seafoam.push_to_hub(repo_name="seafoam",
|
||||
version="0.0.1",
|
||||
hf_token="<token>")
|
||||
```
|
||||
|
||||
* 通过命令行
|
||||
|
||||
首先将主题保存到磁盘
|
||||
```python
|
||||
seafoam.dump(filename="seafoam.json")
|
||||
```
|
||||
|
||||
然后使用“upload_theme”命令:
|
||||
|
||||
```bash
|
||||
upload_theme\
|
||||
"seafoam.json"\
|
||||
"seafoam"\
|
||||
--version "0.0.1"\
|
||||
--hf_token "<token>"
|
||||
```
|
||||
|
||||
要上传主题,您必须拥有一个 HuggingFace 账户,并通过 `hf_token` 参数传递您的[访问令牌](https://huggingface.co/docs/huggingface_hub/quick-start#login)。
|
||||
但是,如果您通过[HuggingFace 命令行](https://huggingface.co/docs/huggingface_hub/quick-start#login)登录(与 `gradio` 一起安装),
|
||||
那么您可以省略 `hf_token` 参数。
|
||||
|
||||
`version` 参数允许您为主题指定一个有效的[语义版本](https://www.geeksforgeeks.org/introduction-semantic-versioning/)字符串。
|
||||
这样,您的用户就可以在他们的应用程序中指定要使用的主题版本。这还允许您发布主题更新而不必担心
|
||||
以前创建的应用程序的外观如何更改。`version` 参数是可选的。如果省略,下一个修订版本将自动应用。
|
||||
|
||||
### 主题预览
|
||||
|
||||
通过调用 `push_to_hub` 或 `upload_theme`,主题资源将存储在[HuggingFace 空间](https://huggingface.co/docs/hub/spaces-overview)中。
|
||||
|
||||
我们的 seafoam 主题的预览在这里:[seafoam 预览](https://huggingface.co/spaces/gradio/seafoam)。
|
||||
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-seafoam.hf.space?__theme=light"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
### 发现主题
|
||||
|
||||
[主题库](https://huggingface.co/spaces/gradio/theme-gallery)显示了所有公开的 gradio 主题。在发布主题之后,
|
||||
它将在几分钟后自动显示在主题库中。
|
||||
|
||||
您可以按照空间上点赞的数量以及按创建时间从最近到最近对主题进行排序,也可以在浅色和深色模式之间切换主题。
|
||||
|
||||
<div class="wrapper">
|
||||
<iframe
|
||||
src="https://gradio-theme-gallery.hf.space"
|
||||
frameborder="0"
|
||||
></iframe>
|
||||
</div>
|
||||
|
||||
### 下载
|
||||
要使用 Hub 中的主题,请在 `ThemeClass` 上使用 `from_hub` 方法,然后将其传递给您的应用程序:
|
||||
|
||||
```python
|
||||
my_theme = gr.Theme.from_hub("gradio/seafoam")
|
||||
|
||||
with gr.Blocks(theme=my_theme) as demo:
|
||||
....
|
||||
```
|
||||
|
||||
您也可以直接将主题字符串传递给 `Blocks` 或 `Interface`(`gr.Blocks(theme="gradio/seafoam")`)
|
||||
|
||||
您可以通过使用语义版本表达式将您的应用程序固定到上游主题版本。
|
||||
|
||||
例如,以下内容将确保我们从“seafoam”仓库中加载的主题位于 `0.0.1` 和 `0.1.0` 版本之间:
|
||||
|
||||
```python
|
||||
with gr.Blocks(theme="gradio/seafoam@>=0.0.1,<0.1.0") as demo:
|
||||
....
|
||||
```
|
||||
|
||||
享受创建自己的主题吧!如果您制作了一个自豪的主题,请将其上传到 Hub 与世界分享!
|
||||
如果在[Twitter](https://twitter.com/gradio)上标记我们,我们可以给您的主题一个宣传!
|
||||
|
||||
<style>
|
||||
.wrapper {
|
||||
position: relative;
|
||||
padding-bottom: 56.25%;
|
||||
padding-top: 25px;
|
||||
height: 0;
|
||||
}
|
||||
.wrapper iframe {
|
||||
position: absolute;
|
||||
top: 0;
|
||||
left: 0;
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
}
|
||||
</style>
|
||||
190
guides/cn/07_other-tutorials/using-flagging.md
Normal file
@ -0,0 +1,190 @@
|
||||
# 使用标记
|
||||
|
||||
相关空间:https://huggingface.co/spaces/gradio/calculator-flagging-crowdsourced, https://huggingface.co/spaces/gradio/calculator-flagging-options, https://huggingface.co/spaces/gradio/calculator-flag-basic
|
||||
标签:标记,数据
|
||||
|
||||
## 简介
|
||||
|
||||
当您演示一个机器学习模型时,您可能希望收集试用模型的用户的数据,特别是模型行为不如预期的数据点。捕获这些“困难”数据点是有价值的,因为它允许您改进机器学习模型并使其更可靠和稳健。
|
||||
|
||||
Gradio 通过在每个“界面”中包含一个**标记**按钮来简化这些数据的收集。这使得用户或测试人员可以轻松地将数据发送回运行演示的机器。样本会保存在一个 CSV 日志文件中(默认情况下)。如果演示涉及图像、音频、视频或其他类型的文件,则这些文件会单独保存在一个并行目录中,并且这些文件的路径会保存在 CSV 文件中。
|
||||
|
||||
## 在 `gradio.Interface` 中使用**标记**按钮
|
||||
|
||||
使用 Gradio 的 `Interface` 进行标记特别简单。默认情况下,在输出组件下方有一个标记为**标记**的按钮。当用户测试您的模型时,如果看到有趣的输出,他们可以点击标记按钮将输入和输出数据发送回运行演示的机器。样本会保存在一个 CSV 日志文件中(默认情况下)。如果演示涉及图像、音频、视频或其他类型的文件,则这些文件会单独保存在一个并行目录中,并且这些文件的路径会保存在 CSV 文件中。
|
||||
|
||||
在 `gradio.Interface` 中有[四个参数](https://gradio.app/docs/#interface-header)控制标记的工作方式。我们将详细介绍它们。
|
||||
|
||||
* `allow_flagging`:此参数可以设置为 `"manual"`(默认值),`"auto"` 或 `"never"`。
|
||||
* `manual`:用户将看到一个标记按钮,只有在点击按钮时样本才会被标记。
|
||||
* `auto`:用户将不会看到一个标记按钮,但每个样本都会自动被标记。
|
||||
* `never`:用户将不会看到一个标记按钮,并且不会标记任何样本。
|
||||
* `flagging_options`:此参数可以是 `None`(默认值)或字符串列表。
|
||||
* 如果是 `None`,则用户只需点击**标记**按钮,不会显示其他选项。
|
||||
* 如果提供了一个字符串列表,则用户会看到多个按钮,对应于提供的每个字符串。例如,如果此参数的值为`[" 错误 ", " 模糊 "]`,则会显示标记为**标记为错误**和**标记为模糊**的按钮。这仅适用于 `allow_flagging` 为 `"manual"` 的情况。
|
||||
* 所选选项将与输入和输出一起记录。
|
||||
* `flagging_dir`:此参数接受一个字符串。
|
||||
* 它表示标记数据存储的目录名称。
|
||||
* `flagging_callback`:此参数接受 `FlaggingCallback` 类的子类的实例
|
||||
* 使用此参数允许您编写在点击标记按钮时运行的自定义代码
|
||||
* 默认情况下,它设置为 `gr.CSVLogger` 的一个实例
|
||||
* 一个示例是将其设置为 `gr.HuggingFaceDatasetSaver` 的一个实例,这样您可以将任何标记的数据导入到 HuggingFace 数据集中(参见下文)。
|
||||
|
||||
## 标记的数据会发生什么?
|
||||
|
||||
在 `flagging_dir` 参数提供的目录中,将记录标记的数据的 CSV 文件。
|
||||
|
||||
以下是一个示例:下面的代码创建了嵌入其中的计算器界面:
|
||||
|
||||
```python
|
||||
import gradio as gr
|
||||
|
||||
|
||||
def calculator(num1, operation, num2):
|
||||
if operation == "add":
|
||||
return num1 + num2
|
||||
elif operation == "subtract":
|
||||
return num1 - num2
|
||||
elif operation == "multiply":
|
||||
return num1 * num2
|
||||
elif operation == "divide":
|
||||
return num1 / num2
|
||||
|
||||
|
||||
iface = gr.Interface(
|
||||
calculator,
|
||||
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
|
||||
"number",
|
||||
allow_flagging="manual"
|
||||
)
|
||||
|
||||
iface.launch()
|
||||
```
|
||||
|
||||
<gradio-app space="gradio/calculator-flag-basic/"></gradio-app>
|
||||
|
||||
当您点击上面的标记按钮时,启动界面的目录将包括一个新的标记子文件夹,其中包含一个 CSV 文件。该 CSV 文件包括所有被标记的数据。
|
||||
|
||||
```directory
|
||||
+-- flagged/
|
||||
| +-- logs.csv
|
||||
```
|
||||
_flagged/logs.csv_
|
||||
```csv
|
||||
num1,operation,num2,Output,timestamp
|
||||
5,add,7,12,2022-01-31 11:40:51.093412
|
||||
6,subtract,1.5,4.5,2022-01-31 03:25:32.023542
|
||||
```
|
||||
|
||||
如果界面涉及文件数据,例如图像和音频组件,还将创建文件夹来存储这些标记的数据。例如,将 `image` 输入到 `image` 输出界面将创建以下结构。
|
||||
|
||||
```directory
|
||||
+-- flagged/
|
||||
| +-- logs.csv
|
||||
| +-- image/
|
||||
| | +-- 0.png
|
||||
| | +-- 1.png
|
||||
| +-- Output/
|
||||
| | +-- 0.png
|
||||
| | +-- 1.png
|
||||
```
|
||||
_flagged/logs.csv_
|
||||
```csv
|
||||
im,Output timestamp
|
||||
im/0.png,Output/0.png,2022-02-04 19:49:58.026963
|
||||
im/1.png,Output/1.png,2022-02-02 10:40:51.093412
|
||||
```
|
||||
|
||||
如果您希望用户为标记提供一个原因,您可以将字符串列表传递给 Interface 的 `flagging_options` 参数。用户在标记时必须选择其中一项,选项将作为附加列保存在 CSV 文件中。
|
||||
|
||||
如果我们回到计算器示例,下面的代码将创建嵌入其中的界面。
|
||||
```python
|
||||
iface = gr.Interface(
|
||||
calculator,
|
||||
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
|
||||
"number",
|
||||
allow_flagging="manual",
|
||||
flagging_options=["wrong sign", "off by one", "other"]
|
||||
)
|
||||
|
||||
iface.launch()
|
||||
```
|
||||
<gradio-app space="gradio/calculator-flagging-options/"></gradio-app>
|
||||
|
||||
当用户点击标记按钮时,CSV 文件现在将包括指示所选选项的列。
|
||||
|
||||
_flagged/logs.csv_
|
||||
```csv
|
||||
num1,operation,num2,Output,flag,timestamp
|
||||
5,add,7,-12,wrong sign,2022-02-04 11:40:51.093412
|
||||
6,subtract,1.5,3.5,off by one,2022-02-04 11:42:32.062512
|
||||
```
|
||||
|
||||
## HuggingFaceDatasetSaver 回调
|
||||
|
||||
有时,将数据保存到本地 CSV 文件是不合理的。例如,在 Hugging Face Spaces 上
|
||||
,开发者通常无法访问托管 Gradio 演示的底层临时机器。这就是为什么,默认情况下,在 Hugging Face Space 中关闭标记的原因。然而,
|
||||
您可能希望对标记的数据做其他处理。
|
||||
you may want to do something else with the flagged data.
|
||||
|
||||
通过 `flagging_callback` 参数,我们使这变得非常简单。
|
||||
|
||||
例如,下面我们将会将标记的数据从我们的计算器示例导入到 Hugging Face 数据集中,以便我们可以构建一个“众包”数据集:
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
HF_TOKEN = os.getenv('HF_TOKEN')
|
||||
hf_writer = gr.HuggingFaceDatasetSaver(HF_TOKEN, "crowdsourced-calculator-demo")
|
||||
|
||||
iface = gr.Interface(
|
||||
calculator,
|
||||
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
|
||||
"number",
|
||||
description="Check out the crowd-sourced dataset at: [https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo)",
|
||||
allow_flagging="manual",
|
||||
flagging_options=["wrong sign", "off by one", "other"],
|
||||
flagging_callback=hf_writer
|
||||
)
|
||||
|
||||
iface.launch()
|
||||
```
|
||||
|
||||
注意,我们使用我们的 Hugging Face 令牌和
|
||||
要保存样本的数据集的名称,定义了我们自己的
|
||||
`gradio.HuggingFaceDatasetSaver` 的实例。此外,我们还将 `allow_flagging="manual"` 设置为了
|
||||
,因为在 Hugging Face Spaces 中,`allow_flagging` 默认设置为 `"never"`。这是我们的演示:
|
||||
|
||||
<gradio-app space="gradio/calculator-flagging-crowdsourced/"></gradio-app>
|
||||
|
||||
您现在可以在这个[公共的 Hugging Face 数据集](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo)中看到上面标记的所有示例。
|
||||
|
||||

|
||||
|
||||
我们创建了 `gradio.HuggingFaceDatasetSaver` 类,但只要它继承自[此文件](https://github.com/gradio-app/gradio/blob/master/gradio/flagging.py)中定义的 `FlaggingCallback`,您可以传递自己的自定义类。如果您创建了一个很棒的回调,请将其贡献给该存储库!
|
||||
|
||||
## 使用 Blocks 进行标记
|
||||
|
||||
如果您正在使用 `gradio.Blocks`,又该怎么办呢?一方面,使用 Blocks 您拥有更多的灵活性
|
||||
--您可以编写任何您想在按钮被点击时运行的 Python 代码,
|
||||
并使用 Blocks 中的内置事件分配它。
|
||||
|
||||
同时,您可能希望使用现有的 `FlaggingCallback` 来避免编写额外的代码。
|
||||
这需要两个步骤:
|
||||
|
||||
1. 您必须在代码中的某个位置运行您的回调的 `.setup()` 方法
|
||||
在第一次标记数据之前
|
||||
2. 当点击标记按钮时,您触发回调的 `.flag()` 方法,
|
||||
确保正确收集参数并禁用通常的预处理。
|
||||
|
||||
下面是一个使用默认的 `CSVLogger` 标记图像怀旧滤镜 Blocks 演示的示例:
|
||||
data using the default `CSVLogger`:
|
||||
|
||||
$code_blocks_flag
|
||||
$demo_blocks_flag
|
||||
|
||||
## 隐私
|
||||
|
||||
重要提示:请确保用户了解他们提交的数据何时被保存以及您计划如何处理它。当您使用 `allow_flagging=auto`(当通过演示提交的所有数据都被标记时),这一点尤为重要
|
||||
|
||||
### 这就是全部!祝您建设愉快 :)
|
||||
30
guides/cn/CONTRIBUTING.md
Normal file
@ -0,0 +1,30 @@
|
||||
# Contributing a Guide
|
||||
|
||||
Want to help teach Gradio? Consider contributing a Guide! 🤗
|
||||
|
||||
Broadly speaking, there are two types of guides:
|
||||
|
||||
* **Use cases**: guides that cover step-by-step how to build a particular type of machine learning demo or app using Gradio. Here's an example: [_Creating a Chatbot_](https://github.com/gradio-app/gradio/blob/master/guides/creating_a_chatbot.md)
|
||||
* **Feature explanation**: guides that describe in detail a particular feature of Gradio. Here's an example: [_Using Flagging_](https://github.com/gradio-app/gradio/blob/master/guides/using_flagging.md)
|
||||
|
||||
We encourage you to submit either type of Guide! (Looking for ideas? We may also have open [issues](https://github.com/gradio-app/gradio/issues?q=is%3Aopen+is%3Aissue+label%3Aguides) where users have asked for guides on particular topics)
|
||||
|
||||
## Guide Structure
|
||||
|
||||
As you can see with the previous examples, Guides are standard markdown documents. They usually:
|
||||
* start with an Introduction section describing the topic
|
||||
* include subheadings to make articles easy to navigate
|
||||
* include real code snippets that make it easy to follow along and implement the Guide
|
||||
* include embedded Gradio demos to make them more interactive and provide immediate demonstrations of the topic being discussed. These Gradio demos are hosted on [Hugging Face Spaces](https://huggingface.co/spaces) and are embedded using the standard \<iframe\> tag.
|
||||
|
||||
|
||||
## How to Contribute a Guide
|
||||
|
||||
1. Clone or fork this `gradio` repo
|
||||
2. Add a new markdown document with a descriptive title to the `/guides` folder
|
||||
3. Write your Guide in standard markdown! Embed Gradio demos wherever helpful
|
||||
4. Add a list of `related_spaces` at the top of the markdown document (see the previously linked Guides for how to do this)
|
||||
5. Add 3 `tags` at the top of the markdown document to help users find your guide (again, see the previously linked Guides for how to do this)
|
||||
6. Open a PR to have your guide reviewed
|
||||
|
||||
That's it! We're looking forward to reading your Guide 🥳
|
||||
BIN
guides/cn/assets/access_token.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 57 KiB |
BIN
guides/cn/assets/annotated.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 397 KiB |
BIN
guides/cn/assets/embed_this_space.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 54 KiB |
BIN
guides/cn/assets/flagging-callback-hf.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 146 KiB |
BIN
guides/cn/assets/hf_demo.mp4
Normal file
BIN
guides/cn/assets/logo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.2 KiB |
BIN
guides/cn/assets/secrets.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
487
guides/cn/assets/sharing.svg
Normal file
{kind=link}
@ -0,0 +1,487 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<svg
|
||||
xmlns:dc="http://purl.org/dc/elements/1.1/"
|
||||
xmlns:cc="http://creativecommons.org/ns#"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:svg="http://www.w3.org/2000/svg"
|
||||
xmlns="http://www.w3.org/2000/svg"
|
||||
xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
|
||||
xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
|
||||
width="551.7179"
|
||||
height="354.22409"
|
||||
overflow="hidden"
|
||||
version="1.1"
|
||||
id="svg145"
|
||||
sodipodi:docname="sharing.svg"
|
||||
style="overflow:hidden"
|
||||
inkscape:version="0.92.4 (5da689c313, 2019-01-14)">
|
||||
<metadata
|
||||
id="metadata149">
|
||||
<rdf:RDF>
|
||||
<cc:Work
|
||||
rdf:about="">
|
||||
<dc:format>image/svg+xml</dc:format>
|
||||
<dc:type
|
||||
rdf:resource="http://purl.org/dc/dcmitype/StillImage" />
|
||||
</cc:Work>
|
||||
</rdf:RDF>
|
||||
</metadata>
|
||||
<sodipodi:namedview
|
||||
pagecolor="#ffffff"
|
||||
bordercolor="#666666"
|
||||
borderopacity="1"
|
||||
objecttolerance="10"
|
||||
gridtolerance="10"
|
||||
guidetolerance="10"
|
||||
inkscape:pageopacity="0"
|
||||
inkscape:pageshadow="2"
|
||||
inkscape:window-width="1920"
|
||||
inkscape:window-height="1106"
|
||||
id="namedview147"
|
||||
showgrid="false"
|
||||
inkscape:zoom="1.9348081"
|
||||
inkscape:cx="152.75133"
|
||||
inkscape:cy="163.92568"
|
||||
inkscape:window-x="-11"
|
||||
inkscape:window-y="-11"
|
||||
inkscape:window-maximized="1"
|
||||
inkscape:current-layer="g143" />
|
||||
<defs
|
||||
id="defs59">
|
||||
<clipPath
|
||||
id="clip0">
|
||||
<path
|
||||
d="M 281,166 H 831 V 511 H 281 Z"
|
||||
id="path2"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip1">
|
||||
<path
|
||||
d="M 688,166 H 830 V 308 H 688 Z"
|
||||
id="path5"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip2">
|
||||
<path
|
||||
d="M 688,166 H 830 V 308 H 688 Z"
|
||||
id="path8"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip3">
|
||||
<path
|
||||
d="M 688,166 H 830 V 308 H 688 Z"
|
||||
id="path11"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip4">
|
||||
<path
|
||||
d="m 711,411 h 99 v 99 h -99 z"
|
||||
id="path14"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip5">
|
||||
<path
|
||||
d="m 711,411 h 99 v 99 h -99 z"
|
||||
id="path17"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip6">
|
||||
<path
|
||||
d="m 711,411 h 99 v 99 h -99 z"
|
||||
id="path20"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip7">
|
||||
<path
|
||||
d="M 282,247 H 473 V 439 H 282 Z"
|
||||
id="path23"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip8">
|
||||
<path
|
||||
d="M 282,247 H 473 V 439 H 282 Z"
|
||||
id="path26"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip9">
|
||||
<path
|
||||
d="M 282,247 H 473 V 439 H 282 Z"
|
||||
id="path29"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip10">
|
||||
<path
|
||||
d="m 715,210 h 38 v 38 h -38 z"
|
||||
id="path32"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip11">
|
||||
<path
|
||||
d="m 715,210 h 38 v 38 h -38 z"
|
||||
id="path35"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip12">
|
||||
<path
|
||||
d="m 715,210 h 38 v 38 h -38 z"
|
||||
id="path38"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip13">
|
||||
<path
|
||||
d="m 747,438 h 24 v 25 h -24 z"
|
||||
id="path41"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip14">
|
||||
<path
|
||||
d="m 747,438 h 24 v 25 h -24 z"
|
||||
id="path44"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip15">
|
||||
<path
|
||||
d="m 747,438 h 24 v 25 h -24 z"
|
||||
id="path47"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip16">
|
||||
<path
|
||||
d="m 308,293 h 76 v 77 h -76 z"
|
||||
id="path50"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip17">
|
||||
<path
|
||||
d="m 308,293 h 76 v 77 h -76 z"
|
||||
id="path53"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
<clipPath
|
||||
id="clip18">
|
||||
<path
|
||||
d="m 308,293 h 76 v 77 h -76 z"
|
||||
id="path56"
|
||||
inkscape:connector-curvature="0"
|
||||
style="clip-rule:evenodd;fill-rule:evenodd" />
|
||||
</clipPath>
|
||||
</defs>
|
||||
<g
|
||||
clip-path="url(#clip0)"
|
||||
transform="translate(-301.97917,-190.708)"
|
||||
id="g143">
|
||||
<rect
|
||||
x="762"
|
||||
y="479"
|
||||
width="30"
|
||||
height="21"
|
||||
id="rect61"
|
||||
style="fill:#e6e6e6" />
|
||||
<g
|
||||
clip-path="url(#clip1)"
|
||||
id="g69"
|
||||
style="fill:#e6e6e6"
|
||||
transform="translate(16,4)">
|
||||
<g
|
||||
clip-path="url(#clip2)"
|
||||
id="g67"
|
||||
style="fill:#e6e6e6">
|
||||
<g
|
||||
clip-path="url(#clip3)"
|
||||
id="g65"
|
||||
style="fill:#e6e6e6">
|
||||
<path
|
||||
d="M 809.292,260.667 H 708.708 v -65.084 h 100.584 z m 2.958,-73.959 h -106.5 c -3.254,0 -5.917,2.663 -5.917,5.917 v 71 c 0,3.254 2.663,5.917 5.917,5.917 h 41.417 v 8.875 h -14.792 v 8.875 h 53.25 v -8.875 h -14.792 v -8.875 h 41.417 c 3.254,0 5.917,-2.663 5.917,-5.917 v -71 c 0,-3.254 -2.663,-5.917 -5.917,-5.917 z"
|
||||
id="path63"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
<rect
|
||||
x="729"
|
||||
y="205"
|
||||
width="42"
|
||||
height="56"
|
||||
id="rect71"
|
||||
style="fill:#e6e6e6" />
|
||||
<g
|
||||
clip-path="url(#clip4)"
|
||||
id="g79"
|
||||
style="fill:#e6e6e6"
|
||||
transform="translate(16,4)">
|
||||
<g
|
||||
clip-path="url(#clip5)"
|
||||
id="g77"
|
||||
style="fill:#e6e6e6">
|
||||
<g
|
||||
clip-path="url(#clip6)"
|
||||
id="g75"
|
||||
style="fill:#e6e6e6">
|
||||
<path
|
||||
d="m 779.063,493.5 h -37.125 v -66 h 37.125 z m -22.688,-74.25 h 8.25 c 1.134,0 2.063,0.928 2.063,2.063 0,1.134 -0.929,2.062 -2.063,2.062 h -8.25 c -1.134,0 -2.062,-0.928 -2.062,-2.062 0,-1.135 0.928,-2.063 2.062,-2.063 z m 26.813,-4.125 h -45.375 c -1.135,0 -2.063,0.928 -2.063,2.063 v 86.625 c 0,1.134 0.928,2.062 2.063,2.062 h 45.375 c 1.134,0 2.062,-0.928 2.062,-2.062 v -86.625 c 0,-1.135 -0.928,-2.063 -2.062,-2.063 z"
|
||||
id="path73"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
<g
|
||||
clip-path="url(#clip7)"
|
||||
id="g89"
|
||||
style="fill:#e6e6e6"
|
||||
transform="translate(16,4)">
|
||||
<g
|
||||
clip-path="url(#clip8)"
|
||||
id="g87"
|
||||
style="fill:#e6e6e6">
|
||||
<g
|
||||
clip-path="url(#clip9)"
|
||||
id="g85"
|
||||
style="fill:#e6e6e6">
|
||||
<path
|
||||
d="M 111.417,115.396 H 15.9167 V 51.7292 h 95.5003 z m 3.979,-75.6043 H 11.9375 c -4.37708,0 -7.95833,3.5812 -7.95833,7.9583 v 71.625 c 0,4.377 3.58125,7.958 7.95833,7.958 h 39.7917 v 11.938 H 33.8229 v 11.937 H 93.5104 V 139.271 H 75.6042 v -11.938 h 39.7918 c 4.377,0 7.958,-3.581 7.958,-7.958 V 47.75 c 0,-4.3771 -3.581,-7.9583 -7.958,-7.9583 z"
|
||||
transform="matrix(1,0,0,1.00524,282,247)"
|
||||
id="path81"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
<path
|
||||
d="M 179.063,59.6875 H 139.271 V 47.75 h 39.792 z m 0,19.8958 H 139.271 V 67.6458 h 39.792 z m -19.896,59.6877 c -3.383,0 -5.969,-2.587 -5.969,-5.969 0,-3.382 2.586,-5.969 5.969,-5.969 3.382,0 5.968,2.587 5.968,5.969 0,3.382 -2.586,5.969 -5.968,5.969 z m 19.896,-99.4793 h -39.792 c -4.377,0 -7.958,3.5812 -7.958,7.9583 v 95.5 c 0,4.377 3.581,7.958 7.958,7.958 h 39.792 c 4.377,0 7.958,-3.581 7.958,-7.958 v -95.5 c 0,-4.3771 -3.581,-7.9583 -7.958,-7.9583 z"
|
||||
transform="matrix(1,0,0,1.00524,282,247)"
|
||||
id="path83"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
<path
|
||||
d="M 427,343 V 330.812 C 427,315.452 439.452,303 454.812,303 h 7.063 c 15.361,0 27.812,12.452 27.812,27.812 v 0 H 495 L 485,343 475,330.812 h 5.313 v 0 c 0,-10.183 -8.255,-18.437 -18.438,-18.437 h -7.063 c -10.183,0 -18.437,8.254 -18.437,18.437 V 343 Z"
|
||||
id="path91"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31;fill-rule:evenodd" />
|
||||
<path
|
||||
d="m 489,351 v 12.188 C 489,378.548 476.548,391 461.188,391 h -6.063 c -15.361,0 -27.812,-12.452 -27.812,-27.812 v 0 H 422 L 432,351 l 10,12.188 h -5.313 v 0 c 0,10.183 8.255,18.437 18.438,18.437 h 6.063 c 10.183,0 18.437,-8.254 18.437,-18.437 V 351 Z"
|
||||
id="path93"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31;fill-rule:evenodd" />
|
||||
<path
|
||||
d="M 692,222.00001 475.2499,222 c -12.5644,0 -22.74989,10.1855 -22.74989,22.75 v 16.2499 H 446 L 459,274 472,260.9999 h -6.5 V 244.75 c 0,-5.3847 4.3652,-9.7499 9.7499,-9.7499 l 216.7501,1e-5 z"
|
||||
id="path95"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31;fill-rule:evenodd" />
|
||||
<path
|
||||
d="m 454,422 v 20.5625 c 0,11.3564 9.20613,20.5625 20.5625,20.5625 H 715.25 V 469 L 727,457.25 715.25,445.5 v 5.875 H 474.5625 c -4.867,0 -8.8125,-3.9455 -8.8125,-8.8125 V 422 Z"
|
||||
id="path97"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31;fill-rule:evenodd" />
|
||||
<path
|
||||
d="m 783,405 v -21.4374 c 0,-11.8396 -9.59784,-21.43741 -21.4374,-21.43741 L 517.25,362.12487 v -6.12489 l -12.25,12.2501 12.25,12.2501 v -6.1252 l 244.3126,2e-5 c 5.0742,0 9.1876,4.1134 9.1876,9.1876 L 770.7499,405 Z"
|
||||
id="path99"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31;fill-rule:evenodd" />
|
||||
<path
|
||||
d="M 508,346.00001 757.1249,346 c 11.1147,0 20.12488,-9.01022 20.12488,-20.1249 l 3e-4,-14.3753 H 783 L 771.4999,300 760,311.4998 h 5.7499 v 14.3753 c 0,4.7635 -3.8615,8.625 -8.625,8.625 L 508,334.49981 Z"
|
||||
id="path101"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31;fill-rule:evenodd" />
|
||||
<g
|
||||
clip-path="url(#clip10)"
|
||||
id="g111"
|
||||
transform="translate(16,4)">
|
||||
<g
|
||||
clip-path="url(#clip11)"
|
||||
id="g109">
|
||||
<g
|
||||
clip-path="url(#clip12)"
|
||||
id="g107">
|
||||
<path
|
||||
d="m 725.988,240.479 c 0,0.656 0.532,1.188 1.188,1.188 0.656,0 1.187,-0.532 1.187,-1.188 v -8.312 h -2.375 z"
|
||||
id="path103"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31" />
|
||||
<path
|
||||
d="m 716.944,232.764 c -0.396,-0.003 -0.737,0.277 -0.812,0.665 -0.07,0.432 0.223,0.839 0.655,0.909 0.045,0.007 0.091,0.01 0.137,0.01 h 1.104 c 1.71,-0.123 3.167,-1.374 3.167,-2.977 v -2.676 c 0.002,-1.068 0.69,-2.013 1.706,-2.343 -0.352,0.447 -0.615,0.958 -0.776,1.504 -0.071,0.243 -0.103,0.495 -0.095,0.748 v 11.836 c -0.01,0.581 0.385,1.091 0.95,1.227 0.643,0.131 1.27,-0.284 1.401,-0.926 0.015,-0.073 0.023,-0.148 0.024,-0.222 v -9.144 h 4.164 c 2.165,4.279 6.71,3.764 8.899,3.832 h 0.197 v 5.185 c -0.012,0.645 0.468,1.193 1.109,1.267 0.666,0.033 1.232,-0.481 1.265,-1.147 10e-4,-0.013 10e-4,-0.027 10e-4,-0.041 v -5.343 h 1.584 v 5.304 c -0.011,0.581 0.384,1.091 0.95,1.227 0.642,0.131 1.27,-0.284 1.401,-0.926 0.015,-0.073 0.023,-0.148 0.024,-0.222 v -8.016 c 0.409,0.307 0.671,0.77 0.724,1.279 v 0 c 0.059,-0.075 0.123,-0.147 0.19,-0.222 0.067,-0.075 0.131,-0.146 0.194,-0.222 0.32,-0.369 0.479,-0.85 0.443,-1.338 -0.059,-0.791 -0.071,-1.543 -0.071,-1.543 0.485,0.214 0.825,0.663 0.899,1.187 v 0 c 0.129,-0.265 0.234,-0.542 0.312,-0.827 0.182,-0.724 0.167,-2.043 0.285,-2.854 0.006,-0.256 0.217,-0.459 0.473,-0.454 0.013,0.001 0.025,0.001 0.038,0.003 l 2.375,0.324 c 0.437,-0.003 0.789,-0.36 0.786,-0.797 0,-0.061 -0.008,-0.121 -0.022,-0.18 l -0.206,-0.792 0.226,0.063 c 0.289,0.08 0.594,-0.058 0.724,-0.328 l 0.487,-1.014 c 0.132,-0.271 0.062,-0.598 -0.17,-0.791 -0.538,-0.451 -1.457,-1.231 -1.457,-1.251 0.238,-0.994 -0.898,-1.674 -0.898,-1.674 0.376,-0.398 0.559,-0.94 0.502,-1.485 -0.038,-1.127 -0.843,-2.082 -1.947,-2.311 v 1.44 c -0.823,-1.294 -2.803,-2.573 -6.452,-2.323 -0.736,0.023 -1.466,0.131 -2.177,0.32 0,0 0,0 0,0 0.844,0.293 1.596,0.805 2.177,1.485 0,0 -2.161,-0.356 -3.258,1.358 -1.096,1.713 -3.456,2.042 -3.665,2.066 0,0 0,0 0,0 0.374,0.387 0.833,0.681 1.341,0.859 0.358,0.066 0.719,0.114 1.081,0.142 -1.583,1.243 -3.958,0.962 -4.164,0.934 0,0 0,0 0,0 0.341,0.389 0.707,0.756 1.096,1.097 h -7.877 -2.339 c -2.236,0.002 -4.049,1.813 -4.053,4.049 v 2.482 c 0,0.875 -0.709,1.583 -1.584,1.583 z"
|
||||
id="path105"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
<rect
|
||||
x="777"
|
||||
y="205"
|
||||
width="44"
|
||||
height="56"
|
||||
id="rect113"
|
||||
style="fill:#e6e6e6" />
|
||||
<rect
|
||||
x="762"
|
||||
y="435"
|
||||
width="30"
|
||||
height="39"
|
||||
id="rect115"
|
||||
style="fill:#e6e6e6" />
|
||||
<g
|
||||
clip-path="url(#clip13)"
|
||||
id="g125"
|
||||
transform="translate(16,4)">
|
||||
<g
|
||||
clip-path="url(#clip14)"
|
||||
id="g123">
|
||||
<g
|
||||
clip-path="url(#clip15)"
|
||||
id="g121">
|
||||
<path
|
||||
d="m 6.94,19.25 c 0,0.4142 0.33577,0.75 0.75,0.75 0.41423,0 0.75,-0.3358 0.75,-0.75 V 14 h -1.5 z"
|
||||
transform="matrix(1,0,0,1.04167,747,438)"
|
||||
id="path117"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31" />
|
||||
<path
|
||||
d="m 1.2275,14.3775 c -0.249818,-0.002 -0.46544,0.1746 -0.5125,0.42 -0.044205,0.2726 0.14093,0.5294 0.41351,0.5736 0.02859,0.0046 0.05753,0.0068 0.08649,0.0064 h 0.6975 c 1.08,-0.0775 2,-0.8675 2,-1.88 v -1.69 C 3.91403,11.1331 4.3487,10.5361 4.99,10.3275 4.76775,10.6101 4.60145,10.9326 4.5,11.2775 4.45522,11.4309 4.43495,11.5903 4.44,11.75 v 7.475 C 4.4334,19.5921 4.68295,19.9144 5.04,20 5.44583,20.0829 5.84202,19.8211 5.9249,19.4152 5.93433,19.3691 5.93937,19.3221 5.94,19.275 V 13.5 h 2.63 c 1.3675,2.7025 4.2375,2.3775 5.62,2.42 h 0.125 v 3.275 c -0.0078,0.4072 0.2953,0.7537 0.7,0.8 0.4206,0.0208 0.7784,-0.3034 0.7991,-0.724 5e-4,-0.0086 8e-4,-0.0173 9e-4,-0.026 V 15.87 h 1 v 3.35 c -0.0066,0.3671 0.2429,0.6894 0.6,0.775 0.4059,0.0829 0.802,-0.1789 0.8849,-0.5848 0.0094,-0.0461 0.0145,-0.0931 0.0151,-0.1402 v -5.0625 c 0.2582,0.1938 0.424,0.4864 0.4575,0.8075 v 0 c 0.0375,-0.0475 0.0775,-0.0925 0.12,-0.14 0.0425,-0.0475 0.0825,-0.0925 0.1225,-0.14 0.2017,-0.2334 0.3025,-0.5374 0.28,-0.845 -0.0375,-0.5 -0.045,-0.975 -0.045,-0.975 0.3061,0.135 0.5208,0.4187 0.5675,0.75 v 0 c 0.082,-0.1677 0.148,-0.3426 0.1975,-0.5225 0.115,-0.4575 0.105,-1.29 0.18,-1.8025 0.0033,-0.1615 0.1369,-0.2898 0.2984,-0.2865 0.008,2e-4 0.0161,7e-4 0.0241,0.0015 l 1.5,0.205 c 0.2761,-0.0019 0.4984,-0.2274 0.4965,-0.5035 -3e-4,-0.0384 -0.005,-0.0767 -0.014,-0.114 l -0.13,-0.5 0.1425,0.04 c 0.1826,0.0502 0.375,-0.037 0.4575,-0.2075 l 0.3075,-0.64 C 23.3608,9.16343 23.3165,8.95715 23.17,8.835 22.83,8.55 22.25,8.0575 22.25,8.045 22.4,7.4175 21.6825,6.9875 21.6825,6.9875 21.92,6.73628 22.036,6.39385 22,6.05 21.9757,5.33795 21.4676,4.73485 20.77,4.59 V 5.5 C 20.25,4.6825 19,3.875 16.695,4.0325 16.2304,4.04715 15.7691,4.1151 15.32,4.235 c 0,0 0,0 0,0 0.5335,0.1848 1.0081,0.5084 1.375,0.9375 0,0 -1.365,-0.225 -2.0575,0.8575 -0.6925,1.0825 -2.1825,1.29 -2.315,1.305 0,0 0,0 0,0 0.2365,0.2443 0.5266,0.43008 0.8475,0.5425 0.2258,0.04203 0.4536,0.07207 0.6825,0.09 -1,0.785 -2.5,0.6075 -2.63,0.59 0,0 0,0 0,0 0.2155,0.2457 0.4468,0.47702 0.6925,0.6925 H 6.94 5.4625 c -1.4123,0.00138 -2.55725,1.1452 -2.56,2.5575 v 1.5675 c 0,0.5523 -0.44771,1 -1,1 z"
|
||||
transform="matrix(1,0,0,1.04167,747,438)"
|
||||
id="path119"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#ed7d31" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
<rect
|
||||
x="780"
|
||||
y="237"
|
||||
width="25"
|
||||
height="9"
|
||||
id="rect127"
|
||||
style="fill:#7f7f7f" />
|
||||
<rect
|
||||
x="780"
|
||||
y="249"
|
||||
width="17"
|
||||
height="9"
|
||||
id="rect129"
|
||||
style="fill:#7f7f7f" />
|
||||
<g
|
||||
clip-path="url(#clip16)"
|
||||
id="g141"
|
||||
style="fill:#e6e6e6"
|
||||
transform="translate(16,4)">
|
||||
<g
|
||||
clip-path="url(#clip17)"
|
||||
id="g139"
|
||||
style="fill:#e6e6e6">
|
||||
<g
|
||||
clip-path="url(#clip18)"
|
||||
id="g137"
|
||||
style="fill:#e6e6e6">
|
||||
<path
|
||||
d="m 19.7125,49.7958 -2.2167,-2.2166 6.8084,-6.8084 -6.8084,-6.8083 2.2167,-2.2167 9.025,9.025 z"
|
||||
transform="matrix(1,0,0,1.01316,308,293)"
|
||||
id="path131"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
<path
|
||||
d="M 6.33333,13.4583 V 62.5417 H 69.6667 V 13.4583 Z m 54.62497,4.75 c 0.8709,0 1.5834,0.7125 1.5834,1.5834 0,0.8708 -0.7125,1.5833 -1.5834,1.5833 -0.8708,0 -1.5833,-0.7125 -1.5833,-1.5833 0,-0.8709 0.7125,-1.5834 1.5833,-1.5834 z m -5.5416,0 c 0.8708,0 1.5833,0.7125 1.5833,1.5834 0,0.8708 -0.7125,1.5833 -1.5833,1.5833 -0.8709,0 -1.5834,-0.7125 -1.5834,-1.5833 0,-0.8709 0.7125,-1.5834 1.5834,-1.5834 z m -5.5417,0 c 0.8708,0 1.5833,0.7125 1.5833,1.5834 0,0.8708 -0.7125,1.5833 -1.5833,1.5833 -0.8708,0 -1.5833,-0.7125 -1.5833,-1.5833 0,-0.8709 0.7125,-1.5834 1.5833,-1.5834 z M 64.9167,57.7917 H 11.0833 V 26.125 h 53.8334 z"
|
||||
transform="matrix(1,0,0,1.01316,308,293)"
|
||||
id="path133"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
<path
|
||||
d="M 30.0833,46.7083 H 42.75 V 49.875 H 30.0833 Z"
|
||||
transform="matrix(1,0,0,1.01316,308,293)"
|
||||
id="path135"
|
||||
inkscape:connector-curvature="0"
|
||||
style="fill:#e6e6e6" />
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
</g>
|
||||
<text
|
||||
xml:space="preserve"
|
||||
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:24px;line-height:1.25;font-family:Marlett;-inkscape-font-specification:Marlett;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none"
|
||||
x="466.40768"
|
||||
y="26.722836"
|
||||
id="text153"><tspan
|
||||
sodipodi:role="line"
|
||||
id="tspan151"
|
||||
x="466.40768"
|
||||
y="53.722836" /></text>
|
||||
<text
|
||||
xml:space="preserve"
|
||||
style="font-style:normal;font-variant:normal;font-weight:bold;font-stretch:normal;font-size:17.05692863px;line-height:1.25;font-family:Arial;-inkscape-font-specification:'Arial Bold';letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:1"
|
||||
x="480.38916"
|
||||
y="34.031235"
|
||||
id="text157"><tspan
|
||||
sodipodi:role="line"
|
||||
id="tspan155"
|
||||
x="480.38916"
|
||||
y="34.031235"
|
||||
style="font-style:normal;font-variant:normal;font-weight:bold;font-stretch:normal;font-family:Arial;-inkscape-font-specification:'Arial Bold';stroke-width:1.40705287">lion</tspan></text>
|
||||
<text
|
||||
xml:space="preserve"
|
||||
style="font-style:normal;font-variant:normal;font-weight:bold;font-stretch:normal;font-size:13.5049057px;line-height:1.25;font-family:Arial;-inkscape-font-specification:'Arial Bold';letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:1"
|
||||
x="463.01477"
|
||||
y="302.10855"
|
||||
id="text157-3"><tspan
|
||||
sodipodi:role="line"
|
||||
id="tspan155-5"
|
||||
x="463.01477"
|
||||
y="302.10855"
|
||||
style="font-style:normal;font-variant:normal;font-weight:bold;font-stretch:normal;font-family:Arial;-inkscape-font-specification:'Arial Bold';stroke-width:1.40705287">lion</tspan></text>
|
||||
<text
|
||||
xml:space="preserve"
|
||||
style="font-style:normal;font-variant:normal;font-weight:900;font-stretch:normal;font-size:17.25738335px;line-height:1.25;font-family:Arial;-inkscape-font-specification:'Arial Heavy';letter-spacing:0px;word-spacing:0px;fill:#999999;fill-opacity:1;stroke:none;stroke-width:0.99999994"
|
||||
x="46.146866"
|
||||
y="352.89612"
|
||||
id="text179"><tspan
|
||||
sodipodi:role="line"
|
||||
id="tspan177"
|
||||
x="46.146866"
|
||||
y="352.89612"
|
||||
style="stroke-width:0.99999994">HOST</tspan></text>
|
||||
<text
|
||||
xml:space="preserve"
|
||||
style="font-style:normal;font-variant:normal;font-weight:900;font-stretch:normal;font-size:18.18510628px;line-height:1.25;font-family:Arial;-inkscape-font-specification:'Arial Heavy';letter-spacing:0px;word-spacing:0px;fill:#999999;fill-opacity:1;stroke:none;stroke-width:0.99999994"
|
||||
x="392.19867"
|
||||
y="353.99323"
|
||||
id="text179-9"><tspan
|
||||
sodipodi:role="line"
|
||||
id="tspan177-4"
|
||||
x="392.19867"
|
||||
y="353.99323"
|
||||
style="stroke-width:0.99999994">REMOTE USERS</tspan></text>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 22 KiB |
BIN
guides/cn/assets/use_via_api.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
@ -8,7 +8,7 @@ DIR = os.path.dirname(__file__)
|
||||
GUIDES_DIR = os.path.abspath(os.path.join(DIR, "../../../../../guides"))
|
||||
GUIDE_ASSETS_DIR = os.path.join(GUIDES_DIR, "assets")
|
||||
DEMOS_DIR = os.path.abspath(os.path.join(DIR, "../../../../../demo"))
|
||||
|
||||
CN_GUIDES_DIR = os.path.abspath(os.path.join(DIR, "../../../../../guides/cn"))
|
||||
|
||||
UNDERSCORE_TOKEN = "!UNDERSCORE!"
|
||||
|
||||
@ -37,6 +37,7 @@ def format_name(guide_name):
|
||||
guide_folders = sorted(os.listdir(GUIDES_DIR))
|
||||
guide_folders.remove("CONTRIBUTING.md")
|
||||
guide_folders.remove("assets")
|
||||
guide_folders.remove("cn")
|
||||
|
||||
guides = []
|
||||
guides_by_category = []
|
||||
|
||||
@ -1 +1 @@
|
||||
{"version": "3.37.0"}
|
||||
{"version": "3.38.0"}
|
||||