mirror of
https://github.com/gradio-app/gradio.git
synced 2024-11-27 01:40:20 +08:00
Add conversational and text-to-image pipelines to Interface.load (#3011)
* Add conversational and text-to-image * remove redundant state * CHANGELOG * Add media to changelog * Lint * Format code * Fix typos in CHANGELOG
This commit is contained in:
parent
f7f5398e4c
commit
32af45cd0f
26
CHANGELOG.md
26
CHANGELOG.md
@ -1,7 +1,31 @@
|
||||
# Upcoming Release
|
||||
|
||||
## New Features:
|
||||
No changes to highlight.
|
||||
|
||||
### Extended support for Interface.load! 🏗️
|
||||
|
||||
You can now load `image-to-text` and `conversational` pipelines from the hub!
|
||||
|
||||
### Image-to-text Demo
|
||||
```python
|
||||
io = gr.Interface.load("models/nlpconnect/vit-gpt2-image-captioning",
|
||||
api_key="<optional-api-key>")
|
||||
io.launch()
|
||||
```
|
||||
<img width="1087" alt="image" src="https://user-images.githubusercontent.com/41651716/213260197-dc5d80b4-6e50-4b3a-a764-94980930ac38.png">
|
||||
|
||||
|
||||
|
||||
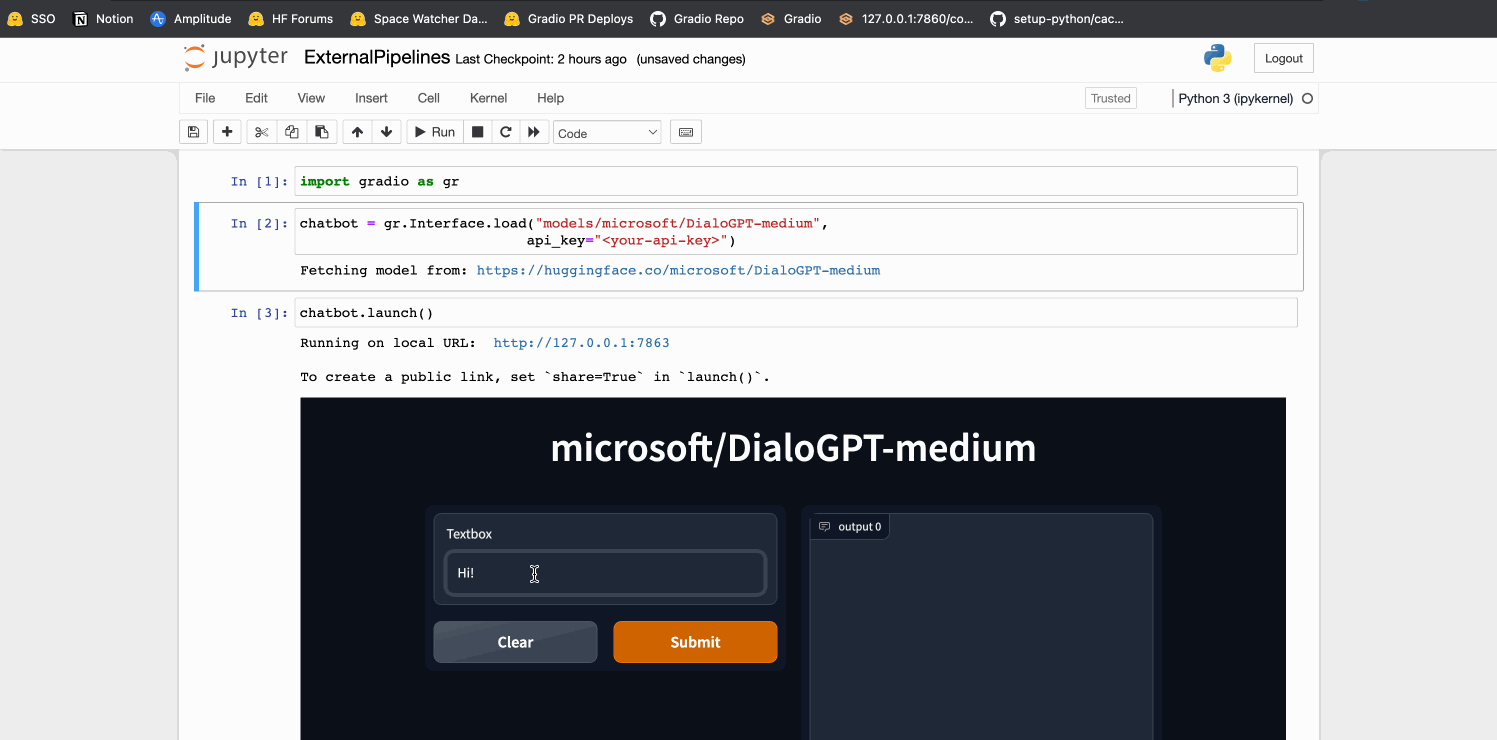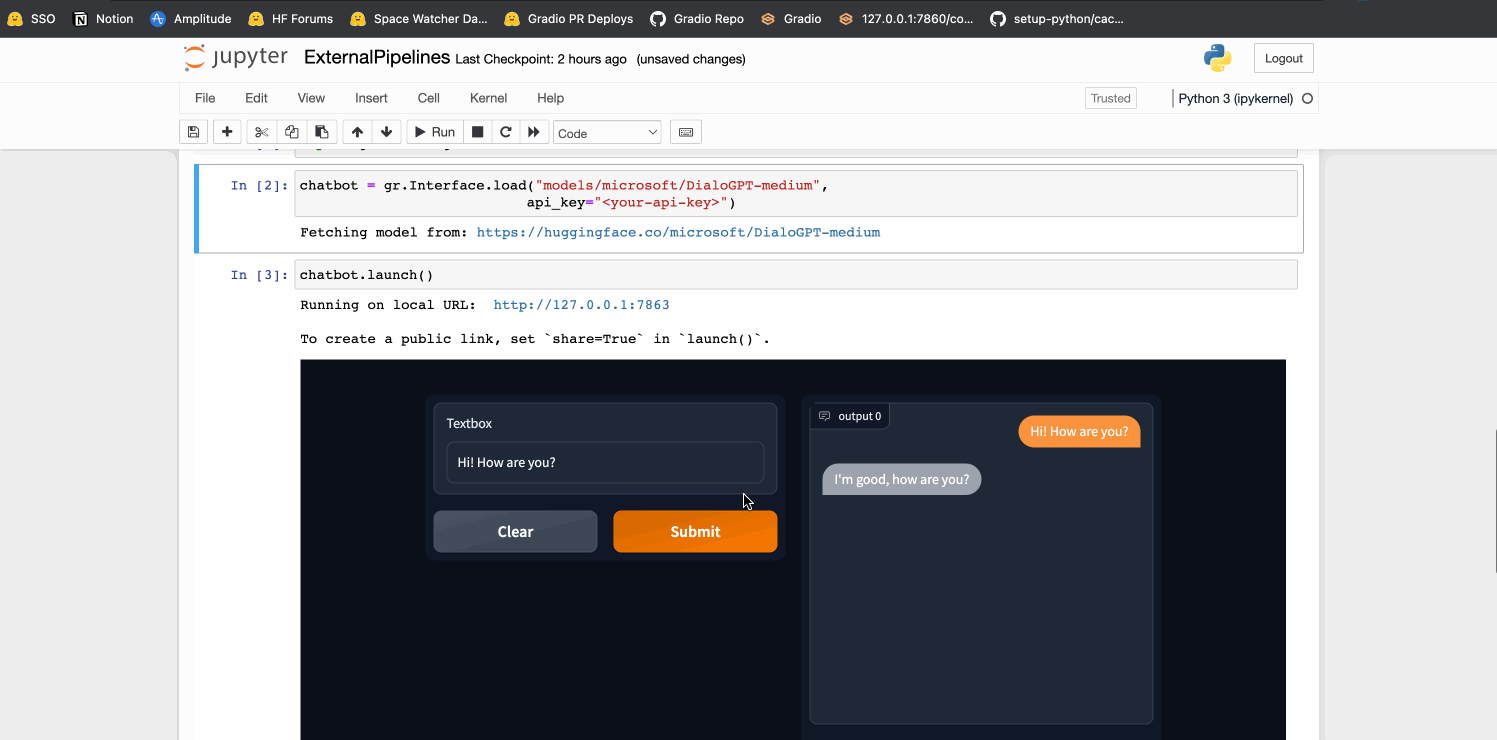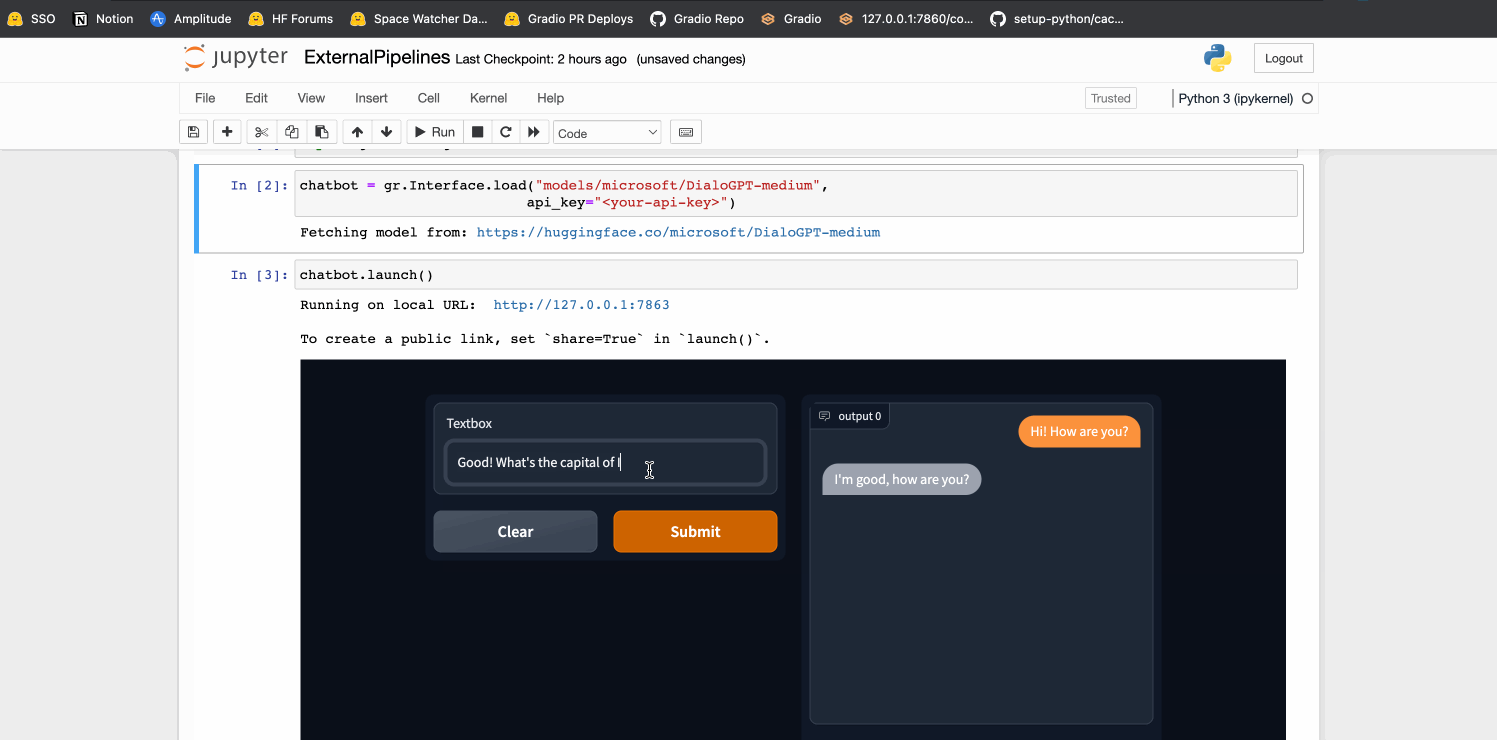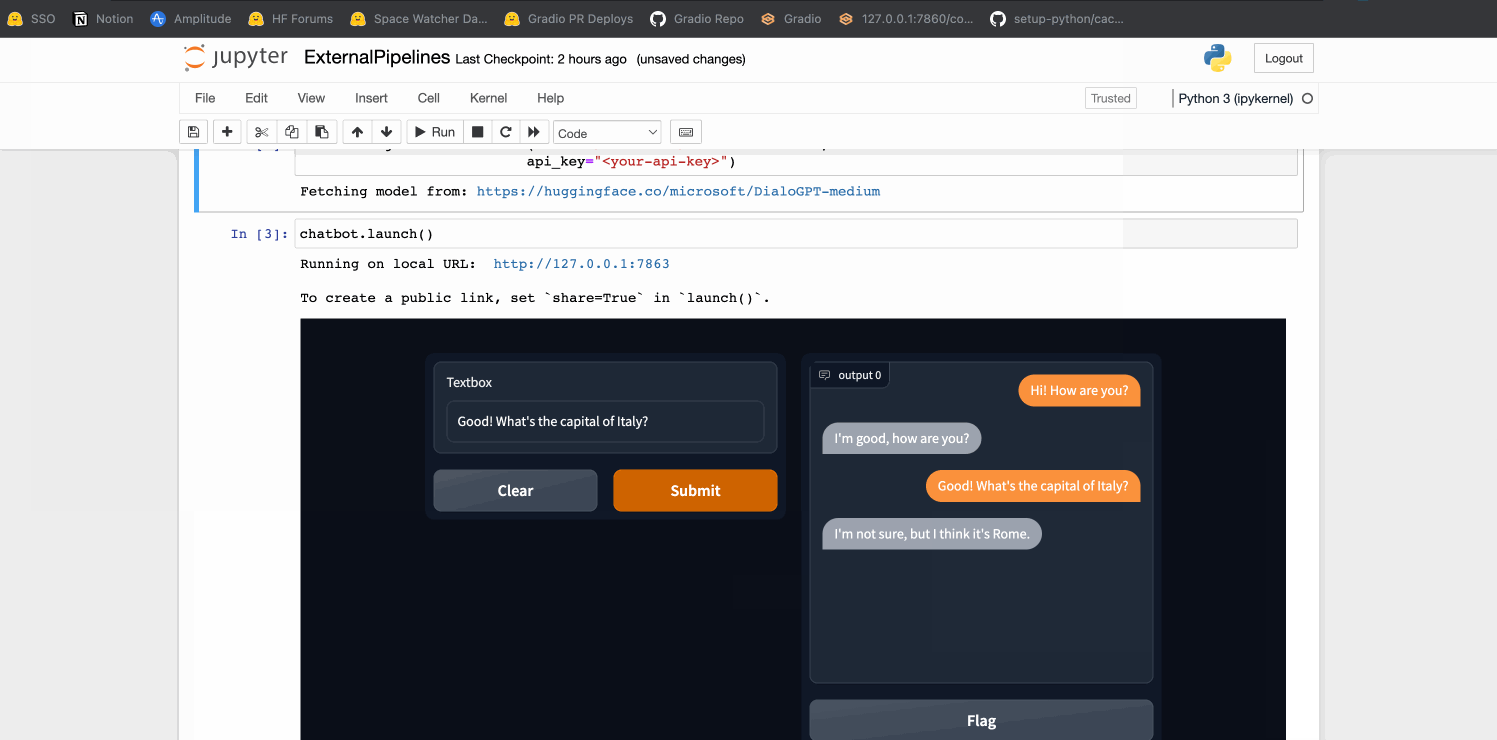
### conversational Demo
|
||||
```python
|
||||
chatbot = gr.Interface.load("models/microsoft/DialoGPT-medium",
|
||||
api_key="<optional-api-key>")
|
||||
chatbot.launch()
|
||||
```
|
||||
|
||||
|
||||
|
||||
By [@freddyaboulton](https://github.com/freddyaboulton) in [PR 3011](https://github.com/gradio-app/gradio/pull/3011)
|
||||
|
||||
## Bug Fixes:
|
||||
* Fixes bug where interpretation event was not configured correctly by [@freddyaboulton](https://github.com/freddyaboulton) in [PR 2993](https://github.com/gradio-app/gradio/pull/2993)
|
||||
|
||||
@ -63,6 +63,32 @@ def load_blocks_from_repo(
|
||||
return blocks
|
||||
|
||||
|
||||
def chatbot_preprocess(text, state):
|
||||
payload = {
|
||||
"inputs": {"generated_responses": None, "past_user_inputs": None, "text": text}
|
||||
}
|
||||
if state is not None:
|
||||
payload["inputs"]["generated_responses"] = state["conversation"][
|
||||
"generated_responses"
|
||||
]
|
||||
payload["inputs"]["past_user_inputs"] = state["conversation"][
|
||||
"past_user_inputs"
|
||||
]
|
||||
|
||||
return payload
|
||||
|
||||
|
||||
def chatbot_postprocess(response):
|
||||
response_json = response.json()
|
||||
chatbot_value = list(
|
||||
zip(
|
||||
response_json["conversation"]["past_user_inputs"],
|
||||
response_json["conversation"]["generated_responses"],
|
||||
)
|
||||
)
|
||||
return chatbot_value, response_json
|
||||
|
||||
|
||||
def from_model(model_name: str, api_key: str | None, alias: str | None, **kwargs):
|
||||
model_url = "https://huggingface.co/{}".format(model_name)
|
||||
api_url = "https://api-inference.huggingface.co/models/{}".format(model_name)
|
||||
@ -76,7 +102,6 @@ def from_model(model_name: str, api_key: str | None, alias: str | None, **kwargs
|
||||
response.status_code == 200
|
||||
), f"Could not find model: {model_name}. If it is a private or gated model, please provide your Hugging Face access token (https://huggingface.co/settings/tokens) as the argument for the `api_key` parameter."
|
||||
p = response.json().get("pipeline_tag")
|
||||
|
||||
pipelines = {
|
||||
"audio-classification": {
|
||||
# example model: ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition
|
||||
@ -101,6 +126,12 @@ def from_model(model_name: str, api_key: str | None, alias: str | None, **kwargs
|
||||
"preprocess": to_binary,
|
||||
"postprocess": lambda r: r.json()["text"],
|
||||
},
|
||||
"conversational": {
|
||||
"inputs": [components.Textbox(), components.State()], # type: ignore
|
||||
"outputs": [components.Chatbot(), components.State()], # type: ignore
|
||||
"preprocess": chatbot_preprocess,
|
||||
"postprocess": chatbot_postprocess,
|
||||
},
|
||||
"feature-extraction": {
|
||||
# example model: julien-c/distilbert-feature-extraction
|
||||
"inputs": components.Textbox(label="Input"),
|
||||
@ -125,6 +156,12 @@ def from_model(model_name: str, api_key: str | None, alias: str | None, **kwargs
|
||||
{i["label"].split(", ")[0]: i["score"] for i in r.json()}
|
||||
),
|
||||
},
|
||||
"image-to-text": {
|
||||
"inputs": components.Image(type="filepath", label="Input Image"),
|
||||
"outputs": components.Textbox(),
|
||||
"preprocess": to_binary,
|
||||
"postprocess": lambda r: r.json()[0]["generated_text"],
|
||||
},
|
||||
"question-answering": {
|
||||
# Example: deepset/xlm-roberta-base-squad2
|
||||
"inputs": [
|
||||
@ -311,7 +348,12 @@ def from_model(model_name: str, api_key: str | None, alias: str | None, **kwargs
|
||||
}
|
||||
|
||||
kwargs = dict(interface_info, **kwargs)
|
||||
kwargs["_api_mode"] = True # So interface doesn't run pre/postprocess.
|
||||
|
||||
# So interface doesn't run pre/postprocess
|
||||
# except for conversational interfaces which
|
||||
# are stateful
|
||||
kwargs["_api_mode"] = p != "conversational"
|
||||
|
||||
interface = gradio.Interface(**kwargs)
|
||||
return interface
|
||||
|
||||
|
||||
@ -228,6 +228,28 @@ class TestLoadInterface:
|
||||
except TooManyRequestsError:
|
||||
pass
|
||||
|
||||
def test_image_to_text(self):
|
||||
io = gr.Interface.load("models/nlpconnect/vit-gpt2-image-captioning")
|
||||
try:
|
||||
output = io("gradio/test_data/lion.jpg")
|
||||
assert isinstance(output, str)
|
||||
except TooManyRequestsError:
|
||||
pass
|
||||
|
||||
def test_conversational(self):
|
||||
io = gr.Interface.load("models/microsoft/DialoGPT-medium")
|
||||
app, _, _ = io.launch(prevent_thread_lock=True)
|
||||
client = TestClient(app)
|
||||
assert app.state_holder == {}
|
||||
response = client.post(
|
||||
"/api/predict/",
|
||||
json={"session_hash": "foo", "data": ["Hi!", None], "fn_index": 0},
|
||||
)
|
||||
output = response.json()
|
||||
assert isinstance(output["data"], list)
|
||||
assert isinstance(output["data"][0], list)
|
||||
assert isinstance(app.state_holder["foo"], dict)
|
||||
|
||||
def test_speech_recognition_model(self):
|
||||
io = gr.Interface.load("models/facebook/wav2vec2-base-960h")
|
||||
try:
|
||||
|
||||
Loading…
Reference in New Issue
Block a user