| data_provider | ||
| data_provider_pretrain | ||
| dataset/prompt_bank | ||
| figures | ||
| layers | ||
| models | ||
| scripts | ||
| utils | ||
| ds_config_zero2.json | ||
| LEGAL.md | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
| run_m4.py | ||
| run_main.py | ||
| run_pretrain.py | ||
(ICLR'24) Time-LLM: Time Series Forecasting by Reprogramming Large Language Models



[Paper Page] [YouTube Talk 1] [YouTube Talk 2] [Medium Blog]
[机器之心中文解读] [量子位中文解读] [时序人中文解读] [AI算法厨房中文解读] [知乎中文解读]
![]()
🙋 Please let us know if you find out a mistake or have any suggestions!
🌟 If you find this resource helpful, please consider to star this repository and cite our research:
@inproceedings{jin2023time,
title={{Time-LLM}: Time series forecasting by reprogramming large language models},
author={Jin, Ming and Wang, Shiyu and Ma, Lintao and Chu, Zhixuan and Zhang, James Y and Shi, Xiaoming and Chen, Pin-Yu and Liang, Yuxuan and Li, Yuan-Fang and Pan, Shirui and Wen, Qingsong},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
Updates
🚩 News (May 2024): Time-LLM has been included in NeuralForecast. Special thanks to the contributor @JQGoh and @marcopeix!
🚩 News (March 2024): Time-LLM has been upgraded to serve as a general framework for repurposing a wide range of language models to time series forecasting. It now defaults to supporting Llama-7B and includes compatibility with two additional smaller PLMs (GPT-2 and BERT). Simply adjust --llm_model and --llm_dim to switch backbones.
Introduction
Time-LLM is a reprogramming framework to repurpose LLMs for general time series forecasting with the backbone language models kept intact. Notably, we show that time series analysis (e.g., forecasting) can be cast as yet another "language task" that can be effectively tackled by an off-the-shelf LLM.
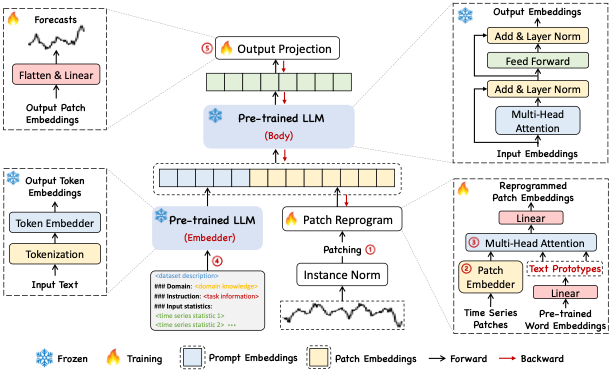
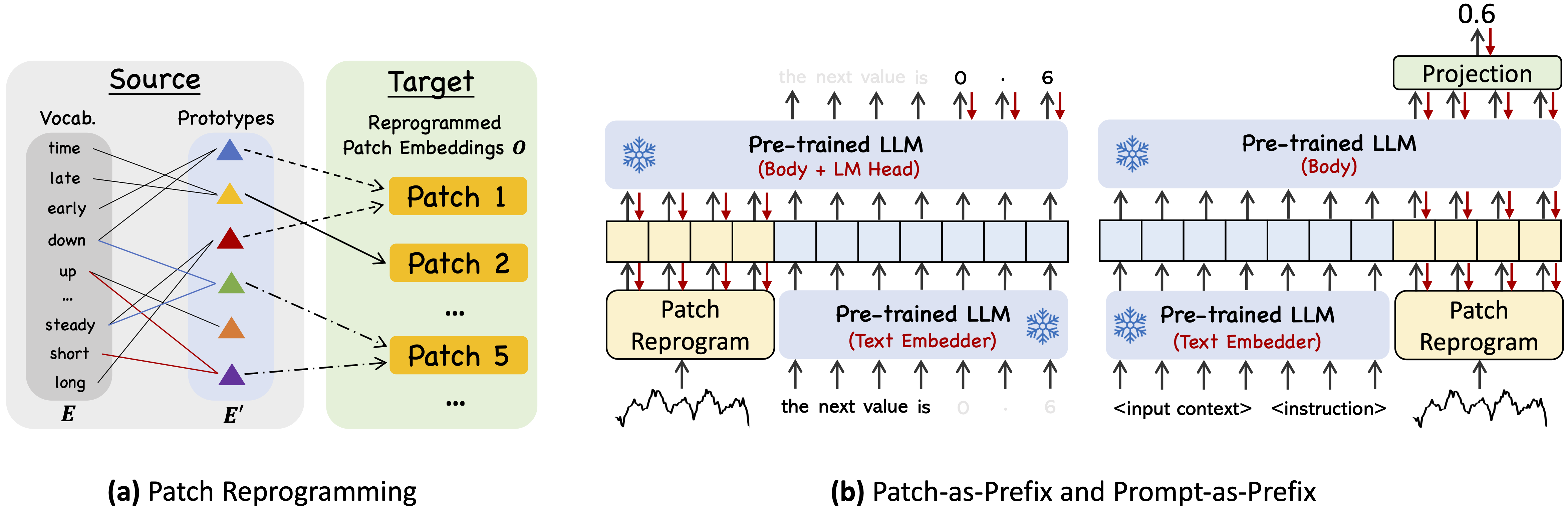
- Time-LLM comprises two key components: (1) reprogramming the input time series into text prototype representations that are more natural for the LLM, and (2) augmenting the input context with declarative prompts (e.g., domain expert knowledge and task instructions) to guide LLM reasoning.
Requirements
Use python 3.11 from MiniConda
- torch==2.2.2
- accelerate==0.28.0
- einops==0.7.0
- matplotlib==3.7.0
- numpy==1.23.5
- pandas==1.5.3
- scikit_learn==1.2.2
- scipy==1.12.0
- tqdm==4.65.0
- peft==0.4.0
- transformers==4.31.0
- deepspeed==0.14.0
- sentencepiece==0.2.0
To install all dependencies:
pip install -r requirements.txt
Datasets
You can access the well pre-processed datasets from [Google Drive], then place the downloaded contents under ./dataset
Quick Demos
- Download datasets and place them under
./dataset - Tune the model. We provide five experiment scripts for demonstration purpose under the folder
./scripts. For example, you can evaluate on ETT datasets by:
bash ./scripts/TimeLLM_ETTh1.sh
bash ./scripts/TimeLLM_ETTh2.sh
bash ./scripts/TimeLLM_ETTm1.sh
bash ./scripts/TimeLLM_ETTm2.sh
Detailed usage
Please refer to run_main.py, run_m4.py and run_pretrain.py for the detailed description of each hyperparameter.
Further Reading
1, Foundation Models for Time Series Analysis: A Tutorial and Survey, in KDD 2024.
Authors: Yuxuan Liang, Haomin Wen, Yuqi Nie, Yushan Jiang, Ming Jin, Dongjin Song, Shirui Pan, Qingsong Wen*
@inproceedings{liang2024foundation,
title={Foundation models for time series analysis: A tutorial and survey},
author={Liang, Yuxuan and Wen, Haomin and Nie, Yuqi and Jiang, Yushan and Jin, Ming and Song, Dongjin and Pan, Shirui and Wen, Qingsong},
booktitle={ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2024)},
year={2024}
}
2, Position Paper: What Can Large Language Models Tell Us about Time Series Analysis, in ICML 2024.
Authors: Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang*, Bin Yang, Jindong Wang, Shirui Pan, Qingsong Wen*
@inproceedings{jin2024position,
title={Position Paper: What Can Large Language Models Tell Us about Time Series Analysis},
author={Ming Jin and Yifan Zhang and Wei Chen and Kexin Zhang and Yuxuan Liang and Bin Yang and Jindong Wang and Shirui Pan and Qingsong Wen},
booktitle={International Conference on Machine Learning (ICML 2024)},
year={2024}
}
3, Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook, in arXiv 2023. [GitHub Repo]
Authors: Ming Jin, Qingsong Wen*, Yuxuan Liang, Chaoli Zhang, Siqiao Xue, Xue Wang, James Zhang, Yi Wang, Haifeng Chen, Xiaoli Li (IEEE Fellow), Shirui Pan*, Vincent S. Tseng (IEEE Fellow), Yu Zheng (IEEE Fellow), Lei Chen (IEEE Fellow), Hui Xiong (IEEE Fellow)
@article{jin2023lm4ts,
title={Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook},
author={Ming Jin and Qingsong Wen and Yuxuan Liang and Chaoli Zhang and Siqiao Xue and Xue Wang and James Zhang and Yi Wang and Haifeng Chen and Xiaoli Li and Shirui Pan and Vincent S. Tseng and Yu Zheng and Lei Chen and Hui Xiong},
journal={arXiv preprint arXiv:2310.10196},
year={2023}
}
4, Transformers in Time Series: A Survey, in IJCAI 2023. [GitHub Repo]
Authors: Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, Liang Sun
@inproceedings{wen2023transformers,
title={Transformers in time series: A survey},
author={Wen, Qingsong and Zhou, Tian and Zhang, Chaoli and Chen, Weiqi and Ma, Ziqing and Yan, Junchi and Sun, Liang},
booktitle={International Joint Conference on Artificial Intelligence(IJCAI)},
year={2023}
}
5, TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting, in ICLR 2024. [GitHub Repo]
Authors: Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y. Zhang, Jun Zhou
@inproceedings{wang2023timemixer,
title={TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting},
author={Wang, Shiyu and Wu, Haixu and Shi, Xiaoming and Hu, Tengge and Luo, Huakun and Ma, Lintao and Zhang, James Y and ZHOU, JUN},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
Acknowledgement
Our implementation adapts Time-Series-Library and OFA (GPT4TS) as the code base and have extensively modified it to our purposes. We thank the authors for sharing their implementations and related resources.