mirror of
https://github.com/postyizhan/NitWikit.git
synced 2025-02-17 16:29:45 +08:00
新增对于乱码的介绍和解决的文章
This commit is contained in:
parent
68cf916e79
commit
416fe16ba6
55
docs/start/basic/what-is-messy-code.md
Normal file
55
docs/start/basic/what-is-messy-code.md
Normal file
@ -0,0 +1,55 @@
|
||||
---
|
||||
title: 什么是乱码?
|
||||
sidebar_position: 7
|
||||
---
|
||||
|
||||
# 什么是乱码?
|
||||
|
||||
有时候,你会发现你的文本文件中的中文都莫名其妙变成了一些奇奇怪怪的符号,看起来乱糟糟的,毫无逻辑可言。
|
||||
这就是**乱码**。
|
||||
|
||||
# 为什么会出现乱码?
|
||||
|
||||
乱码出现的原因,就是不使用原来编写文本的时候的编码来打开这个文本。
|
||||
|
||||
而不同编码确定一个字符的规则不同。
|
||||
|
||||
# 什么是编码?
|
||||
|
||||
编码,也叫**字符编码**。通俗的讲,就是计算机的“字典”。你的文本文件在计算机中并不是以明文存在的,而是以一串二进制数表示的。比如:
|
||||
|
||||
如果你让计算机使用A编码,然后你输入了一个“人”字。那么在你输入后,计算机就会将“人”字转换为A编码中“人”字对应的二进制数。比如这个二进制数是0010011。
|
||||
|
||||
倘若我再次打开的时候使用了B编码,而计算机中存储的二进制数仍然是0010011。那么计算机就会在B编码的字符库中查找这个二进制数对应的字,比如在B编码中,0010011指的是“你”这个字,那么你再次打开这个文本的时候你就会发现“人”字变成了“你”字。
|
||||
|
||||
当然,实际的编码规则远没有这么简单,大家只需要理解为什么会乱码就可以了。
|
||||
|
||||
# 乱码的类型
|
||||
|
||||
这里列出了一个表格方便大家知道自己的文本是怎么乱码的。
|
||||
|
||||
| 名称 | 示例 | 特点 | 产生原因 |
|
||||
|:----------:|:---------:|:---------:|:---------:|
|
||||
| 古文码 | 宀佺殑娉曞浗浜嗗緢涔<E7B7A2> | 大都为不认识的古文,并夹杂日韩文 | 以GBK方式读取UTF-8编码的中文 |
|
||||
| 口字码 | <20><>ķ<EFBFBD><C4B7><EFBFBD><EFBFBD>˺ܾ<CBBA> | 大部分字符为小方块 | 以UTF-8方式读取GBK编码的中文 |
|
||||
| 符号码 | å²çæ³å½äºå¾ä¹
| 大部分字符为各种符号 | 以ISO8859-1方式读取UTF-8编码的中文 |
|
||||
| 拼音码 | ËêµÄ·¨¹úÁ˺ܾà | 大部分字符以头顶带有各种类型声调符号的字母 | 以ISO8859-1方式读取GBK编码的中文 |
|
||||
| 问句码 | 好好学习天天?? | 字符串长度为偶数时正确,长度为奇数时最后的字符变为问号 | 以GBK方式读取UTF-8编码的中文,然后又用UTF-8的格式再次读取 |
|
||||
| 锟拷码 | 锟斤拷锟斤拷锟斤拷锟斤拷锟斤拷 | 全中文字符,且大部分字符为"锟斤拷"这几个字符 | 以UTF-8方式读取GBK编码的中文,然后又用GBK的格式再次读取 |
|
||||
|
||||
|
||||
解决乱码的方式也很简单,只需要根据乱码的特征,进行转码或重新用原来的编码打开就可以了。
|
||||
|
||||
# 如何设置编码、转码
|
||||
|
||||
这里以VScode为例:
|
||||
|
||||
|
||||
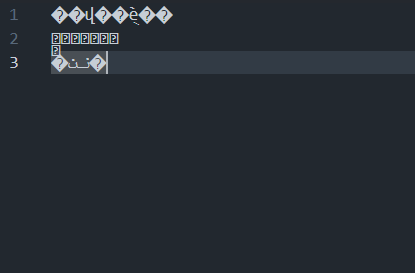
发现这是典型的口字码
|
||||
|
||||
我们看到VScode右下角
|
||||

|
||||
点击**UTF-8**
|
||||
|
||||
然后重新用**GBK**方式打开就可以了
|
||||

|
||||
Loading…
Reference in New Issue
Block a user